在人工智能的浩瀚星海中,大型语言模型如同耀眼的恒星,它们的能力强大而深不可测。然而,这些模型的运作往往需要耗费巨大的计算资源,这也成为了阻碍AI技术广泛应用的一大障碍。今天,让我们一起探索那个改变游戏规则的创新项目——H2O。
友情链接:ACEJoy
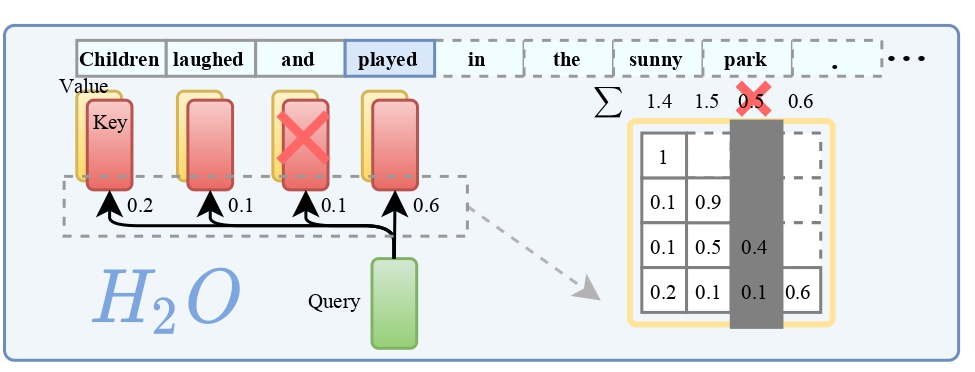
引领潮流的创新:H2O的诞生 🌟
在NeurIPS’23大会上,一项名为H2O的研究引起了广泛关注。这是一种被称作“重点词神器”的技术,它使得大型语言模型的生成变得更加高效。那么,H2O到底是什么呢?
简而言之,H2O是一种优化了的内存管理方案,它通过智能地管理键值(KV)缓存来减轻模型推理过程中的计算负担。KV缓存通常与序列长度和批量大小成线性关系,而H2O能够大幅减少这些缓存的内存占用。
精华所在:重点词的力量 💡
H2O的核心概念在于识别和利用了“重点词”——这些词在计算注意力得分时占有压倒性的重要性。研究者发现,这些词与文本中的频繁共现词强相关,若将它们从模型中移除,性能会大打折扣。H2O正是利用了这一洞察,通过平衡最近词和重点词,优化了KV缓存的管理。
实践证明:H2O的效能 🛠
H2O不仅在理论上前卫,它的实用性也已经在各种任务和不同规模的模型上得到了验证。
实验表明:在保留两成重点词的情况下:
通过H2O优化的大型模型在性能上可以实现高达29倍的吞吐量提升!
这在当前领先的如DeepSpeed Zero-Inference、Hugging Face Accelerate和FlexGen等推理系统中表现尤为突出。
开源精神:与社区共建 🌐
值得庆幸的是,H2O项目已经在GitHub上开源,任何对AI充满热情的开发者和研究者都可以参与其中。无论是想提高你的语言模型生成效率,还是仅仅出于好奇,你都可以在这个平台上找到价值。
结语:跨越技术的鸿沟 ✨
随着H2O的横空出世,那些曾经遥不可及的AI技术现在似乎触手可及。这个项目不仅仅是技术的飞跃,更是开启普通人使用强大AI工具的大门。让我们拭目以待,看看H2O将如何在未来的日子里,继续激起技术革新的波澜!
发表回复