欢迎使用 WordPress。这是您的第一篇文章。编辑或删除它,然后开始写作吧!
博客
-
深度学习中的正则化技巧:探索与应用
近年来,深度学习在各个领域取得了令人瞩目的成就。然而,随着模型复杂度的增加,过拟合问题也变得愈发突出。正则化技术作为解决过拟合问题的关键手段,成为了深度学习研究中的重要课题。本文将结合图中的内容,深入探讨几种常见的正则化方法及其在实际应用中的效果。
1. 早停法(Early Stopping)
图中的第9页详细介绍了早停法,这是一种简单而有效的正则化方法。早停法通过在验证集的性能不再提升时停止训练,防止模型在训练集上过度拟合。第11页展示了早停法的原理图,显示了验证误差随训练次数变化的曲线。通过及时停止训练,早停法能有效避免模型在训练数据上的过度拟合。
2. L1和L2正则化
图中的第6页和第7页分别介绍了L1和L2正则化。L1正则化通过在损失函数中加入权重的绝对值和,促使模型产生稀疏权重,有助于特征选择。L2正则化则通过加入权重的平方和,使得权重更平滑,减小模型的复杂度。第13页和第14页展示了L1和L2正则化在不同数据集上的实验结果,验证了其有效性。
3. Dropout
Dropout是一种随机去除神经元的正则化方法,图中的第15页至第23页详细介绍了其原理和应用。Dropout通过在训练过程中随机丢弃一部分神经元,迫使模型不依赖于某些特定的路径,从而增强了模型的泛化能力。第18页至第21页的实验结果显示了Dropout在不同复杂度模型上的应用效果,验证了其在防止过拟合方面的显著作用。
4. 数据增强
数据增强是一种通过对训练数据进行各种变换来增加数据量的方法,图中的第24页至第26页介绍了几种常见的增强技术,如旋转、平移、缩放等。通过增加数据的多样性,数据增强能有效提高模型的泛化能力。第25页展示了不同数据增强技术的效果对比,说明了数据增强在实际应用中的重要性。
5. 批归一化(Batch Normalization)
批归一化通过在每一层网络中对输入数据进行归一化处理,减少了内部协变量偏移,加快了训练速度,并在一定程度上具有正则化效果。图中的第27页至第30页详细介绍了批归一化的原理和在不同网络结构中的应用效果。第29页的实验结果显示,批归一化不仅能加快收敛速度,还能提高模型的最终性能。
6. 其他正则化方法
除了上述几种常见的正则化方法,图中的第31页至第37页还介绍了一些其他的正则化技术,如权重剪枝、随机噪声注入等。这些方法通过不同的机制抑制模型的过拟合,增强了模型的泛化能力。第34页和第36页的实验结果展示了这些方法在实际应用中的效果。
总结
正则化技术在深度学习中扮演着至关重要的角色,通过合理应用这些方法,研究人员和工程师们能够有效地提高模型的泛化能力,避免过拟合问题。随着深度学习技术的不断发展,相信将会有更多创新的正则化方法被提出,为我们带来更强大、更稳定的模型。
通过本文的探讨,我们不仅了解了几种常见正则化方法的原理和应用,还通过图中的实验结果看到了它们在实际中的效果。希望这些内容能为读者在深度学习研究和应用中提供有价值的参考。
-
OpenVidu:快速集成视频通话的利器
在当今数字化时代,实时视频通话已经成为许多应用的核心功能之一。无论是远程医疗、在线教育、客户服务,还是虚拟会议,视频通话的需求都在不断增加。今天,我要向大家介绍的是一款强大的开源平台——OpenVidu,它能帮助开发者快速且低成本地将视频通话功能集成到他们的应用中。
什么是 OpenVidu?
OpenVidu 是一个旨在简化视频通话集成的开源平台。它提供了一整套技术栈,方便开发者快速将实时通讯功能添加到他们的应用中。无论你是开发网页应用还是移动应用,OpenVidu 都能满足你的需求。
主要特性
- WebRTC 视频会议:支持一对一、一对多以及多对多的各种组合,几乎可以实现你能想到的任何场景。
- 开源:OpenVidu 是一个开源项目,使用 Apache License v2 许可证,完全免费。
- 多平台兼容:支持 Chrome、Firefox、Safari、Opera、Edge、Android、iOS 以及桌面应用,所有这些平台都能相互兼容。
- 易于使用:提供即用型组件,只需简单地粘贴代码即可快速实现视频通话。如果你需要更多的自定义,OpenVidu 的 API 也是非常简单且强大的。
- 易于部署:支持在最流行的云服务提供商上进行快速部署,或是通过 Docker 进行本地部署,过程非常简便。
快速入门
开始使用 OpenVidu 非常简单。你可以参考 OpenVidu 文档 中的“Getting started”部分,了解如何安装和配置 OpenVidu。以下是一些关键步骤:
- 安装 OpenVidu Server:你可以选择在 AWS 上一键部署 OpenVidu,也可以使用 Docker 在本地部署。
- 集成前端和后端:OpenVidu 提供了多种前端技术的示例,如 JavaScript、Angular、React、Vue.js 等。后端技术则包括 Java、Node.js 以及 REST API,方便你选择适合的技术栈。
开发你的视频应用
OpenVidu 提供了丰富的教程和示例,帮助你快速上手。以下是一些推荐的步骤:
- 学习基础知识:文档中提供了“Hello World”示例,帮助你快速了解基本的 API 调用和使用方法。
- 探索高级功能:你可以查看“Advanced features”部分,了解如何实现录制视频、屏幕共享、音视频滤镜等高级功能。
- 使用现成组件:如果你希望快速实现某些功能,可以使用 OpenVidu 提供的即用型组件,如自定义 UI、自定义工具栏等。
安全性和隐私保护
OpenVidu 非常重视用户的隐私和安全。它通过 WebRTC 加密、服务器 API 和客户端基于角色的系统,确保所有通话内容都是完全私密的。此外,OpenVidu 还允许你限制客户端的能力,通过预定义角色来决定用户是否可以订阅、发布或管理视频流。
适用场景
OpenVidu 的应用场景非常广泛,包括但不限于以下几种:
- 客户服务:集成一对一视频通话中心,提供面对面的客户服务。
- 远程医疗:医生可以通过视频通话直接与患者进行交流,确保私密和安全。
- 在线教育:教师可以通过视频通话向学生讲解课程,支持多名学生同时在线。
- 会议服务:支持演讲者实时应用音视频滤镜,提高会议质量。
- 安防系统:接收来自安防摄像头的视频流,实现监控功能。
结语
无论你是想开发一个简单的视频聊天应用,还是一个复杂的视频会议系统,OpenVidu 都能提供强大的支持。它不仅简化了开发过程,还提供了丰富的功能和高水平的安全性,是你开发视频通话应用的不二选择。
更多详细信息和教程,请访问 OpenVidu 文档。
参考文献:
- OpenVidu 官方文档:https://docs.openvidu.io/en/stable/
-
Android设备上NEON支持的ffmpeg解码性能
在Android设备上使用ffmpeg进行视频解码是一种常见的方案,但如果没有NEON支持,性能可能会受到显著影响。本文将详细探讨在没有NEON支持的情况下,ffmpeg在Android设备上的解码性能,并分享一些解决方案和优化策略。
什么是NEON?
NEON技术是ARM架构的一部分,它是一种高级SIMD(单指令多数据)架构,能够加速多媒体和信号处理应用中的向量操作。简而言之,NEON能够显著提高处理音视频等多媒体内容的效率。因此,缺少NEON支持的设备在处理这些任务时性能会大打折扣。
问题描述
在Stack Overflow的一个讨论中,有用户提到在Android设备上编译ffmpeg并成功播放视频,但帧率非常低,仅有5fps。这种情况在没有NEON支持的armv5te设备上尤为明显。用户尝试了多种配置,但仍然无法提高帧率。
原帖中提到的配置命令如下:
./configure --enable-gpl --enable-libgsm --enable-libxvid \ --enable-libamr_nb --enable-libamr_wb --enable-libmp3lame --enable-libogg \ --enable-libvorbis --enable-libfaac --enable-libfaad --enable-shared解决方案与优化
使用静态编译
另一位用户分享了在Galaxy Tab上使用ffmpeg进行视频解码的经验,尽管该设备理论上支持NEON,但他并未使用NEON支持,仍然能够达到60fps的帧率。他使用的是静态编译版本,而非共享库版本。具体配置命令如下:
./configure --enable-static --disable-shared --disable-doc --disable-ffmpeg \ --disable-ffplay --disable-ffprobe --disable-ffserver \ --disable-avdevice --disable-neon --disable-network \ --disable-swscale-alpha --enable-zlib --enable-memalign-hack \ --disable-stripping --enable-cross-compile --arch=arm5te \ --enable-armv5te --target-os=linux --cc=arm-linux-androideabi-gcc \ --extra-cflags='-fPIC -DANDROID -D__thumb__ -mthumb'使用NEON支持
另一用户则表示,在启用NEON支持并使用armv7架构后,帧率大幅提升至40fps,满足了应用需求。具体配置如下:
./configure --enable-gpl --enable-libgsm --enable-libxvid \ --enable-libamr_nb --enable-libamr_wb --enable-libmp3lame --enable-libogg \ --enable-libvorbis --enable-libfaac --enable-libfaad --enable-shared \ --enable-neon --arch=armv7结论
在没有NEON支持的设备上运行ffmpeg解码确实会遇到性能瓶颈,但通过静态编译和其他优化策略,仍然可以达到较为满意的解码效果。如果可能,启用NEON支持和使用较新的ARM架构(如armv7)将显著提升性能。
参考文献
- Stack Overflow – Performance of ffmpeg decoding on android without neon support
通过参考这些讨论和配置,你可以在开发过程中针对不同设备进行优化,提升ffmpeg解码的性能。
-
Llama-3-70B:突破性未审查模型
在人工智能领域,模型的性能和应用范围不断拓展。最近,由Exllama社区的一位成员进行的一次微调,使得Llama-3-70B模型在未审查的通用智能排行榜上名列前茅。这一排行榜是一个封闭的基准,无法通过作弊来提高分数。这一成就不仅让人瞩目,也为未来的AI发展提供了新的方向。
新模型的诞生
Llama-3-70B模型的微调由Exllama社区的一名成员完成。这次微调不仅提升了模型的性能,还使其在未审查的通用智能排行榜上夺得了第一名。这一排行榜由其创建者严格维护,确保其真实性和公平性。
排行榜创建者表示:“大多数我测试的模型在默认模板下表现良好,我猜测是llama.cpp检测到了这个模板。然而,turboderp/Cat-Llama-3-70B-instruct在使用提供的模板时,得分有了显著提升。它的知识量相当惊人,并且在使用聊天模板时几乎没有受到审查。”
模型的具体表现
Llama-3-70B模型在使用聊天模板时表现尤为出色。它不仅展示了广泛的知识,还在对话过程中表现出了一种“未审查”的特质。未审查的特质意味着模型能够更加自由地生成内容,而不受严格的限制。这种特性使得模型在实际应用中更加灵活和实用。
为了充分发挥Llama-3-70B模型的潜力,用户需要使用ChatML格式来运行该模型。此外,系统提示通常使用“Below is a”语句效果更佳,而非“You are”语句。例如,一个好的系统提示可以是:“Below is a conversation between an AI entity and a human.”
