🎭 引言:AI也能当”搜索引擎”?
想象一下,你有一个无所不知的AI助手,它不仅能回答各种问题,还能帮你在海量文档中快速找到所需信息。听起来很酷,对吧?但现实中,让AI完成这样的任务并非易事。
友情链接:ACEJoy
目前,利用大语言模型(LLMs)进行”零样本”文档排序主要有两种方式:一是基于提示的重排序方法,无需额外训练但计算成本高,只能对少量候选文档进行重排;二是无监督的对比学习密集检索方法,可以从整个语料库中检索相关文档,但需要大量配对文本数据进行对比训练。
那么,有没有一种方法既不需要训练,又能高效检索整个语料库呢?今天要介绍的PromptReps方法,就像是AI界的”变形金刚”,兼具了上述两种方法的优点 – 无需训练,却能高效检索整个语料库。它是如何做到的呢?让我们一起来揭开这个AI”变形金刚”的神秘面纱吧!
🔍 PromptReps: AI界的”变形金刚”
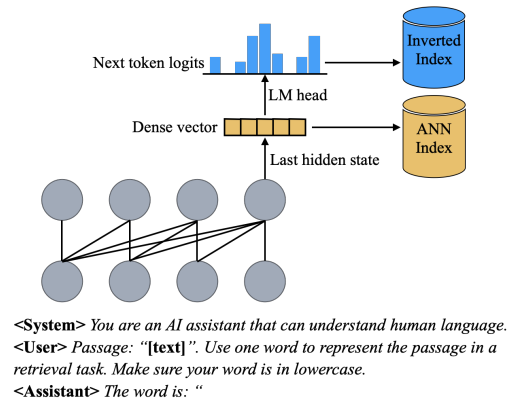
PromptReps的核心思想非常巧妙:通过精心设计的提示,引导大语言模型同时生成密集和稀疏的文本表示,然后用这些表示构建搜索索引。这就像是教会了AI一种新的”语言”,让它能够用简洁而富有信息量的方式描述文档内容。
具体来说,PromptReps的工作流程如下:
- 📝 设计提示: 要求LLM用一个单词来概括给定的文本(查询或文档)。
- 🧠 提取表示:
- 密集表示: 使用提示中最后一个标记的最后一层隐藏状态。
- 稀疏表示: 利用与预测下一个标记相关的logits。
- 🗂️ 构建索引: 利用生成的表示构建混合检索系统,包括密集检索和稀疏检索两部分。
这种方法就像是教会了AI用两种不同的”语言”来描述文档:一种是”密语”(密集表示),捕捉文档的整体语义;另一种是”关键词”(稀疏表示),突出文档的重点内容。这样,无论用户以何种方式描述需求,AI都能快速找到相关文档。
🧪 实验结果:AI “变形金刚”的实力如何?
为了验证PromptReps的效果,研究人员在多个数据集上进行了实验,包括MSMARCO、TREC深度学习和BEIR零样本文档检索数据集。结果表明,这种简单的基于提示的LLM检索方法能够达到甚至超过当前最先进的、经过大规模无监督数据训练的LLM嵌入方法的检索效果,尤其是在使用更大规模LLM时。
让我们来看一些具体数据:
| 数据集 | BM25 | E5-PTlarge | LLM2Vec | PromptReps (Llama3-70B-I) |
|---|---|---|---|---|
| BEIR平均 | 43.70 | 44.61 | 41.38 | 45.88 |
| TREC-COVID | 59.47 | 61.8 | 63.34 | 76.85 |
| NQ | 30.55 | 41.7 | 37.65 | 46.97 |
从这些数据可以看出,PromptReps在多个数据集上都表现出色,尤其是在TREC-COVID和NQ数据集上,大幅超越了其他方法。这说明PromptReps不仅能够有效捕捉文档的语义信息,还能很好地适应不同类型的检索任务。
💡 PromptReps的创新与优势
- 🚀 零样本学习: 无需额外训练,直接利用LLM的知识进行文档检索。
- 🔄 双重表示: 同时生成密集和稀疏表示,兼顾语义理解和关键词匹配。
- 📊 高效索引: 可以为整个文档库建立索引,支持大规模检索。
- 🌈 灵活适应: 适用于各种检索任务和领域,泛化能力强。
- 💰 成本效益: 无需昂贵的训练过程,节省计算资源和时间。
🔮 未来展望:AI检索的新篇章
PromptReps的成功为AI文档检索领域开辟了新的方向。未来,我们可以期待以下发展:
- 提示工程的深入研究: 探索更优的提示设计,进一步提升检索效果。
- 与其他技术的结合: 如融合知识图谱,增强语义理解能力。
- 多模态检索: 扩展到图像、视频等多模态数据的检索。
- 个性化检索: 根据用户偏好动态调整检索策略。
- 可解释性研究: 深入分析LLM生成表示的机制,提高模型的可解释性。
🎓 结语:AI检索的未来已来
PromptReps的出现,标志着AI文档检索技术进入了一个新的阶段。它不仅展示了大语言模型的强大潜力,也为解决实际应用中的检索问题提供了一种高效、灵活的解决方案。随着这项技术的不断发展和完善,我们可以期待看到更多创新应用,让AI真正成为我们获取信息的得力助手。
未来,当你面对海量信息时,也许只需轻声对AI说:”帮我找找相关资料”,它就能像变形金刚一样,瞬间变身为你的专属搜索引擎,为你展现信息的海洋。让我们一起期待AI检索技术的美好未来吧!
📚 参考文献
- Zhuang, S., et al. (2024). PromptReps: Prompting Large Language Models to Generate Dense and Sparse Representations for Zero-Shot Document Retrieval. arXiv:2404.18424v2.
- Wang, X., et al. (2024). E5: A New Frontier of Language Model Pre-training with Efficient Encoder-Only Architectures. arXiv:2401.01140.
- BehnamGhader, P., et al. (2024). LLM2Vec: Transforming LLMs into Zero-Shot Dense Text Encoders. arXiv:2402.04255.
- Sun, Z., et al. (2023). RankGPT: Ranking in Generative Pre-trained Transformers. arXiv:2305.02182.
- Ma, X., et al. (2023). Prompt-based List-wise Learning to Rank Using Generative Language Models. arXiv:2305.11176.
发表回复