
引言
人工智能领域正在探索通向通用人工智能(AGI)的道路,其中一个重要方向是开发”语言智能体”。语言智能体是复杂的大型语言模型(LLM)管道,涉及提示技术和工具使用方法。虽然语言智能体在许多现实世界任务中展现了令人印象深刻的能力,但当前语言智能体研究的一个根本局限性在于它们是以模型为中心或以工程为中心的。也就是说,语言智能体的提示、工具和管道的进展需要人类专家而非自动从数据中学习进行大量的手动工程努力。
我们认为,语言智能体从以模型为中心或以工程为中心向以数据为中心的转变,即语言智能体在环境中自主学习和进化的能力,是它们可能实现AGI的关键。
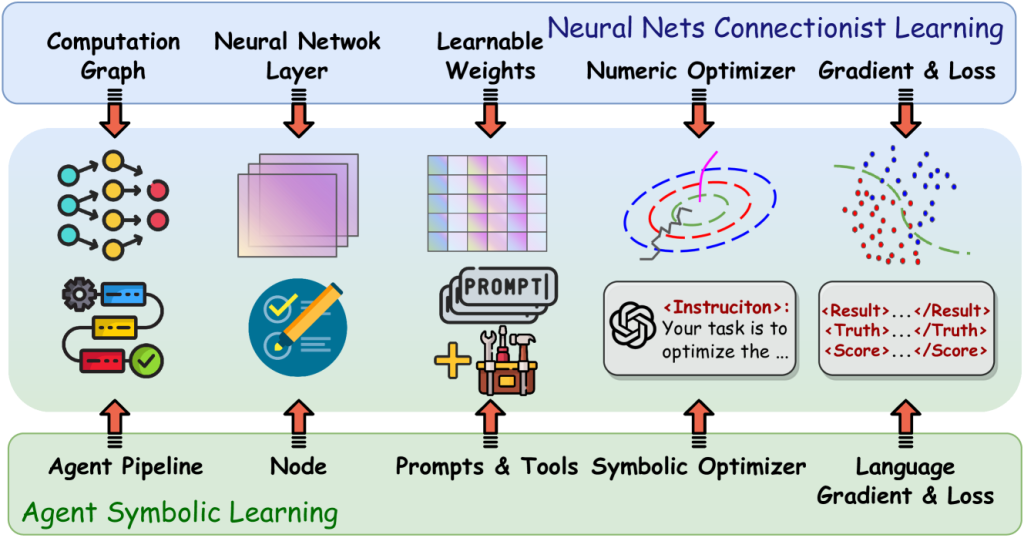
智能体符号学习
为了实现这一目标,本文介绍了智能体符号学习,这是一个系统框架,能够使语言智能体以数据为中心的方式使用符号优化器自我优化。具体而言,我们将智能体视为符号网络,其中可学习的权重由提示、工具以及它们的堆叠方式定义。智能体符号学习旨在通过模仿连接主义学习中的两个基本算法来优化语言智能体中的符号网络:反向传播和梯度下降。与处理数值权重不同,智能体符号学习使用自然语言模拟权重、损失和梯度。
智能体符号学习框架的主要组成部分包括:
- 智能体管道(Agent Pipeline):类似于神经网络中的计算图,表示智能体处理输入数据的节点(或步骤)序列。
- 节点(Node):智能体管道中的单个步骤,类似于神经网络中的层。每个节点接收输入,使用LLM、提示和工具进行处理,然后输出结果。
- 轨迹(Trajectory):存储前向传播过程中的所有信息,包括每个节点的输入、输出、提示和工具使用情况。
- 语言损失(Language Loss):通过精心设计的提示实现的自然语言损失函数,用于评估智能体的输出结果。
- 语言梯度(Language Gradient):用于更新智能体中每个组件的文本分析和反思。
智能体符号学习的工作流程如下:
- 前向传播:执行标准智能体操作,同时将信息存储在轨迹中。
- 语言损失计算:使用精心设计的提示模板计算语言损失。
- 语言梯度反向传播:从最后一个节点到第一个节点迭代,计算每个节点的梯度。
- 基于语言梯度的更新:使用符号优化器更新每个节点中的提示和工具,以及整体智能体管道。
实验结果
为了验证智能体符号学习框架的有效性,我们在标准LLM基准测试和复杂的智能体任务上进行了一系列实验。
标准LLM基准测试结果
在HotpotQA、MATH和HumanEval等标准LLM基准测试上,智能体符号学习框架始终优于所有比较方法。特别是在MATH(一个竞赛级别的基准测试)上,性能提升尤为显著。相比之下,传统的基于LLM的提示优化方法和基于搜索的提示优化方法并不稳定:在某些情况下会带来良好的性能提升,但在其他情况下会导致显著的性能下降。这表明智能体符号学习框架更加稳健,能够更有效地优化语言智能体的整体性能。
复杂任务结果
在软件开发和创意写作这两个复杂任务上,我们的方法显著优于所有比较基线,性能差距比在常规LLM基准测试上更大。有趣的是,我们的方法在创意写作任务上甚至超过了精心设计的思维树(Tree-of-Thought)提示工程和推理算法。我们发现,我们的方法成功地找到了计划、写作和修订的管道,并且每个步骤中的提示都得到了很好的优化。我们还发现,智能体符号学习框架恢复了类似于MetaGPT(一个专门为软件开发设计的智能体框架)中开发的标准操作程序。
案例研究与分析
我们展示了智能体符号学习框架在创意写作任务上的优化动态案例研究。结果表明,我们的方法能够有效地进行提示工程并设计智能体管道,方式类似于人类专家开发语言智能体的方式。
此外,我们发现智能体系统的初始化对最终性能有不可忽视的影响,就像神经网络的初始化对训练很重要一样。总的来说,我们发现以最简单的方式初始化智能体,然后让符号优化器进行优化通常是有帮助的。相比之下,如果初始智能体系统过度工程化,性能往往会变得不稳定。
结论
本文介绍了智能体符号学习,这是一个能够联合优化智能体系统内所有符号组件的智能体学习框架。智能体符号学习框架借鉴了标准连接主义学习程序的灵感来进行符号学习。它使用基于语言的损失、梯度和优化器来优化提示、工具和智能体管道,以提高智能体系统的整体性能。
我们的框架是首次尝试优化能够使用复杂管道解决复杂现实世界任务的智能体。我们的框架使语言智能体能够”从数据中学习”并在创建和部署后在野外进行”自我进化”。我们进行了几个概念验证实验,表明智能体符号学习框架可以有效地优化不同任务复杂度的智能体。
我们相信,从以模型为中心到以数据为中心的智能体研究转变是朝着通用人工智能迈进的一个有意义的步骤。我们开源了智能体符号学习框架的代码和提示,以加速这一转变。
参考文献
- Zhou, W. et al. (2023). Symbolic Learning Enables Self-Evolving Agents. arXiv preprint arXiv:2406.18532v1.
- Brown, T. et al. (2020). Language models are few-shot learners. Advances in Neural Information Processing Systems, 33, 1877-1901.
- Park, J. S. et al. (2023). Generative agents: Interactive simulacra of human behavior. arXiv preprint.
- Khattab, O. et al. (2023). Dspy: Compiling declarative language model calls into self-improving pipelines. arXiv preprint arXiv:2310.03714.
- Zhang, S. et al. (2024). Offline training of language model agents with functions as learnable weights. arXiv preprint.