使用指南
如果您有兴趣探索和使用Llama-3-70B模型,可以在以下链接找到完整精度的模型:
在运行模型时,请务必使用ChatML格式,并且在系统提示中使用“Below is a”语句。这将确保模型在对话中的最佳表现。
未来展望
Llama-3-70B模型的成功不仅是技术上的突破,也是人工智能应用领域的一次重要进步。它展示了通过微调和优化,可以显著提升模型性能,并使其在实际应用中更加灵活和高效。未来,我们可以期待更多类似的创新,为我们的生活带来更多便利和可能性。
参考文献:
- Exllama社区成员微调的Llama-3-70B模型
- 未审查的通用智能排行榜创建者的评论
-
小红书社会学:社会阶层伪装、女性主义与父权制
近年来,小红书迅速崛起,成为观察当代中国中产阶级,尤其是中产女性生活方式的绝佳窗口。本文将深入探讨小红书中的女性主义与父权制,以及这一平台如何反映和影响社会阶层的伪装。
小红书上的女性主义与父权制
据统计,小红书用户中有七成是女性,从平台上流行的“姐妹”称呼中便可见一斑。即便是男性用户,也常常被称为“姐妹”。为何小红书上女性用户如此之多?这背后有着深刻的社会原因。
我们生活在一个父权制社会中,社会给予女性实现自我价值的机会本就不多,尤其是经济独立方面,女性往往比男性面临更多障碍。因此,女性更需要通过生活方式的展演来确认自己的社会地位和自我价值。小红书正好提供了这样一个平台,让女性用户通过分享和展示自己的生活方式,获得认同和满足感。
消费主义的“天鹅绒监狱”
小红书的另一个显著特点是“种草”,即引导消费。平台上的内容常常呈现一种消费体验的图文景观堆积,诸如“女生要对自己好一点”、“为自己而变美”、“人生在于体验”等话语表面上鼓励女性实现自我价值,实则是在引导女性消费。这种虚伪的消费主义话语,正是现代社会男性规训女性的表现,让女性成为依附的“天鹅绒监狱”。
另外,男性欲望的“凝视”也是一种明显的父权制规训。在小红书上,化妆护肤、美容减肥、日常穿搭等内容非常重要,这其实是女性为了迎合父权凝视的自我规训。
“擦边”行为与男性凝视
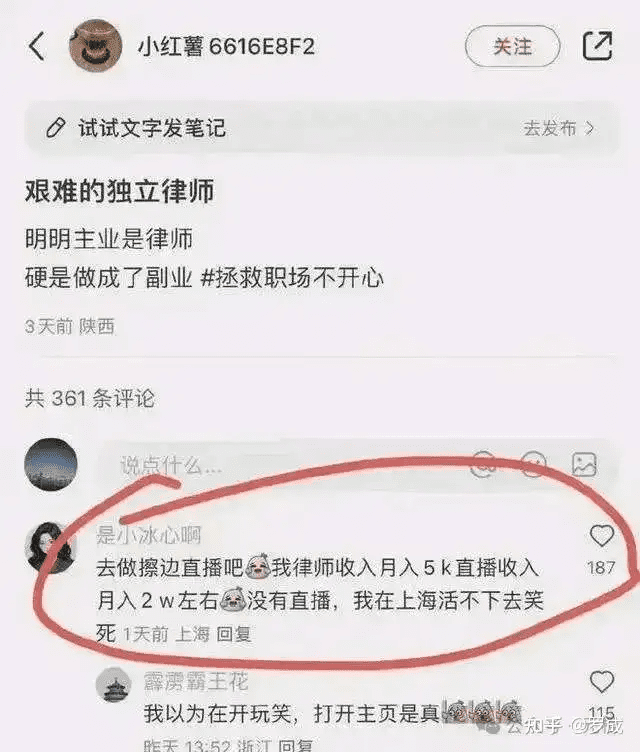
更为赤裸的迎合男性凝视的行为则是“擦边”,即带有性意味的图片、视频及直播内容。例如,有女律师博主表示自己做律师收入太低,月入5000元,但靠“擦边”直播却能月入两万元。这种现象在小红书上并不罕见,反映了女性在父权制社会中为了经济利益而被迫迎合男性欲望的现实。
社会阶层的伪装
小红书不仅是女性展示生活方式的平台,也是中产阶级伪装和炫耀的场所。通过分享奢侈品、豪宅、名车等内容,用户们在平台上构建起一个理想化的生活方式,展示自己的社会地位和经济实力。然而,这种展示往往只是表面的伪装,背后可能隐藏着巨大的经济压力和心理负担。
中产阶级的虚假繁荣
中产阶级因为没有真正的资产积累,往往通过消费来维持和展示自己的社会地位。在小红书上,我们可以看到大量中产阶级用户通过分享奢侈品购物、豪华旅游等内容,来构建自己理想化的生活方式。然而,这种虚假的繁荣背后,隐藏着巨大的经济压力和心理负担。
社会阶层的流动性
小红书上的生活方式展示,也反映了当代社会阶层的流动性。中产阶级通过消费展示自己的社会地位,而这种展示往往是短暂和脆弱的。一旦经济状况发生变化,这种虚假的繁荣便会迅速崩塌。因此,小红书上的生活方式展示,既是对现有社会阶层的维护,也是对未来不确定性的焦虑。
结语
小红书作为一个新兴的社交平台,反映了当代中国中产阶级,尤其是中产女性的生活方式和社会地位。通过分析小红书上的女性主义与父权制现象,我们可以看到,女性在这个平台上既展示了自我价值,也被迫迎合父权制社会的规训。同时,小红书上的消费主义和社会阶层伪装,也反映了中产阶级的虚假繁荣和社会阶层的流动性。
参考文献:
- 罗成. 小红书社会学:社会阶层伪装、女性主义与父权制. 罗成读书. 2024年5月9日
-
ChatTTS:专为对话场景设计的文本转语音模型
在人工智能领域中,文本转语音(TTS)技术一直是备受关注的研究方向。今天,我们要介绍的是ChatTTS,一个专为对话场景设计的文本转语音模型。ChatTTS不仅支持中文和英文,还能够在多种应用中展现出色的表现。
ChatTTS的特点
对话式TTS
ChatTTS针对对话任务进行了优化,能够生成自然流畅的语音,并支持多说话人。这使得它在模拟人类对话时,更加真实和生动。
细粒度控制
该模型能够预测和控制细粒度的韵律特征,包括笑声、停顿和插入词等。这使得生成的语音更加丰富和多样,能够更好地传达说话者的情感和意图。
更好的韵律
ChatTTS在韵律方面超越了大部分开源的TTS模型。它能够生成具有自然韵律的语音,使得听起来更加舒适和真实。同时,ChatTTS还提供预训练模型,支持进一步的研究和应用。
使用方法
基本用法
以下是ChatTTS的基本用法示例:
import ChatTTS from IPython.display import Audio chat = ChatTTS.Chat() chat.load_models() texts = ["<PUT YOUR TEXT HERE>",] wavs = chat.infer(texts, use_decoder=True) Audio(wavs[0], rate=24_000, autoplay=True)进阶用法
如果需要更高级的控制,可以使用以下代码:
import torch # 采样一个说话人 std, mean = torch.load('ChatTTS/asset/spk_stat.pt').chunk(2) rand_spk = torch.randn(768) * std + mean params_infer_code = { 'spk_emb': rand_spk, 'temperature': .3, 'top_P': 0.7, 'top_K': 20, } params_refine_text = { 'prompt': '[oral_2][laugh_0][break_6]' } wav = chat.infer("<PUT YOUR TEXT HERE>", params_refine_text=params_refine_text, params_infer_code=params_infer_code)实际应用案例
智能客服系统
ChatTTS可以在智能客服系统中发挥重要作用。通过其自然流畅的语音生成能力,能够提供更加亲切和人性化的客服服务,提升客户满意度。
教育领域
在教育领域,ChatTTS可以帮助教师制作生动的教学语音材料。学生可以通过听取这些语音材料,更加直观地理解和掌握知识。
娱乐领域
在游戏和影视制作中,ChatTTS可以用于生成角色对话。其自然的语音和情感表达能力,可以使角色更加生动,提升用户的沉浸感。
未来展望
ChatTTS展示了语音生成技术的巨大潜力。随着技术的不断进步,未来有望在更多的应用场景中发光发热,带给我们更多的惊喜和便利。
免责声明
本文件中的信息仅供学术交流使用,目的在于教育和研究,不得用于任何商业或法律目的。作者不保证信息的准确性、完整性或可靠性。
计划路线
- [x] 开源4w小时基础模型和spk_stats文件
- [ ] 开源VQ encoder和Lora训练代码
- [ ] 在非refine text情况下, 流式生成音频
- [ ] 开源多情感可控的4w小时版本
- [ ] ChatTTS.cpp maybe? (欢迎社区PR或独立的新repo)
常见问题
连不上HuggingFace
请使用modelscope的版本,并设置cache的位置。
我要多少显存?Infer的速度是怎么样的?
对于30秒的音频,至少需要4G的显存。对于4090D,1秒生成约7个字所对应的音频,RTF约0.65。
模型稳定性似乎不够好,会出现其他说话人或音质很差的现象。
这是自回归模型通常都会出现的问题。说话人可能会在中间变化,可能会采样到音质非常差的结果,这通常难以避免。可以多采样几次来找到合适的结果。
除了笑声还能控制什么?还能控制其他情感吗?
在现在放出的模型版本中,只有[laugh]和[uv_break]、[lbreak]作为字级别的控制单元。在未来的版本中我们可能会开源其他情感控制的版本。
致谢
- bark,XTTSv2和valle展示了自回归任务用于TTS任务的可能性。
- fish-speech一个优秀的自回归TTS模型,揭示了GVQ用于LLM任务的可能性。
- vocos作为模型中的vocoder。
特别致谢
- wlu-audio lab为我们提供了早期算法试验的支持。
ChatTTS凭借其先进的技术和广泛的应用前景,正在逐步改变我们的生活方式。从智能客服到教育,再到娱乐,ChatTTS的应用无处不在。期待随着技术的进一步发展,ChatTTS能为我们带来更多惊喜和便利。
参考文献:
-
ChatTTS:一个专为对话场景设计的语音生成模型
近年来,人工智能技术的飞速发展为我们带来了许多创新和便利,其中语音生成技术尤为引人注目。今天,我们要介绍的是一个名为ChatTTS的语音生成模型,它专为对话场景设计,能够在多个应用中展现出色的表现。
什么是ChatTTS?
ChatTTS是一种先进的语音生成模型,专门用于对话场景。与传统的语音生成模型不同,ChatTTS不仅关注语音的自然度和流畅度,还特别注重对话中的上下文理解和情感表达。这使得ChatTTS在模仿人类对话方面具有显著优势。
ChatTTS的技术优势
上下文理解
在对话中,理解上下文是至关重要的。ChatTTS通过复杂的算法和深度学习技术,能够准确地捕捉和理解对话中的上下文信息。这使得它在生成语音时,不仅能够准确传达信息,还能保持对话的连贯性。
情感表达
人类的对话不仅仅是信息的交换,还包含了丰富的情感。ChatTTS在语音生成时,能够根据对话的内容和情境,适当地调整语音的语调和情感。这使得生成的语音更加生动和真实,增强了用户的互动体验。
多样化应用
ChatTTS不仅适用于普通的对话场景,还可以在许多其他领域中发挥作用。例如,在智能客服系统中,ChatTTS可以提供更加自然和亲切的语音服务;在教育领域,ChatTTS可以帮助教师生成生动的教学语音;在娱乐领域,ChatTTS可以用于生成角色对话,提升用户的沉浸感。
实际应用案例
智能客服系统
在智能客服系统中,ChatTTS可以辅助客服人员处理大量的客户咨询。通过其出色的上下文理解能力和情感表达能力,ChatTTS能够生成自然、流畅的语音回复,提升客户的满意度。
教育领域
在教育领域,ChatTTS可以帮助教师制作生动的教学语音材料。无论是课前预习还是课后复习,学生都可以通过听取这些语音材料加深对知识的理解。
娱乐领域
在游戏和影视制作中,ChatTTS可以用于生成角色对话。其自然的语音和情感表达能力,可以使角色更加生动,提升用户的沉浸感。
未来展望
随着人工智能技术的不断进步,语音生成技术将会变得越来越强大和智能。ChatTTS作为这一领域的佼佼者,未来有望在更多的应用场景中发光发热,带给我们更多的惊喜和便利。
ChatTTS的出现,不仅展示了语音生成技术的巨大潜力,也为我们展望了一个更加智能和便捷的未来。无论是在客服、教育还是娱乐领域,ChatTTS都有着广阔的应用前景,值得我们期待。
参考文献:
-
了解 Caddy 的分布式 HTTP 缓存模块
Caddy 是一款功能强大的网络服务器,而
caddyserver/cache-handler模块为其提供了强大的分布式 HTTP 缓存功能。本文将带你了解这个模块的特点、基本配置以及一些高级用法。模块简介
caddyserver/cache-handler是一个基于 Souin 缓存的分布式 HTTP 缓存模块。它具备以下主要特点:- 遵循 RFC 7234 标准的 HTTP 缓存。
- 设置
Cache-StatusHTTP 响应头。 - 提供 REST API 来清除缓存和列出存储的资源。
- 支持 ESI 标签处理(使用
go-esi包)。 - 内置分布式缓存支持。
基本配置
使用最小配置,响应会被缓存 120 秒。以下是一个简单的例子:
{ cache } example.com { cache reverse_proxy your-app:8080 }这个配置中,只需添加
cache指令,所有请求的响应将被缓存 120 秒。全局选项语法
全局选项允许你更细粒度地控制缓存行为。以下是一些常用的配置选项:
{ log { level debug } cache { allowed_http_verbs GET POST PATCH api { basepath /some-basepath prometheus souin { basepath /souin-changed-endpoint-path } } badger { path the_path_to_a_file.json } cache_keys { .*\.css { disable_body disable_host disable_method disable_query headers X-Token Authorization hide } } cache_name Another cdn { api_key XXXX dynamic email darkweak@protonmail.com hostname domain.com network your_network provider fastly strategy soft service_id 123456_id zone_id anywhere_zone } etcd { configuration { # Your etcd configuration here } } key { disable_body disable_host disable_method headers Content-Type Authorization } log_level debug mode bypass nuts { path /path/to/the/storage } olric { url url_to_your_cluster:3320 path the_path_to_a_file.yaml configuration { # Your olric configuration here } } regex { exclude /test2.* } stale 200s ttl 1000s default_cache_control no-store } } :4443 respond "Hello World!"指令选项
缓存指令允许你在更具体的请求路径上应用缓存策略。例如:
@match path /path handle @match { cache { cache_name ChangeName cache_keys { (host1|host2).*\.css { disable_body disable_host disable_method disable_query headers X-Token Authorization } } cdn { api_key XXXX dynamic email darkweak@protonmail.com hostname domain.com network your_network provider fastly strategy soft service_id 123456_id zone_id anywhere_zone } key { disable_body disable_host disable_method disable_query headers Content-Type Authorization } log_level debug regex { exclude /test2.* } stale 200s ttl 1000s default_cache_control no-store } }缓存提供者配置
caddyserver/cache-handler支持多种缓存提供者,包括 Badger、Etcd、NutsDB、Olric 和 Redis。以下是一些示例配置:Badger
