“我的手机相册里到底有多少照片?”
“上个月我跑了多少次步?”
“上次去纽约旅行时,我到底吃了多少顿美食?”
是不是感觉似曾相识?我们每天都在用手机记录生活,照片、视频、截图,不知不觉间就积累了庞大的个人记忆库。然而,面对这些海量数据,想要快速找到想要的记忆碎片,却如同大海捞针般困难。
传统的相册搜索功能,只能基于简单的关键词或时间进行检索,对于那些需要上下文理解的复杂问题束手无策。想象一下,你想要寻找“上次和朋友聚餐时拍的那张照片”,却只能输入“朋友”或“餐厅”作为关键词,结果可想而知,必然是无数张毫不相关的照片扑面而来,让你淹没在信息的海洋中。 😩
为了解决这一难题,我们开发了 OmniQuery 系统,一个能够理解上下文、更智能的个人记忆问答系统。它就像是一位经验丰富的“记忆宫殿”管理员,能够帮你整理、归纳、理解你的记忆碎片,并根据你的自然语言提问,精准地找到你想要的答案。
俗话说, “磨刀不误砍柴工”。在设计 OmniQuery 之前,我们首先进行了一项为期一个月的日记研究,邀请了 29 位参与者记录下他们在日常生活中真实遇到的、想要查询个人记忆的问题。
分析收集到的 299 条真实用户查询后,我们发现,超过 74% 的问题都需要结合上下文信息才能得到解答,例如:
这些问题无法简单地通过关键词匹配来解决,而是需要对用户的记忆进行更深层次的理解和推理。为此,我们建立了一个上下文信息分类法,将用户查询中涉及的上下文信息分为三类:
下图展示了不同类型上下文信息在用户查询中的出现频率:
pie showData
title 上下文信息类型
"原子上下文" : 75
"组合上下文" : 191
"混合查询" : 33基于上述分类法,我们设计了 OmniQuery 系统,其核心在于一个与查询无关的预处理流程,用于从相互关联的记忆实例中提取、整合上下文信息,并用这些信息来增强每个记忆实例,使其更易于检索和理解。
具体来说,该预处理流程包括三个步骤:
经过以上三个步骤的处理后,用户的记忆实例就被赋予了丰富的上下文信息,从而能够支持更复杂、更智能的查询。
OmniQuery 的问答系统采用了检索增强生成(RAG)架构,该架构结合了传统信息检索方法和大型语言模型的优势,能够在处理海量数据的同时,生成更准确、更流畅的答案。
具体来说,当用户输入一个问题时,OmniQuery 会首先对问题进行增强,将其分解成多个更具体的子问题,并根据上下文信息进行补充和完善。
例如,对于问题“我在 CHI 2024 期间参加了哪些社交活动?”,OmniQuery 会将其分解成以下几个子问题:
接下来,OmniQuery 会根据增强后的问题,从结构化的记忆实例、组合上下文信息和语义知识库中检索相关信息,并将检索到的信息输入大型语言模型,生成最终的答案。
为了提高答案的生成质量,OmniQuery 还采用了思维链提示(Chain-of-Thought Prompting)技术,引导大型语言模型进行更深入的推理,生成更准确、更全面的答案。
为了评估 OmniQuery 的性能,我们招募了 10 位参与者,让他们在自己的个人记忆数据上测试 OmniQuery 和一个传统的基于关键词匹配的检索系统。
结果表明,OmniQuery 在准确率和完整度方面均优于传统的检索系统。
| 指标 | OmniQuery | 传统检索系统 |
|---|---|---|
| 准确率 | 71.5% | 43.1% |
| 获胜或打平率 | 74.5% | 25.5% |
参与者们对 OmniQuery 的评价也普遍高于传统的检索系统。他们认为 OmniQuery 能够更好地理解他们的问题,并给出更准确、更完整的答案。
OmniQuery 的出现,为我们提供了一种全新的方式来管理和利用个人记忆数据。在未来,OmniQuery 将继续朝着更加智能、更加人性化的方向发展,例如:
我们相信,随着人工智能技术的不断发展,OmniQuery 将会变得越来越强大,最终成为我们每个人不可或缺的“记忆助手”。
在科技的浩瀚宇宙中,软件开发领域如同一片繁星闪烁的天空,其中引擎(Engine)和框架(Framework)是两颗闪亮的星星。尽管它们在功能上有重叠,很多人仍然容易将它们混淆。然而,深入探讨后,我们会发现它们各自独特的特质和应用场景。本文将带你深入了解这两位技术英雄的异同之处。
引擎,顾名思义,是一个驱动系统的核心部分。它可以被视为一个强大的“发动机”,负责执行特定的任务。例如,在游戏开发中,游戏引擎如同一台强大的汽车引擎,负责处理图形渲染、物理计算、声音效果等多项复杂的功能。知名的游戏引擎如Unreal Engine和Unity便是这样的平台。
引擎不仅仅是个工具,它还可以被看作是一个完整的生态系统。它整合了多种组件,帮助开发者快速构建和优化各类应用。就像一位全能的厨师,游戏引擎能够调动多种“食材”,只需简单的配方,便能烹饪出丰富的“菜肴”。
以Unity为例,这款引擎支持2D和3D游戏开发,拥有强大的图形渲染能力和物理引擎,甚至还提供了多平台支持,让开发者能够将游戏发布到PC、移动设备和主机上。Unity的可视化编辑器使得开发者能够像拼图一样组合各个组件,迅速构建出一个完整的游戏场景。
与引擎不同,框架更像是一个架构师为建筑设计的蓝图。它提供了一种结构化的方式,帮助开发者在特定的领域内迅速搭建应用。框架往往包含了一些约定和最佳实践,旨在提高开发效率和代码的可维护性。
以Web开发为例,像Django和Ruby on Rails这样的框架,提供了一整套工具和库,帮助开发者快速构建动态网站。它们定义了项目的结构、数据模型以及与数据库的交互方式,极大地减少了重复劳动,让开发者能够将精力集中在业务逻辑上。
框架的优势在于其清晰的规范和一致性。就像一位优秀的建筑师,不仅为工人们提供了详细的施工图纸,还为他们设计了施工流程和标准,确保每一位工人都能高效协作,最终实现一个宏伟的建筑。这种结构化的开发方式不仅提高了代码的可读性,还降低了维护成本。
