
Scaling Transformer to 1M tokens and beyond with RMT 这份技术报告展示了循环记忆的应用,以扩展 BERT 的上下文长度,这是自然语言处理中最有效的基于 Transformer 的模型之一。通过利用循环记忆 Transformer 架构,我们成功地将模型的有效上下文长度增加到前所未有的 200 万个标记,同时保持高记忆检索精度。我们的方法允许存储和处理局部和全局信息,并通过使用递归实现输入序列段之间的信息流。我们的实验证明了我们方法的有效性,这具有巨大的潜力来增强自然语言理解和生成任务的长期依赖处理,并为记忆密集型应用程序启用大规模上下文处理。
1。我们通过将基于令牌的记忆存储和段级递归与循环记忆 (RMT) 相结合来增强 BERT。
2. 我们证明了记忆增强 BERT 可以被训练来处理长度不超过其最初设计的输入长度(512 个标记)的序列的任务。
3. 我们发现了经过训练的 RMT 成功推断不同长度的任务的能力,包括那些超过 100 万个令牌,需要线性计算缩放。
4. 通过注意力模式分析,我们发现 RMT 与记忆一起使用的操作,使其能够成功处理异常长的序列。
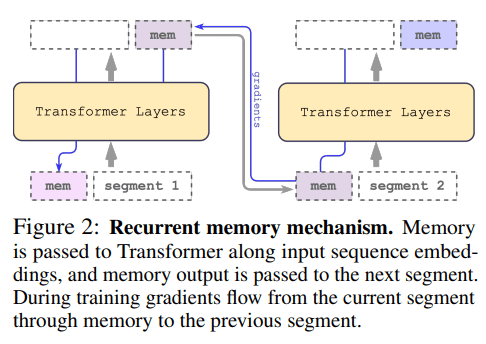
从最初的循环记忆转换器 (Bulatov et al., 2022) (RMT) 开始,我们将其改编为即插即用的方法,作为一系列流行的 Transformer 的包装器。这种适应用内存增强了其主干,由 m 个实值可训练向量组成(图 2)。冗长的输入被分成段,内存向量被添加到第一个段嵌入中,并与段标记一起处理。对于 BERT 等仅编码器模型,与 (Bulatov et al., 2022) 不同,内存仅在段的开头添加一次,其中仅解码器模型将内存分成读写部分。
循环记忆机制。记忆沿输入序列嵌入传递给 Transformer,记忆输出被传递到下一个段。在训练期间,梯度通过记忆从当前段流向前一个段。
通过检查特定片段上的RMT注意,我们观察到记忆操作对应于特定的注意模式。此外,在超长序列上的高外推性能,证明了学习记忆操作的有效性,即使在使用数千次的情况下也是如此。考虑到这些行动的动机不是明确的任务损失,这一点尤其令人印象深刻。
仅限于管段边界内。由于计算繁重的FFN层(其相对于隐藏大小进行二次缩放),较大的Transformer模型往往显示出相对于序列长度的二次方缩放。然而,在大于32,000的超长序列上,它们会回落到二次缩放。对于具有多个片段的序列(在本研究中>512),RMT需要的Flop比非循环模型少,并且可以将Flop的数量减少高达×295倍。RMT为较小的型号提供了更大的相对FLOP减少,但在绝对数字上,OPT-175B型号的×29倍减少是非常显著的。
为了测试记忆能力,我们构建了需要记忆简单事实和基本推理的合成数据集。任务输入由一个或几个事实和一个问题组成,这个问题只能通过使用所有这些事实来回答。为了增加任务难度,我们添加了与问题或答案无关的自然语言文本。这些文本就像噪音一样,所以模型的任务是将事实从不相关的文本中分离出来,并用它们来回答问题。该任务分为6个类别,每个类别代表一个单独的答案选项。事实是使用bAbI数据集(Weston等人,2016)生成的,而背景文本来自QuALITY (Pang等人,2022)长QA数据集中的问题。
QLoRA技术非常有趣,它能有效地降低大型语言模型的内存需求,实现65B模型在单个48GB GPU上的微调。这将有助于更广泛地利用和应用这些大模型。
对于应用到transformer中的方法,4位和8位量化确实可以显著减少硬件资源需求。通过限制权重精度,可以让模型在规模更小的硬件上运行或训练。
此外,训练或微调适配器层而不是整个大模型也是一个有效方式。可以将适配器看作是”插在”预训练模型之上的一层。
让这些大规模、资源密集型的语言模型更易于应用,以扩展其影响力,是好事。但需要注意的一点是,降低精度也会带来性能损失。
QLoRA能取得不错的效果是因为它采用了多种技术,包括新的数据类型NormalFloat和双量化。在设计量化方法时,需要谨慎权衡性能损失与内存效益。
我认为这个研究方向值得深入探索,以实现可扩展和易于部署的大模型。同时,还需要更多实证数据评估不同量化方法的影响。