badger-path.com { cache { badger { path /tmp/badger/first-match } } }Redis
redis-url.com { cache { redis { url 127.0.0.1:6379 } } }结论
caddyserver/cache-handler模块为 Caddy 提供了强大的分布式 HTTP 缓存能力。通过灵活的配置选项和多种缓存提供者的支持,你可以根据具体需求优化网站性能。如果你正在寻找一种高效的缓存解决方案,这个模块无疑是一个值得尝试的选择。参考文献:GitHub – caddyserver/cache-handler: Distributed HTTP caching module for Caddy
-
Adobe RTMP 规范:实时消息传递协议详解
Adobe 的实时消息传递协议(RTMP),是一种应用层协议,旨在通过适当的传输协议(如 TCP)多路复用和打包多媒体传输流(如音频、视频和交互内容)。以下是对 RTMP 规范的详细解析。
文档概述
文件状态
本文档是 2012 年 12 月 21 日发布的 “Adobe 的实时消息传递协议” 规范的机器可读版本。自 2012 年 PDF 版本以来,规范内容并未发生实质性变化,仅在格式和文字编辑上有所调整。
引言
RTMP 提供了在可靠的流传输(如 TCP)上的双向消息多路复用服务,旨在携带视频、音频和数据消息的并行流,并附带相关的时间信息。实现通常会为不同类别的消息分配不同的优先级,这会影响在传输容量受限时消息入队到底层流传输的顺序。
术语
- MUST: 必须
- REQUIRED: 必需
- SHALL: 应该
- SHOULD: 建议
- MAY: 可以
贡献者
- Rajesh Mallipeddi:原 Adobe Systems 编辑,提供了大部分原始文本。
- Mohit Srivastava:Adobe Systems 贡献者。
定义
- Payload: 包含在数据包中的数据,如音频样本或压缩视频数据。
- Packet: 由固定头和负载数据组成的数据包。
- Port: 传输协议用来区分主机内多个目的地的抽象。
- Transport address: 用于识别传输层端点的网络地址和端口的组合。
字节顺序、对齐和时间格式
- 所有整数字段按网络字节顺序(大端序)传输。
- 时间戳以毫秒为单位,相对于一个未指定的纪元。
RTMP 块流
消息格式
消息格式应包含以下必要字段:
- Timestamp: 消息的时间戳(4 字节)。
- Length: 消息负载的长度(3 字节)。
- Type ID: 消息类型 ID(1 字节)。
- Message Stream ID: 消息流 ID(4 字节,小端序)。
握手
RTMP 连接从握手开始,客户端和服务器各发送相同的三个块(C0、C1、C2 和 S0、S1、S2)。
块化
在握手后,连接多路复用一个或多个块流。每个块流携带一种类型的消息。每个块都有唯一的块流 ID。块的传输顺序必须完整发送。接收端根据块流 ID 重新组装消息。
块格式
每个块由一个头和数据组成。头有三个部分:
- Basic Header: 编码块流 ID 和块类型(1-3 字节)。
- Message Header: 编码关于消息的信息(0、3、7 或 11 字节)。
- Extended Timestamp: 编码完整的 32 位时间戳(0 或 4 字节)。
RTMP 消息格式
消息头
消息头包含以下字段:
- Message Type: 消息类型(1 字节)。
- Length: 负载大小(3 字节)。
- Timestamp: 消息的时间戳(4 字节)。
- Message Stream ID: 消息流 ID(3 字节)。
用户控制消息
RTMP 使用消息类型 ID 4 进行用户控制消息。这些消息包含 RTMP 流层使用的信息。
RTMP 消息类型
命令消息
携带客户端和服务器之间的 AMF 编码命令。命令消息有两个类型值:20 表示 AMF0 编码,17 表示 AMF3 编码。
数据消息
用于发送元数据或用户数据。类型值为 18(AMF0)和 15(AMF3)。
共享对象消息
用于管理多个客户端和服务器之间的分布式数据。类型值为 19(AMF0)和 16(AMF3)。
音频消息
用于发送音频数据,类型值为 8。
视频消息
用于发送视频数据,类型值为 9。
聚合消息
包含一系列RTMP 子消息的单一消息。类型值为 22。
消息交换示例
发布录制视频
此示例说明发布者如何发布流并将视频流发送到服务器。其他客户端可以订阅此发布的流并播放视频。
+--------------------+ +-----------+ | Publisher Client | | | Server | +----------+---------+ | +-----+-----+ | Handshaking Done | | | | | | | ---+---- |----- Command Message(connect) ----->| | | | | |<----- Window Acknowledge Size ------| Connect | | | | |<------ Set Peer BandWidth ----------| | | | | |------ Window Acknowledge Size ----->| | | | | |<----- User Control(StreamBegin) ----| | | | ---+---- |<-------- Command Message -----------| | (_result- connect response) | | | ---+---- |--- Command Message(createStream) -->| Create | | | Stream | | | ---+---- |<------- Command Message ------------| | (_result- createStream response) | | | ---+---- |---- Command Message(publish) ------>| | | | | |<----- User Control(StreamBegin) ----| | | | | |---- Data Message (Metadata) ------->| Publishing| | | Content | |------------ Audio Data ------------>| | | | | |------------ SetChunkSize ---------->| | | | | |<--------- Command Message ----------| | | (_result- publish result) | | | | | |------------- Video Data ----------->| | | | | | | | | | Until the stream is complete | | | |广播共享对象消息
此示例说明在创建和更改共享对象期间交换的消息。它还说明了共享对象消息广播的过程。
+----------+ +----------+ | Client | | | Server | +-----+----+ | +-----+----+ | Handshaking and Application | | connect done | | | | | | | | | | | | | Create and ---+---- |---- Shared Object Event(Use)---->| connect | | | Shared Object | | | ---+---- |<---- Shared Object Event --------| | (UseSuccess,Clear) | | | ---+---- |------ Shared Object Event ------>| Shared object | | (RequestChange) | Set Property | | | ---+---- |<------ Shared Object Event ------| | (Success) | | | ---+---- |------- Shared Object Event ----->| Shared object| | (SendMessage) | Message | | | Broadcast ---+---- |<------- Shared Object Event -----| | (SendMessage) | | | | |从录制流发布元数据
此示例描述了发布元数据的消息交换。
+------------------+ +---------+ | Publisher Client | | | FMS | +---------+--------+ | +----+----+ | Handshaking and Application | | connect done | | | | | | | ---+--- |-- Command Messsage (createStream) ->| Create | | | Stream | | | ---+--- |<-------- Command Message -----------| | (_result - command response) | | | ---+--- |---- Command Message (publish) ----->| Publishing | | | metadata | |<----- UserControl (StreamBegin) ----| from file | | | | |---- Data Message (Metadata) ------->| | |参考文献
- RFC0791: Postel, J., “Internet Protocol”, STD 5, RFC 791, September 1981.
- RFC0793: Postel, J., “Transmission Control Protocol”, STD 7, RFC 793, September 1981.
- RFC1982: Elz, R. and R. Bush, “Serial Number Arithmetic”, RFC 1982, August 199
-
Ubuntu 24.04 推出实时内核,但有一个陷阱
在 Linux 社区中,Ubuntu 一直以来都是一个备受瞩目的发行版。近期,Canonical 宣布了 Ubuntu 24.04 LTS 的发布,其中包含了一个优化用于关键任务应用的实时内核。然而,这一创新背后却有一个关键的限制:它仅对拥有 PRO 订阅的用户开放。
实时操作系统的背景
首先,什么是实时操作系统(RTOS)?简而言之,RTOS 是一种能够在规定时间内处理数据并提供响应的系统,对于那些延迟可能导致严重后果的应用至关重要。与标准操作系统不同,RTOS 优先处理高紧急任务,确保它们在严格的时间限制内执行。
实时内核的技术细节
Ubuntu 24.04 实时内核的核心是基于 Linux 6.8 内核之上的 PREEMPT_RT 补丁,它支持 AMD64 和 ARM64 架构。这个补丁使得 Linux 内核能够以可预测的时间处理操作,将开源操作系统转变为一个强大的实时性能平台。这种内核修改对于需要确定性响应的应用至关重要,因为它最小化了延迟并增强了进程执行的可预测性。
不仅如此,Ubuntu 24.04 的实时内核还优化了对 Raspberry Pi 硬件(特别是 4 型和 5 型)的支持。这一增强扩大了硬件兼容性范围,提高了性能,使其适用于嵌入式系统中的创新实时应用。

限制与争议
然而,当我了解到这个伟大的贡献时,却发现了一个让我大失所望的声明:
“实时 Ubuntu 24.04 LTS 通过 Ubuntu Pro 提供,这是一项 Canonical 的企业安全和合规订阅,个人和小规模商业用途最多可免费使用 5 台机器。”
这个声明引发了我的疑虑。在同一句话中看到“开源”和“订阅”,让我感到难以接受。这种策略类似于 Red Hat 对 RHEL 的做法,Canonical 正在将其创新限制在 PRO 订阅用户之内。虽然这些功能主要面向企业用户,并且没有人被强制使用它们(订阅允许免费使用最多 5 台机器),但问题的核心在于这种做法与开源哲学根本相悖。
当公司将选项置于订阅付费墙后,很难再认真对待它们后来使用的“社区”和“开源”术语。曾经被誉为 Linux 最好的创新之一的 Ubuntu,如今成为了一个引发复杂情感的争议话题。
总结
是的,实时 Ubuntu 24.04 LTS 是一个重大的发展。然而,Canonical 将其设计为主要面向企业用户的付费订阅服务,同时普通 Linux 用户与公司的距离已经如此遥远,似乎难以弥合这一鸿沟。
对于更多详细信息和配置说明,请访问 Ubuntu 官方网站或查看发布日志。
参考文献
- Bobby Borisov, “Ubuntu 24.04 Now Offers a Real-Time Kernel, But There’s a Catch,” Linuxiac, May 30, 2024. 链接
-
Caddy 2.8 Web 服务器:重大改进与更新
Caddy 2.8 作为一个强大的跨平台开源 Web 和反向代理服务器,已经正式发布了。这次发布带来了许多令人瞩目的改进,包括对 ACME Renewal Information (ARI) 的支持、通过 HTTP/3 代理到后端的功能以及核心依赖项的重要改进,如 ACMEz 和 CertMagic。
主要改进概览
证书处理方式的变化
在之前的版本中,Caddy 自动使用 Let’s Encrypt 和 ZeroSSL 提供证书而无需配置。然而,在新版中,由于 ZeroSSL 政策的变化,用户现在必须在配置中包含电子邮件地址以继续使用 ZeroSSL。这一调整虽然与 Caddy 过去几年的推荐一致,但可能需要一些用户进行配置更新以维持当前设置。
核心技术的升级
开发人员对 Caddy 的底层技术进行了精细优化,包括 CertMagic 和 ACMEz 的重大升级,这对证书管理和自动化至关重要。这些变化虽然对终端用户来说可能不太明显,但对于在高流量环境中增强 Caddy 的操作效率至关重要。
新功能与弃用功能
Caddy 2.8 引入了多个重要的破坏性更改:
- ZeroSSL 发行模块不再具备 ACME 能力;它需要 API 密钥才能继续使用。
- lego_deprecated DNS 提供模块已被移除,取而代之的是更灵活、更精简的 caddy-dns 模块。
- 一些过时的选项,如 remote_ip 匹配器中的 forwarded 选项,已被移除,推动用户采用新的配置。
用户体验的提升
Caddy 2.8 非常重视用户体验,许多改进直接来源于社区反馈。这些改进包括配置简化和文档更新,这些文档将在 Caddy 网站上很快更新,以反映新的变化。
此外,发布日志中还列出了许多较小的更新,供用户查看。
总结
Caddy 2.8 版本不仅在功能上进行了重大更新,还在用户体验和操作效率上进行了全面提升。对于那些依赖 Caddy 进行高流量管理和自动化证书管理的用户来说,这些改进将是非常有价值的。
更多详细更新和配置说明,请访问 Caddy 官方网站或查看发布日志。
参考文献
- Bobby Borisov, “Caddy 2.8 Web Server Is Here with Many Improvements,” Linuxiac, May 30, 2024. 链接
-
探索 Caffeine:Java 高性能缓存框架
在现代应用程序中,缓存是提升性能和降低响应时间的关键技术之一。Caffeine作为一种高性能的Java缓存框架,因其出色的性能和灵活性,逐渐成为开发者的首选。本文将带您深入了解Caffeine的工作原理和使用方法。
什么是Caffeine?
