在当今数字时代,用户界面(UIs)和信息图(infographics)在促进人类交流和人机交互中扮演着至关重要的角色。它们不仅通过布局和视觉线索将复杂数据和思想简化为易于理解的图示,还在推动用户体验的丰富性与互动性方面发挥了重要作用。为了解决这些视觉语言和设计原则的复杂性,我们提出了ScreenAI——一种专门针对用户界面和信息图理解的视觉语言模型(VLM)。
友情链接:ACEJoy
🌐 视觉语言模型的诞生
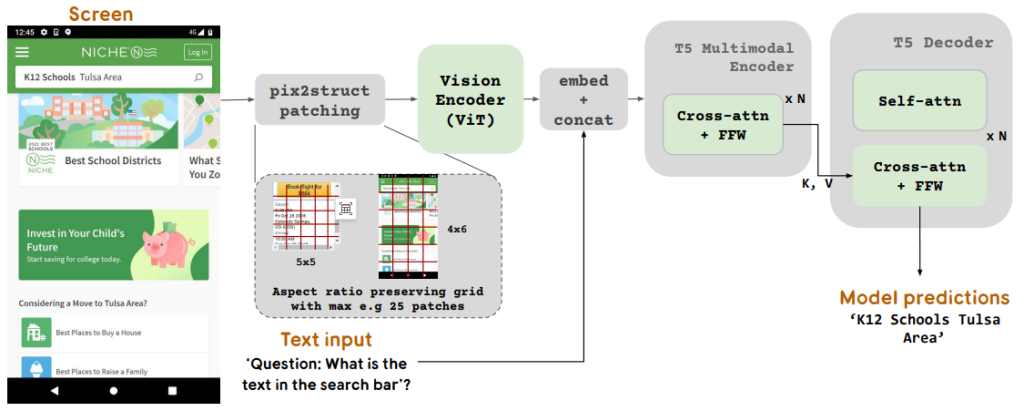
ScreenAI的基础架构借鉴了PaLI架构,并结合了Pix2Struct的灵活拼接策略,旨在处理各种格式的图像。这种模型通过将视觉任务重新构建为(文本,图像)到文本的问题,从而实现了对复杂视觉内容的深刻理解。我们在多种数据集上进行了训练,特别是创新性的屏幕注释任务,要求模型识别用户界面元素的类型和位置。这种训练使得ScreenAI不仅能够生成大规模的问题回答(QA)和用户界面导航数据集,还能进行信息摘要。
模型架构
ScreenAI的整体架构如图1所示,模型包含一个图像编码器(ViT)和一个多模态编码器,后者处理嵌入的文本和图像特征。该架构的设计允许我们使用相同的模型来解决各种视觉和多模态任务。此外,我们的拼接策略允许处理不同形状和比例的图像,确保模型能够适应各种屏幕格式。
📈 训练与创新
数据生成与自我监督
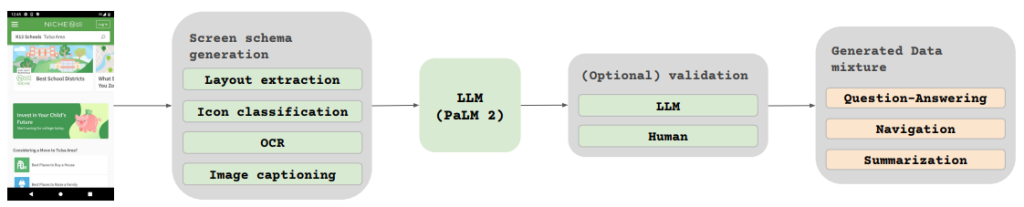
在训练过程中,我们面临着手动标注庞大数据集的挑战。为了实现高效的数据生成,我们采用了一种自动化的方法,利用小型模型生成和标注数据。这一方法不仅提高了效率,还确保了数据的多样性和复杂性。我们通过抓取各种设备的屏幕截图,并使用基于DETR的布局注释器进行详细标注,从而构建了一个全面的理解框架。
注释过程
我们收集了来自桌面、移动设备和平板的屏幕截图,并为每个用户界面元素提供了详细的标签,描述其空间关系及其他信息。图2展示了我们的任务生成流程,其中包括对图标的分类、文本的OCR识别和图像的描述。
预训练与微调
ScreenAI经过多个阶段的训练:预训练时,我们利用自我监督学习生成大规模数据集,而在微调阶段,则结合人类标注的数据,针对各种任务进行优化。为了增强模型的能力,我们特别关注问题回答任务,识别出在算数、计数和复杂信息图理解等方面的性能差距,并进行了针对性的训练。
📊 实验与结果
在对ScreenAI的性能进行评估时,我们将其与多种现有的最先进模型(SoTA)进行了比较。结果显示,ScreenAI在多个公共基准上均取得了优异表现,包括Multipage DocVQA、WebSRC和MoTIF等任务。特别是在信息图QA任务中,ScreenAI的表现超过了其他同类模型,展现出强大的竞争力。
模型规模的影响
我们发现,随着模型参数的增加,性能也随之提升。尤其在需要复杂视觉文本和算数推理的任务中,如InfoVQA和Complex ScreenQA,5B模型的表现明显优于较小的670M和2B模型,表明模型的规模对于处理复杂任务至关重要。
🔍 未来的探索与挑战
尽管ScreenAI在多个任务中表现优异,但我们仍然意识到在某些任务上与更大规模模型(如GPT-4、Gemini)之间存在性能差距。这提示我们需要继续深入研究,以进一步提升模型的能力。为此,我们将发布包含统一表示的新数据集,以及用于屏幕相关任务的其他基准数据集,以促进研究的深入。
📝 结论
ScreenAI的推出标志着数字内容理解领域的一次重大进步。通过整合用户界面和信息图的理解,我们为未来的研究提供了新的方向和工具。随着数字世界的不断发展,ScreenAI将作为理解复杂视觉信息的有力工具,推动人机交互的未来。
参考文献
- Baechler, G., Sunkara, S., Wang, M., et al. (2024). ScreenAI: A Vision-Language Model for UI and Infographics Understanding. IJCAI.
- Chen, J., et al. (2023). PaLI: A Unified Vision-Language Model.
- Lee, Y., et al. (2023). Pix2Struct: Flexible Visual Input for Transformers.
- Mathew, G., et al. (2021). DocVQA: A Dataset for Document Visual Question Answering.
- Zang, H., et al. (2021). Detecting UI Elements in Screenshots.
发表回复