
核心优化解析:Deepseek-V2利用多头隐式注意力(MLA)进行核心优化。MLA通过减少kv缓存的占用来提高解码速度,并采用低秩推理的方式进行计算。通过详细的配置文件分析,我们可以了解到每个部分的作用和设计原理。
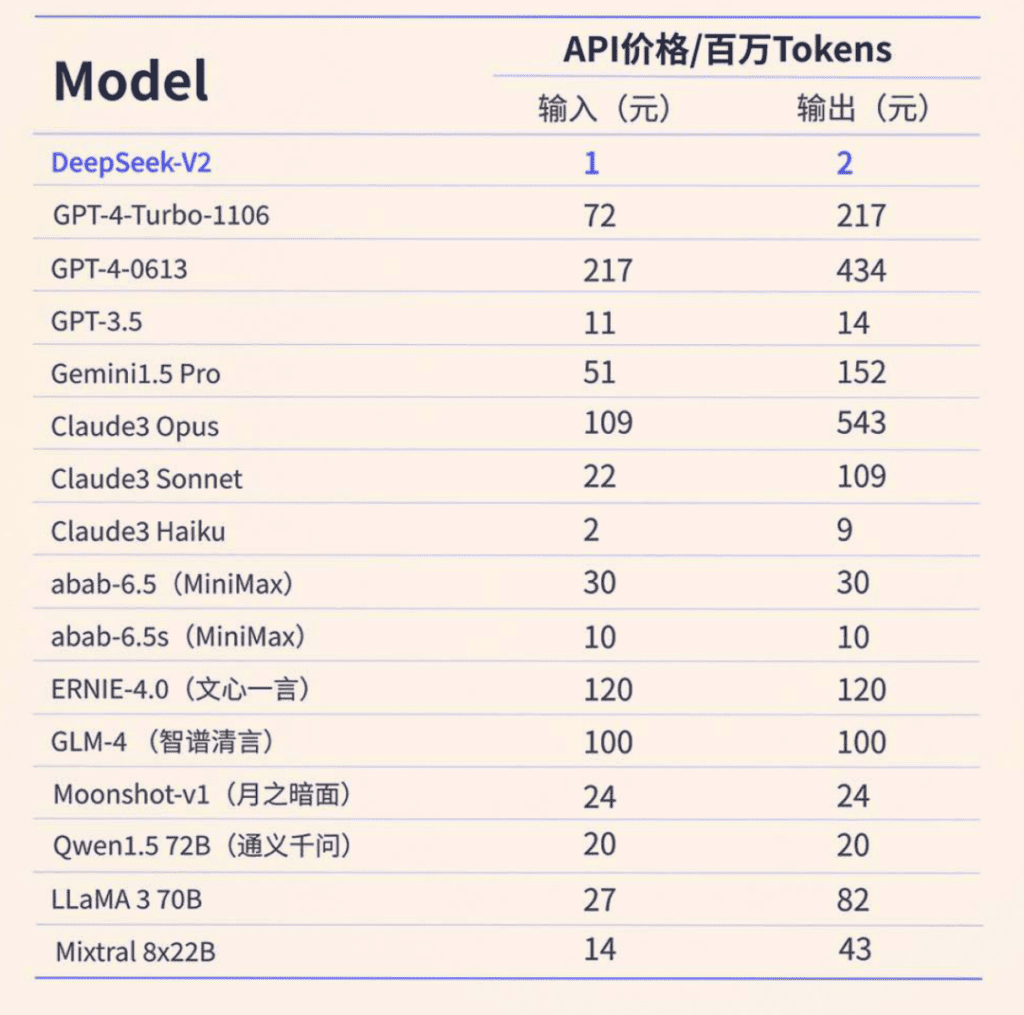
架构解读:Deepseek-V2采用了多层次的模型堆叠架构,经过预处理、注意力计算和多头专家模型等处理。整体架构设计遵循了一系列通用的标准,如pre-norm范式、RMSNorm归一化和SiLU非线性激活函数等。通过详细的架构图和配置文件,我们可以了解模型的设计和计算流程。
训练:Deepseek-V2采用了多种优化策略进行训练。其中包括长度外推训练和模型对齐训练。长度外推训练通过YaRN方法扩展模型的上下文能力,而模型对齐训练通过对话数据进行SFT,并注重指令遵循能力。Deepseek-V2还进行了工程优化,如流水线并行和数据并行等,提高了训练效率。
模型效果:Deepseek-V2在通用能力和成本效率方面取得了显著的成果。在通用能力上,模型在MMLU多选题benchmark上表现出色。在成本效率方面,Deepseek-V2节约了训练成本,减少了显存占用,并提升了生成吞吐量。通过模型效果的测试,Deepseek-V2展现出了强大的基座能力和指令遵循能力。
讨论:Deepseek-V2的讨论部分提到了指令微调数据规模、强化学习对齐税和在线偏好对齐等方面的优化。这些优化方法进一步提升了模型的性能和效果。
总结:Deepseek-V2通过多种优化策略和工程方法取得了突破性的成果。它的架构设计和训练方法经过精心优化,使得模型在通用能力和成本效率方面表现出色。Deepseek-V2的发布为人工智能领域带来了新的突破,为AI技术的发展提供了重要的支持。