Caffeine是一个为Java应用设计的缓存库,旨在提供高效、灵活和易用的缓存机制。它由Google Guava Cache的作者Ben Manes主导开发,并在性能和功能方面进行了大量改进。
主要特性
- 高性能:Caffeine采用先进的缓存算法,如LRU(最近最少使用)和LFU(最少频繁使用),在性能和内存使用上都有显著提升。
- 灵活配置:支持多种缓存策略和配置选项,满足不同应用的需求。
- 统计信息:提供丰富的缓存统计信息,帮助开发者监控和优化缓存性能。
Caffeine 的工作原理
Caffeine的核心是基于Window TinyLfu算法,这是一种结合了LRU和LFU优点的缓存算法。该算法通过一个小窗口来记录最近访问的对象,同时维护一个频率计数器,以便在缓存满时进行精准的淘汰。
缓存策略
Caffeine支持多种缓存策略,包括:
- 弱引用和软引用:用于缓存具有不同生命周期的对象。
- 自动刷新:定期刷新缓存内容,确保数据的时效性。
- 异步加载:支持异步数据加载,减少主线程的负载。
使用Caffeine进行缓存
Caffeine的使用非常简便,只需几行代码即可创建一个高效的缓存。下面是一个简单的示例:
import com.github.benmanes.caffeine.cache.Cache; import com.github.benmanes.caffeine.cache.Caffeine; import java.util.concurrent.TimeUnit; public class CaffeineExample { public static void main(String[] args) { // 创建一个缓存实例 Cache<String, String> cache = Caffeine.newBuilder() .expireAfterWrite(10, TimeUnit.MINUTES) // 设置写入后10分钟过期 .maximumSize(100) // 设置最大缓存大小为100 .build(); // 向缓存中放入值 cache.put("key1", "value1"); // 从缓存中获取值 String value = cache.getIfPresent("key1"); System.out.println("Cached value: " + value); } }配置选项
Caffeine提供了丰富的配置选项,开发者可以根据实际需求进行灵活调整:
- expireAfterWrite:指定写入后多久过期。
- expireAfterAccess:指定访问后多久过期。
- maximumSize:指定缓存的最大条目数。
- refreshAfterWrite:指定写入后多久刷新。
统计和监控
Caffeine还提供了全面的统计功能,帮助开发者监控缓存的性能和使用情况。通过调用
recordStats方法,可以启用统计功能:Cache<String, String> cache = Caffeine.newBuilder() .expireAfterWrite(10, TimeUnit.MINUTES) .maximumSize(100) .recordStats() // 启用统计功能 .build(); // 获取统计信息 System.out.println("Cache hit rate: " + cache.stats().hitRate());结语
Caffeine作为一个高性能、灵活的Java缓存框架,凭借其先进的缓存算法和丰富的配置选项,已经成为许多开发者的首选。如果您正在寻找一种高效的缓存解决方案,不妨试试Caffeine,它不仅能大幅提升应用性能,还能简化缓存管理的复杂度。
参考文献:
深入了解 Caffeine 的
refreshAfterWrite()方法在缓存系统中,数据的新鲜度和一致性是非常重要的。Caffeine提供了
refreshAfterWrite()方法,允许开发者在缓存项过期前自动刷新缓存数据,从而保证数据的时效性。本文将详细介绍这一方法的作用和使用方式。什么是
refreshAfterWrite()?refreshAfterWrite()是Caffeine提供的一个方法,用于在缓存项写入后指定时间内自动刷新缓存数据。这种机制确保了缓存中的数据不会长期陈旧,而是能够定期更新。工作原理
当某个缓存项达到指定的刷新时间后,下一次访问该项时,Caffeine将异步地加载新的数据并更新缓存。与
expireAfterWrite()不同的是,refreshAfterWrite()不会在刷新时间到达后立即移除缓存项,而是保持旧数据可用,直到新数据加载完成。主要应用场景
- 频繁变化的数据:适用于数据频繁变化的场景,需要定期刷新以保持数据的最新状态。
- 有限的缓存访问延迟:适用于需要快速访问缓存数据的场景,避免了过期数据导致的缓存未命中问题。
使用
refreshAfterWrite()的代码示例下面是一个示例代码,展示了如何使用
refreshAfterWrite()方法来定期刷新缓存数据:import com.github.benmanes.caffeine.cache.Cache; import com.github.benmanes.caffeine.cache.Caffeine; import com.github.benmanes.caffeine.cache.LoadingCache; import java.util.concurrent.TimeUnit; public class CaffeineRefreshExample { public static void main(String[] args) { // 创建一个缓存实例,并配置refreshAfterWrite LoadingCache<String, String> cache = Caffeine.newBuilder() .expireAfterWrite(10, TimeUnit.MINUTES) // 设置写入后10分钟过期 .refreshAfterWrite(1, TimeUnit.MINUTES) // 设置写入后1分钟刷新 .maximumSize(100) // 设置最大缓存大小为100 .build(key -> loadData(key)); // 指定数据加载方式 // 向缓存中放入值 cache.put("key1", "value1"); // 从缓存中获取值 String value = cache.get("key1"); System.out.println("Cached value: " + value); // 模拟等待1分钟后再次访问,触发刷新 try { Thread.sleep(60000); } catch (InterruptedException e) { e.printStackTrace(); } // 再次访问缓存,触发刷新 value = cache.get("key1"); System.out.println("Refreshed value: " + value); } // 模拟数据加载方法 private static String loadData(String key) { // 这里可以是从数据库或其他数据源加载数据的逻辑 return "new_value_for_" + key; } }代码解释
- 创建缓存实例:使用
Caffeine.newBuilder()创建一个缓存实例,并配置expireAfterWrite和refreshAfterWrite。 - 数据加载方式:通过
build(key -> loadData(key))指定数据加载方式,这里模拟了一个从数据源加载数据的方法。 - 刷新机制:缓存项在写入后1分钟会自动刷新,并在下一次访问时异步加载新数据。
结语
refreshAfterWrite()是Caffeine提供的一种强大功能,能够确保缓存中的数据始终保持最新状态。在实际应用中,合理配置refreshAfterWrite()可以有效提升缓存的性能和数据的可靠性。如果您正在开发需要频繁更新数据的应用,不妨尝试使用这一方法来优化您的缓存策略。
参考文献:
-
探秘 JVM 中的 TLAB:加速内存分配的利器
在Java世界中,内存管理一直是一项关键任务。为了提高内存分配效率,JVM引入了线程本地分配缓冲区(Thread Local Allocation Buffer,简称TLAB)。那么,TLAB究竟是如何运作的,它又为何如此重要呢?本文将为您揭开这一神秘面纱。
什么是 TLAB?
TLAB 是一种专门为每个线程分配的内存区域。通常,JVM中的堆内存是所有线程共享的,但这种共享机制会带来竞争和锁争用的问题,从而影响性能。TLAB通过为每个线程分配独立的小块内存,避免了线程之间的竞争,提高了内存分配的速度。
TLAB 的大小
TLAB的大小并不是固定的,而是根据线程的需求动态调整。JVM会根据当前线程的内存分配速率和对象大小,自动调整TLAB的大小。这种动态调整机制确保了内存的高效利用,同时避免了内存浪费。
TLAB 的工作原理
当一个线程需要分配内存时,它首先会尝试在自己的TLAB中分配。如果TLAB中有足够的空间,那么内存分配将非常快速,因为不需要任何锁操作。只有当TLAB中的空间不足时,线程才会回到共享的堆内存中进行分配。
内存分配流程
- 检查 TLAB:线程首先检查自己的TLAB是否有足够的空间来分配新的对象。
- 分配内存:如果TLAB有足够的空间,直接在TLAB中分配内存。
- 扩展 TLAB:如果TLAB空间不足,线程会请求一个新的TLAB,或者直接在共享的堆内存中分配。
TLAB 的优势
提高内存分配速度
由于TLAB是线程私有的,因此在分配内存时不需要任何同步操作,这大大提高了内存分配的速度。根据实际测试,使用TLAB可以使内存分配的速度提高10倍以上。
减少内存碎片
TLAB的分配和释放都是线程局部的,因此可以有效减少内存碎片。每个线程在自己的TLAB中分配和释放内存,避免了不同线程间的内存碎片问题。
提高垃圾回收效率
由于TLAB是线程私有的,垃圾回收器可以更高效地识别可回收的内存。这不仅提高了垃圾回收的效率,还减少了垃圾回收的频率。
如何配置 TLAB
在JVM中,可以通过一些参数来配置TLAB的行为:
-XX:+UseTLAB:开启TLAB(默认开启)。-XX:TLABSize:设置TLAB的初始大小。-XX:+ResizeTLAB:允许JVM动态调整TLAB的大小(默认开启)。
通过这些参数,开发者可以根据实际需求优化TLAB的配置,从而进一步提高应用的性能。
结语
TLAB 是 JVM 内存分配机制中的一项重要优化。通过为每个线程分配独立的内存区域,TLAB不仅提高了内存分配的速度,还减少了内存碎片,并提高了垃圾回收的效率。如果您正在开发高性能的Java应用,不妨深入了解并合理配置TLAB,以充分发挥其优势。
参考文献:
-
LLMs与多模态生成及编辑:一项综述
引言
内容概述
近年来,随着大型语言模型(LLMs)的快速发展,越来越多的研究开始关注将LLMs与多模态学习相结合。以往的多模态大语言模型(MLLMs)研究主要集中在理解上,而本综述将详细探讨多模态生成领域,涵盖图像、视频、3D和音频等多个领域,并重点介绍这些领域中的里程碑式工作。
研究范围
本综述探讨了包括图像、视频、3D模型和音频在内的多种模态的生成。多模态生成包括不同模态的单独生成以及多模态的联合生成。我们不会深入讨论纯文本生成,因为已有许多专门针对该领域进展的综述。我们的主要关注点是近年来出现的大型语言模型如何在生成其他视觉和音频模态方面提供帮助,特别是在开放领域生成中的应用。
相关研究
单模态生成综述
许多综述文章专注于单一模态的生成,例如图像生成[115]、视频生成[116]、3D生成[117]和音频生成[118]。这些研究主要采用预训练的CLIP或T5等语言编码器进行开放领域的文本指导生成。随着LLMs的出现,越来越多的生成工作利用强大的LLMs来增强每种模态的生成能力。我们的工作主要讨论LLMs在各个模态生成中的作用,这是以前的综述中缺乏的。
LLMs综述
大量综述文章探讨了LLMs的各个方面。例如,[121]对基于LLMs的自主代理进行了全面审查。此外,[122]和[123]介绍了多模态LLMs,介绍了将LLMs与其他非文本模态结合的论文。这些综述既介绍了多模态理解,也介绍了多模态生成,但主要侧重于多模态理解。相比之下,我们的工作主要集中在生成方面,旨在探讨LLMs在每种模态生成过程中带来的性能和功能改进。
预备知识
生成模型
生成模型可以归纳为从先验分布中抽取潜在样本并将其转换为与目标数据分布对齐的生成样本的过程。以下是几种主要的生成模型:
- 生成对抗网络(GANs):GAN由生成器和判别器组成,其中生成器生成假样本,判别器区分真假样本。两者通过博弈论进行训练。[124]
- 变分自编码器(VAEs):VAEs包含编码器和解码器,通过潜在空间变量的分布来学习输入数据的表示。[125]
- 基于流的模型:这些模型使用一系列可逆变换,将数据分布逐步变换为简单的先验分布。[126]
- 扩散模型:扩散模型通过一系列去噪任务实现复杂生成过程,近年来在生成任务中取得了显著进展。[128]
- 自回归模型:这些模型通过依赖于过去值来预测未来值,广泛用于时间序列预测、语音合成和自然语言处理。[129]
多模态对齐模型
CLIP[23]是一种开创性的图像-语言对齐模型,通过对比学习同时学习图像编码器和文本编码器。它在多个下游任务中表现出色,如物体识别和视频动作识别。CLAP[131]则对齐文本和音频信息,用于文本指导的音频生成。
大型语言模型
现代大型语言模型利用Transformer架构生成上下文丰富的嵌入,这些模型在大量文本语料库上进行训练,然后针对特定任务进行微调。[137][138][139][140] 例如,GPT系列模型主要使用Transformer解码器,经过大规模多样化数据集的预训练后,能够生成高质量的文本。
多模态大型语言模型
多模态大型语言模型(MLLMs)最近开始兴起,旨在赋予LLMs理解或生成其他模态的能力。这些模型通常包含额外的预训练模态特定编码器,用于特征提取和输入投影,以及与LLM骨干对齐的多模态隐藏特征。[142][143][144][145][146]
图像生成与编辑
图像生成
使用CLIP进行文本指导的图像生成
过去,图像-文本对齐模型如CLIP[23]在文本指导的图像生成中发挥了重要作用,确保生成的图像与给定的文本提示相符。这些模型通过对齐文本编码器和图像编码器的嵌入,生成与文本描述相匹配的图像。[12][169][200][10][201][202]
使用LLMs进行文本指导的图像生成
随着MLLMs的发展,LLMs在视觉内容处理中的应用越来越广泛。MLLMs提供了统一的界面,用于理解和生成文本及视觉信息,增强了生成过程的交互性和可控性。例如,CM3Leon是一种自回归MLLM,能够同时生成文本和图像输出[156]。DreamLLM是第一个能够生成自由形式交错内容的MLLM,支持多轮对话,并且在图像描述和视频问答任务中表现出色[151]。这些模型通过结合视觉和语言信息,显著提高了图像生成的质量和用户体验。
图像编辑
使用CLIP/T5进行图像编辑
CLIP模型支持基于语言的图像编辑,例如SDEdit通过用户输入的描边、草图或掩码生成逼真的图像,并通过文本指令编辑现有图像。[226] DiffusionCLIP[227]和Imagic[231]等方法通过调整预训练的扩散模型来编辑目标图像,展示了出色的编辑能力。
使用LLMs进行图像编辑
LLMs提供了强大的基于对话或交互的图像编辑能力。例如,InstructPix2pix通过构建数据元组(原始图像、提示、目标图像),训练模型根据编辑提示编辑图像[242]。CHATEDIT则通过对话进行面部图像编辑,分解为用户编辑请求跟踪、图像编辑和响应生成子任务[243]。这些方法通过结合LLMs强大的文本理解和生成能力,显著提高了图像编辑的精确度和灵活性。
视频生成与编辑
视频生成
使用CLIP进行文本到视频生成
基于扩散模型和变压器模型的文本到视频生成方法已经取得了显著进展。扩散模型因其训练的简便性成为主流,其中包括像素级和潜在级视频扩散模型。[14][15][16][17] 这些模型通过逐帧生成视频,确保生成的视频与文本提示一致。
使用LLMs进行文本到视频生成
最近的一些研究利用MLLMs进行视频生成。例如,VideoPoet利用预训练的自回归变压器模型处理多模态数据,生成时间一致且运动保真度高的视频[69]。MAGVIT-v2探索了MLLMs的标记化技术,将视觉输入转换为离散标记,增强了大型语言模型在图像和视频生成任务中的性能[70]。
视频编辑
使用CLIP/T5进行文本指导的视频编辑
