
在今天的科技热点之旅中,我们要探讨的是一个源自语言模型领域的新词:StreamingLLM。这个强大的技术,旨在打破大型语言模型(LLM)在推理时只能记住有限上下文的限制。音乐会有无尽的旋律,那么,人工智能的语言模型是否也能拥有无尽的生成能力呢?让我们一起揭秘这个问题的答案。
1. LLM的限制:有限的上下文记忆
先让我们理解一下问题的背景。在现行的语言模型,如LLama2中,模型只能处理4K长度的上下文。这个限制导致了两个问题:一是模型无法记住超过最近4K上文的内容,二是当生成文本达到4K时,模型会自动停止。这在某种程度上限制了我们对AI对话助手的期望,我们希望它能不受输出长度的限制,并记住历史的对话。
2. StreamingLLM的提出:无限序列长度的输入和输出
然后,MIT,Meta AI,CMU的研究团队提出了一个全新的解决方案:StreamingLLM。他们声称,这种方法可以使得大型语言模型在无需任何微调的情况下,推广到无限序列长度的输入和输出。请注意,这个方法并没有增加LLM的对上文的记忆,只是让它输入输出无限长。这样的好处显而易见,例如,当你需要对话机器人生成一个很长的回答时,你不再需要输入「继续」。
3. StreamingLLM的核心技术:Attention Sink
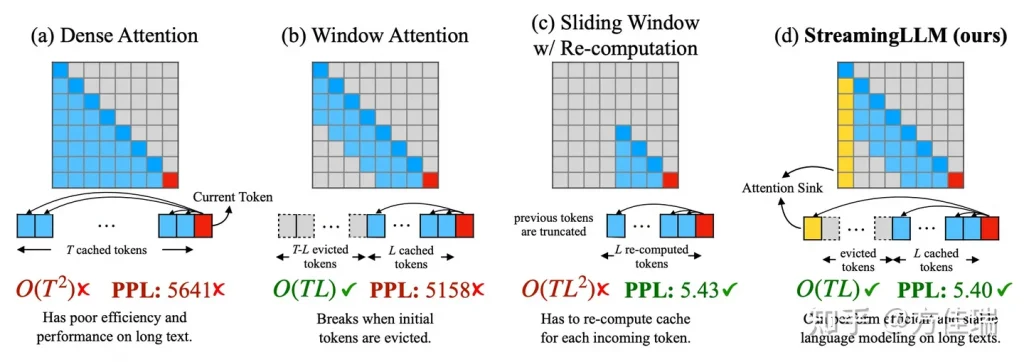
那么,StreamingLLM是如何实现这个目标的呢?关键在于MIT韩松老师实验室的主要作者Guangxuan Xiao提出的一个名叫「Attention Sink」的技术。这个技术在处理Transformer推理时,解决了一些非常有趣的问题。他们的研究成果在学界得到了广泛的关注,并已经在github上开源。
4. StreamingLLM的解决挑战:处理无限输入的LLM
StreamingLLM的目标是在不牺牲效率和性能的情况下,部署一个能处理无限输入的LLM。这样的模型可以不受长度限制不停地输出,具体效果可以参考他们的主页视频。然而,这并非易事,面临着诸多挑战。
一个挑战是在解码阶段,由于KV Cache的存在,会导致内存使用或延迟增加,而内存上线和推理服务SLA的存在,又使得KV Cache不能无限大,这构成了性能瓶颈。另一个挑战是现有模型的外推能力有限,当序列长度超过预训练时设定的注意力窗口大小时,它们的表现会下降,这是模型能力的瓶颈。
在面对这些挑战时,StreamingLLM通过使用近似注意力的方法,放松了对全部输入记忆的限制,仍然只记住最近的上下文,但实现了处理无限输入并获得无限输出的效果。
5. StreamingLLM的突破:Attention Sink
StreamingLLM的另一项重大突破是他们提出了「attention sink」概念,这被认为是解决以上挑战的关键。简单来说,”attention sink”是一个技术,它将注意力集中在最近的上下文中,而非全部的上下文。这种方法大大节省了内存和计算资源,克服了KV Cache的限制,而且它使得模型可以处理无限长度的输入输出,这无疑是对现有模型的重大突破。
6. StreamingLLM的实践应用
StreamingLLM的实际应用非常广泛。比如在AI对话助手中,它可以生成无限长的对话,而且还能记住历史的对话。这对于长对话、长篇文章的生成,无疑提供了更好的用户体验。此外,StreamingLLM还可以应用于其他领域,比如在线翻译、自动问答、编程助手等等,无所不能。
7. StreamingLLM的未来
StreamingLLM的未来充满了可能。就像我们在音乐中能创作出无尽的旋律一样,StreamingLLM为我们的语言模型赋予了无尽的生成能力。我们期待,随着技术的进步,我们能解决更多的挑战,进一步提升模型的性能,让AI更好地服务于人类。
结语:
StreamingLLM技术让我们看到了大型语言模型的无限可能。它打破了有限上下文的限制,开创了无限长的生成能力。这无疑为AI领域带来了新的机遇,也带来了新的挑战。我们期待更多的研究者和开发者加入到这个领域中来,共同推动人工智能的进步。
感谢您的阅读,希望我们的探讨对您有所帮助。在下一次的科技热点之旅中,我们会带来更多有趣的话题。再见!
https://github.com/mit-han-lab/streaming-llm