Tune-A-Video提出了一种基于预训练扩散模型的文本指导视频编辑方法,通过对目标视频进行单次调优,实现多种视频编辑功能[246]。Video-P2P和FateZero等方法通过更好的反演技术和注意力图操作,确保在编辑过程中背景保持不变,提高了编辑的时间一致性[248][249]。
使用LLMs进行文本指导的视频编辑
目前利用LLMs进行视频编辑的研究相对较少。InstructVid2Vid通过生成合成的视频指令对,提高了可控视频编辑的多样性和现实性[258]。InsV2V扩展了InstructPix2Pix的范式,使用LLMs构建合成数据,用于训练视频编辑模型[257]。
3D生成与编辑
3D生成
使用CLIP/T5进行3D生成
利用CLIP的多模态表示能力,可以通过文本描述或查询指导3D资产的生成和编辑。Text2Mesh通过预测颜色和局部几何细节,生成符合目标文本提示的3D网格[26]。DreamFusion则利用SDS损失从预训练的文本到图像生成模型中提取3D资产,显著提高了生成质量[41]。
使用LLMs进行3D生成
LLMs与3D资产的结合是一个新兴的研究方向,利用LLMs强大的语言理解能力,通过文本指令直接增强3D资产的生成、操作或理解。
例如,3D-GPT提出了一种训练自由的框架,包含任务调度、概念化和建模代理,通过这些代理,可以生成与语言对应的Blender代码,从而提高最终用户在程序化3D建模中的效率[80]。SceneCraft引入了一个LLM代理,通过生成Blender脚本,将输入的文本查询转换为3D场景[341]。此外,PointLLM结合人类指令处理有色点云,并利用LLMs预测用户问题的响应[342]。
3D编辑
使用CLIP/T5进行3D编辑
Blended-NeRF[344]提出了一种使用CLIP损失修改现有NeRF场景中特定感兴趣区域的框架,允许通过对比学习进行目标区域的编辑。NeRF-Art通过全局-局部对比学习策略,对预训练的NeRF模型进行风格化[27]。TextDeformer通过引入基于雅可比矩阵的网格变形技术,实现了基于文本的几何变形[345]。
使用LLMs进行3D编辑
目前,利用LLMs进行3D编辑的方法相对较少。编辑更多地像是LLMs生成的一个子任务。例如,3D-GPT和SceneCraft都可以直接编辑3D资产[80][341]。我们将继续关注LLMs在3D编辑中的最新发展,并在未来进行讨论。
小结
通过将CLIP或LLMs与3D资产结合,用户可以用自然语言表达他们的创意意图或期望的修改,简化了交互过程,减少了对专业软件或技术专长的需求。此外,将文本信息整合到3D生成管道中,提高了生成输出的可解释性和可调节性,使用户能够更好地理解和微调结果。
音频生成、理解与编辑
领域
音频生成、理解和编辑领域的研究已经取得了显著的进展。以下是LLMs在这些领域的主要角色:
LLMs在音频生成、理解和编辑中的角色
- 作为骨干(Backbone):LLMs作为复杂系统的核心架构,用于处理文本和音频标记。例如,AudioLM利用离散标记将音频生成看作是语言建模任务[110]。
- 作为调节器(Conditioner):LLMs作为文本编码器,将输入文本编码为条件,从而引导系统的响应或输出。例如,TANGO使用FLAN-T5作为文本编码器,生成音频的潜在表示[98]。
- 作为标签器(Labeller):LLMs将类别标签转换为音频描述,用于数据增强和自动音频标注。例如,Wu等人通过结合预训练模型和LLMs,改进了自动音频描述[99]。
- 作为代理(Agent):LLMs与各种工具进行交互,管理和执行复杂的多维操作。例如,AudioGPT利用ChatGPT作为中心节点,处理音频和语音应用[104]。
- LLMs启发的骨干(Inspired Backbone):使用LLMs的架构对离散音频标记进行建模。例如,VALL-E结合自回归和非自回归语言模型对编码标记进行建模[53]。
音频生成
音频生成领域的研究重点在于生成多样化和复杂的音频内容。例如,Make-an-Audio 2[100]和WavJourney[105]通过结合多模态方法,实现了高保真音频生成。AudioLM通过将输入音频转换为离散标记,模拟语言建模任务,生成高质量音频[110]。
音频理解
音频理解涉及对环境中各种声音的分析和解释,包括识别和分类声音、模式识别以及理解声音的上下文或来源。LTU[85]和SALMONN[91]通过结合LLMs和音频编码器,提高了音频理解的能力。AudioGPT和HuggingGPT通过协调工具,提升了音频理解的交互能力[104][103]。
音频编辑
音频编辑涉及对音频元素的实时调整和修改。例如,Loop Copilot结合LLMs和专用AI音乐模型,创建了一个协作人机音乐循环创作的对话界面[107]。
工具增强的多模态代理
动机
LLMs有时无法处理其训练数据中未包含的信息,如实时数据或私人数据。为了克服这些限制,许多研究提出通过API或外部工具增强LLMs,例如检索增强生成(RAG)和视觉基础模型。这些工具可以通过自然语言指令调用,并将结果整合到LLMs的输出中。例如,LLMs可以使用天气API获取某地的当前温度和湿度,并将其用于生成自然语言响应。
多模态代理通过增强LLMs的功能,使其能够生成和编辑图像、视频和音频,从而实现更自然和多样化的人机交互以及更强大的创意应用。
方法
工具增强的LLMs多模态交互框架一般包括三个主要阶段:
- 任务规划:LLM作为控制器,将自然语言指令解释为工具调用方案。核心目标是决定使用哪些工具,并为工具准备参数。
- 任务执行:主机中包含多个外部多模态工具,例如图像生成、视频编辑或音频合成。工具的调用基于任务规划阶段获得的调用方案。
- 响应生成:通过提示LLM,将任务执行的输出生成用户友好的响应。
现有方法主要分为两类:
无需训练的方法
这些方法主要依赖提示工程和上下文学习,以增强LLMs的推理能力。例如,VISPROG和Visual ChatGPT通过生成代码或直接调用视觉基础模型,解决复杂的组合视觉任务[219]。HuggingGPT使用分阶段规划和模型选择,通过调用Hugging Face上的多种模型,整合多模态任务的预测结果[103]。
指令调优的方法
这些方法通过训练语言模型更精确地遵循人类指令,从而显著提高了工具使用的能力。例如,GPT4Tools通过自指令生成大量多模态上下文和工具描述,训练LLMs使用工具进行各种视觉任务[402]。ModelScope-Agent结合工具检索模块,增强了开源LLMs的工具使用能力[418]。
演示
一些多模态代理不仅开源代码,还发布了在线演示,展示其功能。例如,Visual ChatGPT和HuggingGPT可以生成和编辑图像,并通过调用图像生成或编辑模型(如Stable Diffusion和ControlNet)根据文本提示创建或修改图像[217][103]。InternGPT和ControlLLM通过支持指点设备,增强了交互性,用户可以通过点击选择感兴趣的区域进行编辑[218][407]。
小结
工具增强的多模态代理在提升人机交互的自然性和多样性方面具有重要意义。这些方法通过结合外部工具,显著增强了LLMs的能力,但也面临着如何生成多样化和高质量指令语料库以及如何在闭合语料库中训练的模型上进行泛化等挑战。
生成AI的安全性
生成模型的安全性问题引起了越来越多的关注,研究主要集中在减少偏见和有害内容的生成、保护版权以及缓解生成模型产生的虚假内容带来的影响。
攻击与防御
研究包括基于优化的攻击、提示级别的操作和数据中毒方法:
- 基于优化的攻击:展示了对模型性能造成负面影响或诱导偏见和有害输出的对抗技术[430][431]。
- 提示级别攻击:揭示了在推理阶段人造输入绕过安全措施并引发不安全输出的风险[440][441]。
- 数据中毒方法:暴露了通过注入恶意数据输入操纵模型的可能性[444][445]。
防御与检测
防御方法主要包括两种:
- 检测机制:不修改模型参数,通过检测机制或操控输入提示上下文来防御。例如,Latent Guard通过在潜在空间中检测不安全输入提示,比传统的黑名单方法更具鲁棒性[449]。
- 对齐算法:通过对齐算法将模型与人类偏好或价值观对齐。Proximal Policy Optimization(PPO)算法广泛用于对齐LLMs,Direct Preference Optimization(DPO)和相关方法通过直接从偏好数据中学习对齐,提供了更高效的对齐算法[451][452]。
此外,生成模型的安全性评估还包括防止多模态生成模型生成虚假内容和嵌入水印的技术,以保护版权[465][466][467]。
数据集
为了评估生成AI的安全性,研究人员开发了一系列数据集:
- SafetyBench:一个多选题数据集,用于评估生成内容的安全性,包含7个安全类别的11,435个条目[468]。
- GOAT-Bench:评估不安全表情包的多样化话题数据集,包括隐含仇恨言论、性别歧视和网络欺凌等[469]。
- ToViLaG:专为视觉LLMs设计的数据集,解决生成的不当内容,如冒犯性文本和不适当的图像[470]。
这些数据集为进一步提高生成模型的安全性提供了全面的评估。
小结
通过先进的检测和数据算法技术,生成模型的安全性得到了显著提升。开源项目提供的安全检查功能,为用户提供了更安全的使用体验。水印嵌入和数据追踪技术在保护版权方面也取得了显著进展。采用这些安全技术的公共项目,将增强多模态生成应用的安全性和可信度。
应用
图像
在图像生成领域,扩散模型的发展极大地提高了合成图像的质量和真实性,催生了许多高质量的文本到图像生成工具和多模态条件图像编辑或生成解决方案。例如:
- Midjourney:提供高质量、真实感强的图像生成工具,广泛应用于内容创作和设计[473]。
- Stability AI:提供强大的开源生成模型,用户社区开发了各种使用方法,使得图像生成模型得以广泛应用[474]。
- DALLE-3:集成了图像生成能力到ChatGPT4聊天机器人中,通过文本提示生成和修改图像[152]。
这些工具通过结合LLMs改进生成图像的质量和用户体验,展示了LLMs在图像生成中的巨大潜力。
视频
随着大规模视频生成模型的出现,用户可以通过输入文本描述生成高质量的视频片段。例如:
- Pika和Runway’s Gen2:提供商业化的视频生成工具[478][479]。
- AnimateDiff和VideoCrafter:开源的视频生成模型[20][19]。
这些工具降低了电影和电视行业的视频制作成本,展示了LLMs在视频生成中的应用前景。
音频
在音频生成领域,LLMs的应用已经取得了显著进展,涵盖了文本到语音生成、声音传输、音乐生成等多个方面。例如:
- Microsoft Azure:在语音生成领域处于领先地位,推动了AI生成声音在短视频平台中的应用[481]。
- Descript:基于AI的音频和视频编辑工具,可以将音频和视频中的语音转录为文本,用户可以像编辑Word文档一样修改音频和视频[482]。
此外,音乐生成也是一个热门领域,例如:
- Suno AI:用户可以通过提供文本提示生成高质量的歌曲[483]。
- Stability Audio和Google’s MusicFX:提供音乐生成产品,进一步扩展了音频生成的能力[484][485]。
3D
3D模型生成在电影、游戏、工业设计、建筑等领域具有重要应用。例如:
- Meta和Epic Games’ MetaHuman Creator:在3D建模和虚拟现实技术方面取得了显著进展[488][489]。
- Luma AI和Adobe:通过生成3D模型或将2D图像转换为3D模型,简化了3D内容的创建过程[490][491]。
此外,Wonder Studio提供了强大的AI工具,可以在视频中替换角色,为个性化内容创建提供了新的可能性[493]。
其他
AI驱动的软件需要处理各种模态的输入数据,生成AI在数学、法律、教育和机器人等领域的应用前景广阔。例如,AI生成的电影结合3D技术用于视频、音乐和语音生成,与人类艺术家合作,创造高质量的电影体验。
未来展望
技术展望
高分辨率生成
高分辨率多模态生成在虚拟现实、电影制作等领域至关重要,提高了生成内容的质量和用户体验。LLMs可以通过更好地理解复杂指令和生成更准确、多样化的输出,解决高分辨率生成的挑战。近期在不同模态(如图像、视频、3D和音频)生成方面的进展显著提高了生成内容的质量。未来的研究可以通过结合LLMs,进一步提升高分辨率内容的生成能力。此外,高分辨率内容生成通常需要大量的硬件资源和时间成本,因此高效的生成策略也值得深入研究。
长期序列生成
长期序列生成对视频和音频的沉浸式体验至关重要。在视频方面,它可以描绘连续的场景和叙事,而在音频方面,它支持音乐和对话的持续发展。LLMs通过捕捉复杂的模式和依赖关系,生成连贯且上下文相关的长期序列,从而提升生成内容的连贯性和一致性。未来的研究可以通过微调预训练的LLMs,并结合多模态数据集,生成跨不同模态的连贯长序列。
更精确和细粒度的生成控制
精确和细粒度的生成控制是AIGC中的一个重要课题。它不仅可以生成更真实和高质量的多模态内容,还可以促进人机交互的有效性。LLMs通过更好地理解控制信号中的细微差别,提高控制信号与生成内容之间的匹配度。例如,在图像或视频中进行文本渲染时,强大的语言模型可以显著提升拼写能力和生成质量。
多视角一致性
多视角一致性(MVC)在3D生成中尤为重要,确保对象从不同视角观察时的外观一致性。MVC对增强用户在增强现实(AR)、虚拟现实(VR)和计算机图形学中的体验至关重要。近期的研究在3D生成中引入了稀疏3D先验和扩散采样技术,以增强一致性并解决复杂几何体的生成问题。未来的研究可以结合LLMs,通过提供更多的先验知识,提高多视角一致性和生成质量。
多模态生成的统一训练
多模态生成是指同时生成包括图像、视频、3D对象和音频在内的多种模态内容。当前的大多数方法仅关注单一模态的生成,而统一训练多模态生成模型的研究相对较少。通过特征对齐和联合训练,可以实现统一的多模态生成模型,进一步提升生成内容的多样性和连贯性。
高效的训练和部署策略
随着数据集和模型规模的不断扩大,高效的训练和部署策略变得愈加重要。低秩近似技术和混合精度训练等方法在加速训练和降低计算成本方面表现出色。未来的研究可以进一步优化这些技术,并探索量化方法以提高推理效率和模型部署的可扩展性。
伦理安全的内容生成
生成模型的安全性一直是研究的热点,尤其是视频生成模型的能力不断增强,带来了更多的社会风险。未来的研究需要综合利用检测、对齐和后处理检查技术,确保生成模型的安全性和鲁棒性。
应用展望
语义音频合成
语义音频合成涉及根据语义描述或上下文线索生成音频信号,创造具有特定特征或属性的沉浸式听觉体验。例如,基于文本描述的声音景观或音乐作品可以通过多模态生成模型转化为音频波形,增强多媒体内容的现实感和丰富性。
多模态叙事
多模态叙事通过融合不同模态来创造引人入胜的叙事,提供多感官交互。例如,基于文本提示生成图像序列、视频片段或音频叙事,实现更加沉浸式的叙事体验。
交互式内容设计
交互式内容设计旨在实时创建和操控媒体元素,使用户能够积极参与创作过程。多模态生成模型通过提供实时的交互和操控能力,提高创作效率和灵活性,降低创作门槛。
3D场景生成
3D场景生成在虚拟世界、游戏、仿真和建筑可视化中具有重要应用。多模态生成模型可以通过文本描述或概念草图生成复杂的3D场景,减少手动建模的需求,加速设计过程。
可定制化虚拟角色
可定制化虚拟角色是用户可以根据个人偏好和特征进行个性化和调整的数字化身。多模态生成模型通过生成多样化的媒体类型(如图像、文本和音频)来创建逼真的虚拟角色。例如,生成模型可以根据文本描述生成虚拟角色的头像、服饰和表情,并通过语音合成技术使角色能够进行自然的对话。以下是几个具体应用:
未来展望
语义音频合成
语义音频合成涉及根据语义描述或上下文线索生成音频信号,创造具有特定特征或属性的沉浸式听觉体验。多模态生成模型通过结合文本和图像等多模态数据,可以生成更丰富和个性化的音频内容,用于娱乐、教育和虚拟现实等领域。例如,基于文本描述的声音景观或音乐作品可以通过多模态生成模型转化为音频波形,增强多媒体内容的现实感和丰富性。
多模态叙事
多模态叙事通过融合不同模态来创造引人入胜的叙事,提供多感官交互。例如,基于文本提示生成图像序列、视频片段或音频叙事,实现更加沉浸式的叙事体验。多模态生成模型支持从文本到图像、视频和音频的多方向合成,使得故事情节更加生动和多样化。
交互式内容设计
交互式内容设计旨在实时创建和操控媒体元素,使用户能够积极参与创作过程。多模态生成模型通过提供实时的交互和操控能力,提高创作效率和灵活性,降低创作门槛。例如,用户可以通过文本指令实时生成和编辑图像、视频和音频,快速实现创意。
3D场景生成
3D场景生成在虚拟世界、游戏、仿真和建筑可视化中具有重要应用。多模态生成模型通过文本描述或概念草图生成复杂的3D场景,减少手动建模的需求,加速设计过程。例如,设计师可以通过简单的文本描述生成建筑和室内设计的3D模型,快速进行迭代和优化。
可定制化虚拟角色
可定制化虚拟角色是用户可以根据个人偏好和特征进行个性化和调整的数字化身。多模态生成模型通过生成多样化的媒体类型(如图像、文本和音频),创建逼真的虚拟角色。例如,生成模型可以根据文本描述生成虚拟角色的头像、服饰和表情,并通过语音合成技术使角色能够进行自然的对话。
世界模型的未来
世界模型(World Models)是当前的热门话题,许多研究人员认为世界模型将在不久的将来成为现实。世界模型涉及感知、理解和生成多模态信息,为实现更智能的人工智能系统提供了可能性。以下是几个核心应用:
多模态教育和沟通
世界模型在教育和沟通中具有巨大潜力,通过提供多模态学习体验和沉浸式互动,促进学习和交流。例如,学生可以通过虚拟现实和增强现实技术,在沉浸式环境中学习复杂的概念和技能。多模态生成模型可以生成个性化的教育内容,满足不同学习风格和需求。
电影生成
世界模型在电影生成中代表了一种范式转变,为电影制作人提供了前所未有的创作自由和灵活性。多模态生成技术使得电影制作人能够无缝整合对话、视觉效果、声音效果和音乐,打造身临其境的电影体验。此外,世界模型可以生成动态和个性化的叙事,满足观众的个性化需求,增强观众的参与感和沉浸感。
元宇宙
元宇宙的出现为利用世界模型创建沉浸式和互动的虚拟世界提供了无限可能。通过合成多模态感官体验,包括视觉、听觉和触觉反馈,这些模型能够创建高度真实和沉浸的虚拟环境,模糊物理现实和数字现实之间的界限。此外,世界模型促进了智能虚拟代理和非玩家角色(NPC)的开发,使其表现出逼真的行为和互动,增强了元宇宙中的社交沉浸感。
结论
在本综述中,我们系统地回顾了LLMs在多模态生成和编辑中的应用,涵盖了图像、视频、3D和音频等多个领域。通过详细分析这些技术的进展和应用,我们希望为未来的研究提供指导,并推动人工智能在生成内容方面的发展。总的来说,我们期待我们的调查能为多模态生成,特别是世界模型的发展提供洞见和启发,这一领域正逐渐吸引越来越多的研究人员的关注和期待。
参考文献
- OpenAI, “Video generation models as world simulators,” OpenAI, Tech. Rep., 2024.
- J. Devlin, M.-W. Chang, K. Lee, and K. Toutanova, “BERT: Pre-training of deep bidirectional transformers for language understanding,” arXiv preprint arXiv:1810.04805, 2018.
- A. Radford, K. Narasimhan, T. Salimans, I. Sutskever et al., “Improving language understanding by generative pre-training,” 2018.
- A. Radford, J. Wu, R. Child, D. Luan, D. Amodei, I. Sutskever et al., “Language models are unsupervised multitask learners,” OpenAI blog, vol. 1, no. 8, p. 9, 2019.
- T. Brown, B. Mann, N. Ryder, M. Subbiah, J. D. Kaplan, P. Dhariwal, A. Neelakantan, P. Shyam, G. Sastry, A. Askell et al., “Language models are few-shot learners,” Advances in Neural Information Processing Systems, vol. 33, pp. 1877–1901, 2020.
- J. Achiam, S. Adler, S. Agarwal, L. Ahmad, I. Akkaya, F. L. Aleman, D. Almeida, J. Altenschmidt, S. Altman, S. Anadkat et al., “GPT-4 technical report,” arXiv preprint arXiv:2303.08774, 2023.
- OpenAI, “ChatGPT: A language model for conversational AI,” OpenAI, Tech. Rep., 2023.
- Y. Li, C. Wang, and J. Jia, “LLaMA-VID: An image is worth 2 tokens in large language models,” arXiv preprint arXiv:2311.17043, 2023.
- P. Gao, J. Han, R. Zhang, Z. Lin, S. Geng, A. Zhou, W. Zhang, P. Lu, C. He, X. Yue et al., “LLaMA-Adapter V2: Parameter-efficient visual instruction model,” arXiv preprint arXiv:2304.15010, 2023.
- R. Rombach, A. Blattmann, D. Lorenz, P. Esser, and B. Ommer, “High-resolution image synthesis with latent diffusion models,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2022, pp. 10684–10695.
- A. Nichol, P. Dhariwal, A. Ramesh, P. Shyam, P. Mishkin, B. McGrew, I. Sutskever, and M. Chen, “GLIDE: Towards photorealistic image generation and editing with text-guided diffusion models,” arXiv preprint arXiv:2112.10741, 2021.
- A. Ramesh, P. Dhariwal, A. Nichol, C. Chu, and M. Chen, “Hierarchical text-conditional image generation with CLIP latents,” arXiv preprint arXiv:2204.06125, vol. 1, no. 2, p. 3, 2022.
- C. Saharia, W. Chan, S. Saxena, L. Li, J. Whang, E. L. Denton, K. Ghasemipour, R. Gontijo Lopes, B. Karagol Ayan, T. Salimans et al., “Photorealistic text-to-image diffusion models with deep language understanding,” Advances in Neural Information Processing Systems, vol. 35, pp. 36479–36494, 2022.
- Y. He, T. Yang, Y. Zhang, Y. Shan, and Q. Chen, “Latent video diffusion models for high-fidelity long video generation,” arXiv preprint arXiv:2211.13221, 2022.
- D. Zhou, W. Wang, H. Yan, W. Lv, Y. Zhu, and J. Feng, “MagicVideo: Efficient video generation with latent diffusion models,” arXiv preprint arXiv
- U. Singer, A. Polyak, T. Hayes, X. Yin, J. An, S. Zhang, Q. Hu, H. Yang, O. Ashual, O. Gafni et al., “Make-a-video: Text-to-video generation without text-video data,” arXiv preprint arXiv:2209.14792, 2022.
- J. Ho, W. Chan, C. Saharia, J. Whang, R. Gao, A. Gritsenko, D. P. Kingma, B. Poole, M. Norouzi, D. J. Fleet et al., “Imagen video: High definition video generation with diffusion models,” arXiv preprint arXiv:2210.02303, 2022.
- R. Villegas, M. Babaeizadeh, P.-J. Kindermans, H. Moraldo, H. Zhang, M. T. Saffar, S. Castro, J. Kunze, and D. Erhan, “Phenaki: Variable length video generation from open domain textual descriptions,” in International Conference on Learning Representations, 2022.
- H. Chen, M. Xia, Y. He, Y. Zhang, X. Cun, S. Yang, J. Xing, Y. Liu, Q. Chen, X. Wang et al., “VideoCrafter1: Open diffusion models for high-quality video generation,” arXiv preprint arXiv:2310.19512, 2023.
- Y. Guo, C. Yang, A. Rao, Y. Wang, Y. Qiao, D. Lin, and B. Dai, “AnimateDiff: Animate your personalized text-to-image diffusion models without specific tuning,” arXiv preprint arXiv:2307.04725, 2023.
- O. Bar-Tal, H. Chefer, O. Tov, C. Herrmann, R. Paiss, S. Zada, A. Ephrat, J. Hur, Y. Li, T. Michaeli et al., “Lumiere: A space-time diffusion model for video generation,” arXiv preprint arXiv:2401.12945, 2024.
- R. Girdhar, M. Singh, A. Brown, Q. Duval, S. Azadi, S. S. Rambhatla, A. Shah, X. Yin, D. Parikh, and I. Misra, “Emu Video: Factorizing text-to-video generation by explicit image conditioning,” arXiv preprint arXiv:2311.10709, 2023.
- A. Radford, J. W. Kim, C. Hallacy, A. Ramesh, G. Goh, S. Agarwal, G. Sastry, A. Askell, P. Mishkin, J. Clark et al., “Learning transferable visual models from natural language supervision,” in International Conference on Machine Learning. PMLR, 2021, pp. 8748–8763.
- A. Sanghi, H. Chu, J. G. Lambourne, Y. Wang, C.-Y. Cheng, M. Fumero, and K. R. Malekshan, “Clip-forge: Towards zero-shot text-to-shape generation,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2022, pp. 18603–18613.
- N. Mohammad Khalid, T. Xie, E. Belilovsky, and T. Popa, “Clip-Mesh: Generating textured meshes from text using pretrained image-text models,” in SIGGRAPH Asia 2022 Conference Papers, 2022, pp. 1–8.
- O. Michel, R. Bar-On, R. Liu, S. Benaim, and R. Hanocka, “Text2Mesh: Text-driven neural stylization for meshes,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2022, pp. 13492–13502.
- C. Wang, R. Jiang, M. Chai, M. He, D. Chen, and J. Liao, “NeRF-Art: Text-driven neural radiance fields stylization,” IEEE Transactions on Visualization and Computer Graphics, 2023.
- B. Kerbl, G. Kopanas, T. Leimkühler, and G. Drett28. B. Kerbl, G. Kopanas, T. Leimkühler, and G. Drettakis, “3D Gaussian Splatting for Real-Time Radiance Field Rendering,” ACM Transactions on Graphics, vol. 42, no. 4, July 2023. [Online]. Available: https://repo-sam.inria.fr/fungraph/3d-gaussian-splatting/
- T. Yi, J. Fang, J. Wang, G. Wu, L. Xie, X. Zhang, W. Liu, Q. Tian, and X. Wang, “GaussianDreamer: Fast Generation from Text to 3D Gaussians by Bridging 2D and 3D Diffusion Models,” arXiv preprint arXiv:2310.08529, 2023.
- J. Tang, J. Ren, H. Zhou, Z. Liu, and G. Zeng, “DreamGaussian: Generative Gaussian Splatting for Efficient 3D Content Creation,” arXiv preprint arXiv:2309.16653, 2023.
- L. Höllein, A. Cao, A. Owens, J. Johnson, and M. Nießner, “Text2Room: Extracting Textured 3D Meshes from 2D Text-to-Image Models,” in Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), October 2023, pp. 7909–7920.
- Y. Liang, X. Yang, J. Lin, H. Li, X. Xu, and Y. Chen, “LucidDreamer: Towards High-Fidelity Text-to-3D Generation via Interval Score Matching,” arXiv preprint arXiv:2311.11284, 2023.
- X. Yu, Y.-C. Guo, Y. Li, D. Liang, S.-H. Zhang, and X. Qi, “Text-to-3D with Classifier Score Distillation,” arXiv preprint arXiv:2310.19415, 2023.
- W. Li, R. Chen, X. Chen, and P. Tan, “SweetDreamer: Aligning Geometric Priors in 2D Diffusion for Consistent Text-to-3D,” arXiv preprint arXiv:2310.02596, 2023.
- Z. Wang, C. Lu, Y. Wang, F. Bao, C. Li, H. Su, and J. Zhu, “ProlificDreamer: High-Fidelity and Diverse Text-to-3D Generation with Variational Score Distillation,” arXiv preprint arXiv:2305.16213, 2023.
- J. Lorraine, K. Xie, X. Zeng, C.-H. Lin, T. Takikawa, N. Sharp, T.-Y. Lin, M.-Y. Liu, S. Fidler, and J. Lucas, “ATT3D: Amortized Text-to-3D Object Synthesis,” in International Conference on Computer Vision ICCV, 2023.
- J. Xu, X. Wang, W. Cheng, Y.-P. Cao, Y. Shan, X. Qie, and S. Gao, “Dream3D: Zero-Shot Text-to-3D Synthesis Using 3D Shape Prior and Text-to-Image Diffusion Models,” arXiv preprint arXiv:2212.14704, 2023.
- J. Zhu and P. Zhuang, “HiFA: High-Fidelity Text-to-3D with Advanced Diffusion Guidance,” arXiv preprint arXiv:2305.18766, 2023.
- R. Chen, Y. Chen, N. Jiao, and K. Jia, “Fantasia3D: Disentangling Geometry and Appearance for High-Quality Text-to-3D Content Creation,” in Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), October 2023.
- C. Tsalicoglou, F. Manhardt, A. Tonioni, M. Niemeyer, and F. Tombari, “TextMesh: Generation of Realistic 3D Meshes from Text Prompts,” arXiv preprint arXiv:2304.12439, 2023.
- B. Poole, A. Jain, J. T. Barron, and B. Mildenhall, “DreamFusion: Text-to-3D using 2D Diffusion,” arXiv preprint arXiv:2209.14988, 2022.
- C.-H. Lin, J. Gao, L. Tang, T. Takikawa, X. Zeng, X. Huang, K. Kreis, S. Fidler, M.-Y. Liu, and T.-Y. Lin, “Magic3D: High-Resolution Text-to-3D Content Creation,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2023, pp. 300–309.
- J. Seo, W. Jang, M.-S. Kwak, J. Ko, H. Kim, J. Kim, J.-H. Kim, J. Lee, and S. Kim, “Let 2D Diffusion Model Know 3D-Consistency for Robust Text-to-3D Generation,” arXiv preprint arXiv:2303.07937, 2023.
- H. Liu, Z. Chen, Y. Yuan, X. Mei, X. Liu, D. Mandic, W. Wang, and M. D. Plumbley, “AudioLDM: Text-to-Audio Generation with Latent Diffusion Models,” arXiv preprint arXiv:2301.12503, 2023.
- H. Liu, Q. Tian, Y. Yuan, X. Liu, X. Mei, Q. Kong, Y. Wang, W. Wang, Y. Wang, and M. D. Plumbley, “AudioLDM 2: Learning Holistic Audio Generation with Self-Supervised Pretraining,” arXiv preprint arXiv:2308.05734, 2023.
- F. Kreuk, G. Synnaeve, A. Polyak, U. Singer, A. Défossez, J. Copet, D. Parikh, Y. Taigman, and Y. Adi, “AudioGen: Textually Guided Audio Generation,” arXiv preprint arXiv:2209.15352, 2022.
- A. Agostinelli, T. I. Denk, Z. Borsos, J. Engel, M. Verzetti, A. Caillon, Q. Huang, A. Jansen, A. Roberts, M. Tagliasacchi et al., “MusicLM: Generating Music from Text,” arXiv preprint arXiv:2301.11325, 2023.
- J. Copet, F. Kreuk, I. Gat, T. Remez, D. Kant, G. Synnaeve, Y. Adi, and A. Défossez, “Simple and Controllable Music Generation,” Advances in Neural Information Processing Systems, vol. 36, 2024.
- S. Forsgren and H. Martiros, “Riffusion-stable diffusion for real-time music generation, 2022,” URL https://riffusion.com/about, vol. 6, 2022.
- X. Tan, J. Chen, H. Liu, J. Cong, C. Zhang, Y. Liu, X. Wang, Y. Leng, Y. Yi, L. He et al., “NaturalSpeech: End-to-End Text-to-Speech Synthesis with Human-Level Quality,” IEEE Transactions on Pattern Analysis and Machine Intelligence, 2024.
- K. Shen, Z. Ju, X. Tan, Y. Liu, Y. Leng, L. He, T. Qin, S. Zhao, and J. Bian, “NaturalSpeech 2: Latent Diffusion Models Are Natural and Zero-Shot Speech and Singing Synthesizers,” arXiv preprint arXiv:2304.09116, 2023.
- Z. Ju, Y. Wang, K. Shen, X. Tan, D. Xin, D. Yang, Y. Liu, Y. Leng, K. Song, S. Tang et al., “NaturalSpeech 3: Zero-Shot Speech Synthesis with Factorized Codec and Diffusion Models,” arXiv preprint arXiv:2403.03100, 2024.
- C. Wang, S. Chen, Y. Wu, Z. Zhang, L. Zhou, S. Liu, Z. Chen, Y. Liu, H. Wang, J. Li et al., “Neural Codec Language Models Are Zero-Shot Text to Speech Synthesizers,” arXiv preprint arXiv:2301.02111, 2023.
- Z. Jiang, J. Liu, Y. Ren, J. He, C. Zhang, Z. Ye, P. Wei, C. Wang, X. Yin, Z. Ma et al., “Mega-TTS 2: Zero-Shot Text-to-Speech with Arbitrary Length Speech Prompts,” arX55. Y. Ren, C. Hu, X. Tan, T. Qin, S. Zhao, Z. Zhao, and T.-Y. Liu, “FastSpeech 2: Fast and High-Quality End-to-End Text to Speech,” arXiv preprint arXiv:2006.04558, 2020.
- Y. Ge, Y. Ge, Z. Zeng, X. Wang, and Y. Shan, “Planting a Seed of Vision in Large Language Model,” arXiv preprint arXiv:2307.08041, 2023.
- L. Zeqiang, Z. Xizhou, D. Jifeng, Q. Yu, and W. Wenhai, “Mini-DALLE3: Interactive Text to Image by Prompting Large Language Models,” arXiv preprint arXiv:2310.07653, 2023.
- Z. Tang, Z. Yang, M. Khademi, Y. Liu, C. Zhu, and M. Bansal, “CoDi-2: In-Context, Interleaved, and Interactive Any-to-Any Generation,” arXiv preprint arXiv:2311.18775, 2023.
- Y. Ge, S. Zhao, Z. Zeng, Y. Ge, C. Li, X. Wang, and Y. Shan, “Making LLaMA See and Draw with SEED Tokenizer,” arXiv preprint arXiv:2310.01218, 2023.
- Q. Sun, Y. Cui, X. Zhang, F. Zhang, Q. Yu, Z. Luo, Y. Wang, Y. Rao, J. Liu, T. Huang et al., “Generative Multimodal Models Are In-Context Learners,” arXiv preprint arXiv:2312.13286, 2023.
- X. Zhao, B. Liu, Q. Liu, G. Shi, and X.-M. Wu, “Making Multimodal Generation Easier: When Diffusion Models Meet LLMs,” arXiv preprint arXiv:2310.08949, 2023.
- J. Chen, Y. Huang, T. Lv, L. Cui, Q. Chen, and F. Wei, “TextDiffuser-2: Unleashing the Power of Language Models for Text Rendering,” arXiv preprint arXiv:2311.16465, 2023.
- L. Lian, B. Li, A. Yala, and T. Darrell, “LLM-Grounded Diffusion: Enhancing Prompt Understanding of Text-to-Image Diffusion Models with Large Language Models,” arXiv preprint arXiv:2305.13655, 2023.
- W. Feng, W. Zhu, T.-j. Fu, V. Jampani, A. Akula, X. He, S. Basu, X. E. Wang, and W. Y. Wang, “LayoutGPT: Compositional Visual Planning and Generation with Large Language Models,” arXiv preprint arXiv:2305.15393, 2023.
- T. Zhang, Y. Zhang, V. Vineet, N. Joshi, and X. Wang, “Controllable Text-to-Image Generation with GPT-4,” arXiv preprint arXiv:2305.18583, 2023.
- L. Qu, S. Wu, H. Fei, L. Nie, and T.-S. Chua, “LayoutLLM-T2I: Eliciting Layout Guidance from LLM for Text-to-Image Generation,” in Proceedings of the 31st ACM International Conference on Multimedia, 2023, pp. 643–654.
- Y. Li, H. Liu, Q. Wu, F. Mu, J. Yang, J. Gao, C. Li, and Y. J. Lee, “GLIGEN: Open-Set Grounded Text-to-Image Generation,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2023, pp. 22511–22521.
- J. Betker, G. Goh, L. Jing, T. Brooks, J. Wang, L. Li, L. Ouyang, J. Zhuang, J. Lee, Y. Guo et al., “Improving Image Generation with Better Captions,” Computer Science. https://cdn.openai.com/papers/dall-e-3.pdf, 2023.
-
LLMs Meet Multimodal Generation and Editing: A Survey
在当今这个信息爆炸的时代,人工智能(AI)正以前所未有的速度发展,其中大型语言模型(LLMs)尤为引人注目。这些模型不仅在文本理解方面取得了巨大进步,而且在多模态学习——即结合图像、视频、3D模型和音频等多种信息形式的学习——方面也展现出了巨大潜力。最近,我有幸阅读了一篇关于这一主题的综述文章,现在,我将尝试以通俗易懂的语言,向您介绍这篇综述的精髓。
LLMs与多模态生成:一次革命性的邂逅
首先,让我们来谈谈什么是大型语言模型(LLMs)。想象一下,如果你有一个能够理解和生成人类语言的超级助手,那么这个助手就是基于LLMs的。这些模型通过分析大量的文本数据来学习语言的规律,从而能够完成诸如回答问题、撰写文章甚至生成代码等任务。
然而,LLMs的野心不止于此。研究人员发现,当LLMs与多模态学习结合时,它们能够做的事情远远超出了我们的想象。多模态学习意味着模型不仅要处理文本,还要处理图像、视频、3D模型和音频等其他类型的数据。这种结合为AI开辟了新的可能性,使得机器能够更全面地理解和响应我们的世界。
多模态生成的里程碑
在这篇综述中,作者们详细探讨了LLMs在多模态生成领域的应用,包括以下几个方面:
- 图像生成:通过文本提示生成图像,比如你告诉模型“生成一张日落的图片”,它就能创造出一幅美丽的日落景象。
- 视频生成:类似地,模型可以根据文本描述生成视频内容,这对于电影制作和游戏开发等领域具有重要意义。
- 3D生成:LLMs可以帮助生成3D模型,这对于虚拟现实(VR)和增强现实(AR)应用来说是一个巨大的突破。
- 音频生成:模型还能够根据文本描述生成音频,无论是音乐、自然声音还是人声,都能够被创造出来。
LLMs如何工作?
那么,这些模型是如何工作的呢?简单来说,它们通过以下步骤:
- 理解:首先,LLMs需要理解输入的文本描述。
- 规划:然后,它们会规划如何将这些描述转换成相应的图像、视频、3D模型或音频。
- 生成:最后,模型会利用其学习到的知识生成最终的内容。
安全性和未来展望
随着LLMs的能力越来越强,安全性也成为一个重要议题。我们需要确保这些模型不会被用于制造虚假信息或有害内容。此外,随着技术的发展,我们期待看到更多创新的应用,比如在教育、娱乐和设计等领域。
结语
LLMs与多模态生成的结合,不仅仅是AI领域的一次技术飞跃,更是为我们打开了一扇通往全新世界的大门。随着研究的深入,我们有理由相信,未来的AI将更加智能、更加安全,也更加贴近我们的生活。让我们拭目以待,AI将如何继续改变我们的世界。
-
LLMs与多模态生成及编辑:一项综述
引言
随着大型语言模型(LLMs)的快速发展,越来越多的研究开始关注将LLMs与多模态学习相结合。多模态学习旨在融合各种信息源,如图像、视频、3D模型和音频,以实现更丰富、更加自然的人机交互。然而,以往的研究主要集中在多模态理解上,本综述将重点放在多模态生成领域,包括图像、视频、3D和音频等。
主要内容概述
多模态生成的背景
人类与物理世界的交互涉及多种模态信息,如语言、视觉和音频。为了实现世界模拟器,模型需要灵活地感知和响应多模态信息。通过结合LLMs和多模态生成技术,我们可以实现更智能、更灵活的生成系统。
关键技术组件
在多模态生成领域,以下是几项关键的技术组件:
- 多模态数据集:不同模态的数据集是支撑多模态生成研究的基础。
- 生成模型:包括扩散模型、变换器和其他生成技术,它们在多模态生成中发挥了重要作用。
- 工具辅助多模态代理:这些代理能够利用现有的生成模型进行人机交互,提升生成效果。
多模态生成技术的进展
图像生成
在图像生成方面,LLMs的应用已经取得了显著的进展。例如:
- DALL-E:通过文本描述生成高质量的图像。[150]
- Latent Diffusion Models (LDM):通过潜在空间中的扩散过程生成图像。[10]
视频生成
视频生成方面的研究同样取得了重要进展,包括:
- VideoCrafter:一种高质量的视频生成模型。[19]
- Make-A-Video:通过文本描述生成视频。[16]
3D生成
在3D生成领域,LLMs被用于生成和编辑3D模型。例如:
- CLIP:一种基于文本描述生成3D模型的技术。[23]
- ShapeGPT:结合LLMs生成复杂的3D形状。[306]
音频生成
音频生成方面,LLMs主要用于生成和编辑音乐、语音等音频内容。例如:
- AudioLM:通过语言模型生成音频。[110]
- WavJourney:基于语义描述生成音频信号。[105]
AI安全性
在多模态生成领域,AI安全性是一个重要的问题。为了减少有害和偏见内容的生成,研究者们提出了多种方法:
- Latent Guard:一种保护模型免受攻击的方法。[449]
- SafetyBench:用于评估多模态模型安全性的数据集。[468]
未来发展方向
为了推动多模态生成技术的发展,未来的研究可以探索以下几个方向:
- 高分辨率生成:提高生成内容的分辨率,以满足虚拟现实和电影制作等领域的需求。
- 长期序列生成:生成更长的视频和音频序列,创造沉浸式体验。
- 多视角一致性:确保3D对象从不同视角观察时的一致性。
- 统一训练的多模态生成:实现单一模型生成多种模态内容的能力。
结语
本综述系统性地回顾了LLMs在多模态生成中的应用,涵盖了图像、视频、3D和音频等多个领域。通过详细分析这些技术的进展和应用,我们希望为未来的研究提供指导,并推动人工智能在生成内容方面的发展。
参考文献
[1] Yingqing He, Zhaoyang Liu, Jingye Chen, Zeyue Tian, Hongyu Liu, Xiaowei Chi, Runtao Liu, Ruibin Yuan, Yazhou Xing, Wenhai Wang, Jifeng Dai, Yong Zhang, Wei Xue, Qifeng Liu, Yike Guo, Qifeng Chen, “LLMs Meet Multimodal Generation and Editing: A Survey.” Available at: https://github.com/YingqingHe/Awesome-LLMs-meet-Multimodal-Generation
-
生成代码世界模型:结合大型语言模型和蒙特卡罗树搜索
引言
在人工智能领域,能够对世界进行建模是智能体实现目标的关键能力。当面对新的环境时,智能体必须迅速理解其机制,以便制定计划并实现目标。在这种情况下,自然语言条件可以帮助智能体将当前观察与过去的知识联系起来,从而更好地理解世界。因此,通过自然语言向智能体传递关于新任务的信息,具有特别的前景。
近年来,大型语言模型(LLMs)在自然语言处理领域取得了革命性的进展,并为世界建模提供了巨大的机会。然而,将LLMs与世界模型结合的最佳方式尚不明确。在这篇文章中,我们介绍了一种新的方法,即通过编写Python代码来生成RL(强化学习)世界模型。
代码世界模型(Code World Models)
什么是代码世界模型?
代码世界模型(CWM)是由LLMs生成的一种世界模型,这些模型以Python代码的形式存在,专门用于基于模型的强化学习(RL)。与直接使用LLMs进行规划相比,调用代码具有精准、可靠、可解释和高效的优点。然而,编写合适的代码世界模型需要理解复杂的指令、生成具有非平凡逻辑的精确代码,以及通过单元测试和环境轨迹反馈自我调试长程序。
为了解决这些挑战,我们提出了GIF-MCTS(Generate, Improve and Fix with Monte Carlo Tree Search),这是一种新的代码生成策略,用于优化LLMs的代码生成能力。
代码世界模型的框架
在模型基础的强化学习问题设置中,我们将环境表示为具有状态空间、动作空间、转移函数和标量奖励函数的马尔可夫决策过程。世界模型的任务是准确表示转移函数和奖励函数。
我们假设:
- 环境是确定的且完全可观察的。
- 提供的环境自然语言描述足够详细,可以推断出观察空间以及转移和奖励函数的逻辑。
代码世界模型基准(CWMB)
为了全面测试不同环境下的世界模型生成,我们定义了一个新的基准,包括18个难度不同的RL环境。每个环境都有相应的自然语言描述和精心设计的轨迹数据集。这个基准旨在通过提供的数据学习准确合成代码世界模型,并在不同复杂度的环境中评估不同的代码生成方法。
GIF-MCTS:生成、改进和修复
我们提出的GIF-MCTS方法使用蒙特卡罗树搜索(MCTS)来生成和优化代码世界模型。GIF-MCTS的主要流程包括选择、扩展、评估和价值回溯。
动作类型
GIF-MCTS方法包括三种主要动作类型:
- 生成新行:利用LLM的随机采样能力,在树的不同分支中生成不同的代码片段。
- 改进预测:LLM会被提示改进现有代码,并提供错误预测的输入示例及其预期输出。
- 修复错误:当代码包含语法或运行时错误时,LLM会尝试修复这些错误,并提供修复逻辑。
实验
基准
我们在三个基准上评估了GIF-MCTS的性能:新的CWMB、流行且具有挑战性的编码基准APPS,以及语言条件网格世界RTFM。GIF-MCTS在所有三个基准上都超过了现有方法,包括APPS的“Competition”部分,CWMB的更难连续环境以及RTFM。
实验结果
使用GIF-MCTS生成的代码世界模型能够成功用于规划,生成的基于模型的RL智能体在样本效率和推理速度上显著提高。我们展示了在多个环境中使用合成的CWM进行成功的规划,结果表明CWM在推理速度上比直接查询LLM快四到六个数量级,同时在CWM准确时,其性能可以与访问真实世界模型的oracle规划器相匹敌。
讨论
限制
尽管代码世界模型(CWM)框架是一个令人兴奋的基于模型规划的方向,但我们仍依赖于环境的确定性和完全可观察性的假设。未来的工作可以探索如何将该方法扩展到包含随机性和部分可观察环境中。
此外,提供能够合理转换为Python函数的环境描述(例如记录关键变量的手册)也是一个潜在问题。在没有可用描述的情况下,预处理技术(例如图像到文本模型)可能是解决这一问题的一种方法。
结论
我们提出了一种新的框架,即代码世界模型(CWM),通过结合大型语言模型(LLM)和蒙特卡罗树搜索(MCTS),为基于模型的强化学习(RL)智能体构建世界模型。我们的实验表明,GIF-MCTS方法在多个基准上都表现优异,能够生成高效且可解释的代码世界模型,并显著提高基于模型的RL智能体的样本效率和推理速度。
未来的研究可以继续完善代码生成方法,优化底层LLM模型,并探索如何将CWM应用于更复杂的环境中。我们相信,CWM框架将推动开发出更快、更可解释且样本效率更高的基于模型的RL智能体。
致谢
本文的研究得到了芬兰研究理事会(旗舰计划:芬兰人工智能中心FCAI,资助编号352986、358246)和欧盟(H2020资助101016775和NextGenerationEU)的支持。我们感谢CSC为本项目提供的LUMI超级计算机的访问权限,该计算机由EuroHPC联合企业所有,由CSC(芬兰)和LUMI联盟主办。
参考文献
- Ha, D., & Schmidhuber, J. (2018). World models.
- Hendrycks, D., Basart, S., Kadavath, S., et al. (2021). Measuring coding challenge competence with apps.
- Kocsis, L., & Szepesvári, C. (2006). Bandit based monte-carlo planning.
- Lin, J., Du, Y., Watkins, O., et al. (2023). Learning to model the world with language.
- Tang, H., Key, D., & Ellis, K. (2024). Worldcoder, a model-based llm agent: Building world models by writing code and interacting with the environment.
- Zhong, V., Rocktäschel, T., & Grefenstette, E. (2020). RTFM: Generalising to new environment dynamics via reading.
这篇文章不仅介绍了代码世界模型和GIF-MCTS方法的理论基础,还通过实验验证了其在多个基准上的优越性能。希望未来的研究能够进一步提升这一领域的发展,为人工智能和强化学习带来更多突破。
-
为apache2 开启https
要在Apache2上启用HTTPS,您需要完成以下步骤:
- 安装所需的软件包:
- 在Ubuntu上,使用以下命令安装Apache2:
sudo apt install apache2 - 在CentOS上,使用以下命令安装Apache2:
sudo yum install httpd
- 生成SSL证书和密钥:
- 您可以使用自签名证书进行测试,或者从证书颁发机构获取有效的SSL证书。
- 使用以下命令生成自签名证书和密钥:
sudo openssl req -x509 -nodes -days 365 -newkey rsa:2048 -keyout /etc/ssl/private/apache-selfsigned.key -out /etc/ssl/certs/apache-selfsigned.crt
- 配置Apache2以使用SSL:
- 在Ubuntu上,使用以下命令启用SSL模块:
sudo a2enmod ssl - 在CentOS上,SSL模块已经默认启用。
- 创建SSL虚拟主机配置文件:
- 在Ubuntu上,使用以下命令创建新的配置文件:
sudo nano /etc/apache2/sites-available/default-ssl.conf - 在CentOS上,使用以下命令创建新的配置文件:
sudo nano /etc/httpd/conf.d/ssl.conf - 将以下内容添加到配置文件中:
<VirtualHost _default_:443> ServerAdmin your_email@example.com DocumentRoot /var/www/html ServerName your_domain.com SSLEngine on SSLCertificateFile /etc/ssl/certs/apache-selfsigned.crt SSLCertificateKeyFile /etc/ssl/private/apache-selfsigned.key <FilesMatch "\.(cgi|shtml|phtml|php) {APACHE_LOG_DIR}/error.log CustomLog ${APACHE_LOG_DIR}/access.log combined </VirtualHost>
{APACHE_LOG_DIR}/error.log CustomLog ${APACHE_LOG_DIR}/access.log combined </VirtualHost>
- 启用SSL虚拟主机配置:
- 在Ubuntu上,使用以下命令启用配置文件:
sudo a2ensite default-ssl.conf - 在CentOS上,无需启用配置文件。
- 重新加载Apache2配置:
- 在Ubuntu上,使用以下命令重新加载配置:
sudo systemctl reload apache2 - 在CentOS上,使用以下命令重新加载配置:
sudo systemctl reload httpd
- 防火墙设置:
- 在Ubuntu上,使用以下命令允许HTTPS流量:
sudo ufw allow 'Apache Full' - 在CentOS上,使用以下命令允许HTTPS流量:
sudo firewall-cmd --permanent --add-service=https - 重新加载防火墙规则:
- 在Ubuntu上,使用以下命令重新加载防火墙:
sudo ufw reload - 在CentOS上,使用以下命令重新加载防火墙:
sudo firewall-cmd --reload
- 在Ubuntu上,使用以下命令重新加载防火墙:
现在,您的Apache2服务器已经配置为使用HTTPS。您可以通过访问
https://your_domain.com来测试它。
Learn more:
-
Ubuntu上如何配置一个ftp server方便wordpress升级
在 Ubuntu 上配置一个 FTP 服务器以便于 WordPress 升级,通常使用的是 vsftpd (Very Secure FTP Daemon)。以下是详细步骤:
安装 vsftpd
- 更新包列表并安装 vsftpd:
sudo apt update sudo apt install vsftpd配置 vsftpd
- 备份默认配置文件并编辑:
sudo cp /etc/vsftpd.conf /etc/vsftpd.conf.bak sudo nano /etc/vsftpd.conf- 修改配置文件: 确保以下配置选项被设置,添加或修改这些行:
listen=YES anonymous_enable=NO local_enable=YES write_enable=YES local_umask=022 dirmessage_enable=YES use_localtime=YES xferlog_enable=YES connect_from_port_20=YES chroot_local_user=YES allow_writeable_chroot=YES如果你希望使用被动模式 FTP,还需要添加以下配置:
pasv_enable=YES pasv_min_port=10000 pasv_max_port=10100添加 FTP 用户
- 创建用于 FTP 的用户: 用户目录应与 WordPress 安装目录一致。假设 WordPress 安装在
/var/www/html/wordpress:
sudo adduser ftpuser sudo usermod -d /var/www/html/wordpress ftpuser- 设置目录权限: 确保
ftpuser对 WordPress 目录具有适当的权限:
sudo chown -R ftpuser:ftpuser /var/www/html/wordpress sudo chmod -R 755 /var/www/html/wordpress启动 vsftpd
- 启动 vsftpd 并设置开机启动:
sudo systemctl start vsftpd sudo systemctl enable vsftpd配置防火墙
- 允许 FTP 流量: 如果你使用 UFW 防火墙,需要开放 FTP 端口:
sudo ufw allow 20/tcp sudo ufw allow 21/tcp sudo ufw allow 10000:10100/tcp sudo ufw reload配置 WordPress 使用 FTP 进行升级
- 配置 WordPress 使用 FTP: 你需要在
wp-config.php文件中添加 FTP 连接信息:
define('FS_METHOD', 'ftpext'); define('FTP_BASE', '/var/www/html/wordpress/'); define('FTP_USER', 'ftpuser'); define('FTP_PASS', 'your_ftp_password'); define('FTP_HOST', '127.0.0.1'); define('FTP_SSL', false);根据你的实际情况修改这些配置。
测试 FTP 连接
- 测试 FTP 连接: 使用 FTP 客户端(如 FileZilla)连接到你的 FTP 服务器,确保能够成功登录并访问 WordPress 目录。
完成
通过以上步骤,你应该已经在 Ubuntu 上成功配置了一个 FTP 服务器,并且 WordPress 可以使用该 FTP 服务器进行升级。如果有遇到任何问题,可以检查 vsftpd 日志文件
/var/log/vsftpd.log以获取更多信息。