引擎和框架的核心区别在于它们的定位和功能。引擎更专注于底层的实现和性能优化,而框架则注重于开发流程的规范和高效性。可以说,引擎是基础设施,而框架则是建筑设计。
在一个典型的开发过程中,开发者可能会先选择一个引擎来处理底层的技术细节,然后再用框架来搭建应用的结构。例如,在游戏开发中,开发者可能会选择Unity作为引擎,同时使用一些特定的框架来处理游戏逻辑和用户界面。
| 功能 | 引擎 | 框架 |
|---|---|---|
| 目标 | 底层实现与性能优化 | 结构化开发与最佳实践 |
| 例子 | Unity、Unreal Engine | Django、Ruby on Rails |
| 适用领域 | 游戏开发、图形渲染 | Web开发、应用开发 |
| 开发方式 | 灵活、自由 | 规范、结构化 |
在软件开发的过程中,选择合适的工具至关重要。开发者需要根据项目的需求、团队的技术栈以及未来的维护成本来决定使用引擎还是框架。在某些情况下,二者也可以结合使用,以便在享受引擎带来的高性能的同时,也能借助框架的规范化来提高开发效率。
想象一下,一个大型的游戏项目,开发团队首先选择Unity作为引擎来处理图形和物理效果,然后使用一个轻量级的框架来管理游戏中的角色状态、场景切换和用户输入。这种组合方式不仅能够充分发挥Unity的强大性能,同时也能确保代码的可维护性和可扩展性。
在这个过程中,开发者需要牢记一个核心原则:工具是服务于人的,而不是相反。无论是引擎还是框架,最终的目的是帮助开发者实现他们的创意和目标。选择适合的工具,才能在技术的海洋中乘风破浪。
引擎与框架作为软件开发中的两大核心概念,各自拥有独特的魅力与价值。理解它们的区别与联系,不仅能帮助开发者在项目中做出更明智的选择,也能提升整体的开发效率。无论是追求高性能的引擎,还是注重结构化的框架,最终的目标都是为用户提供优秀的产品体验。让我们在引擎与框架的世界中,共同探索更多的可能性吧!
在现代Web应用开发中,条件渲染是实现动态用户体验的核心技术之一。Reflex框架中的Cond组件为我们提供了一种简单而强大的方式来根据条件动态渲染不同的组件。本文将深入探讨Cond组件的用法,以及如何利用它构建灵活的用户界面。
Cond组件是Reflex中用于条件渲染的基础组件。它接受一个条件和两个组件作为参数。当条件为真时,渲染第一个组件;否则,渲染第二个组件。通过这种方式,开发者可以轻松实现动态内容的展示。
以下是一个使用Cond组件的示例:
class CondState(rx.State):
show: bool = True
def change(self):
self.show = not self.show
def cond_example():
return rx.vstack(
rx.button("Toggle", on_click=CondState.change),
rx.cond(
CondState.show,
rx.text("Text 1", color="blue"),
rx.text("Text 2", color="red"),
),
)在这个示例中,当用户点击“Toggle”按钮时,CondState.show的值会被切换,从而决定渲染“Text 1”还是“Text 2”。这种简单而直观的逻辑使得动态用户界面的构建变得轻松无比。
除了基本的条件判断外,Cond组件还支持条件的否定。我们可以使用逻辑运算符 ~ 来实现这一点。例如:
rx.vstack(
rx.button("Toggle", on_click=CondState.change),
rx.cond(
CondState.show,
rx.text("Text 1", color="blue"),
rx.text("Text 2", color="red"),
),
rx.cond(
~CondState.show,
rx.text("Text 1", color="blue"),
rx.text("Text 2", color="red"),
),
)在这个例子中,当条件为假时,第二个Cond组件会被启用,提供了更多的灵活性和控制能力。这种处理方式使得开发者能够更精细地控制组件的渲染逻辑。
当需要根据多个条件来决定渲染内容时,Cond组件同样表现出色。我们可以使用逻辑运算符 &(与)和 |(或)来组合多个条件,从而实现复杂的渲染逻辑。
以下是一个多条件的示例:
class MultiCondState(rx.State):
cond1: bool = True
cond2: bool = False
cond3: bool = True
def change(self):
self.cond1 = not self.cond1
def multi_cond_example():
return rx.vstack(
rx.button("Toggle", on_click=MultiCondState.change),
rx.text(
rx.cond(MultiCondState.cond1, "True", "False"),
" & True => ",
rx.cond(
MultiCondState.cond1 & MultiCondState.cond3,
"True",
"False",
),
),
rx.text(
rx.cond(MultiCondState.cond1, "True", "False"),
" & False => ",
rx.cond(
MultiCondState.cond1 & MultiCondState.cond2,
"True",
"False",
),
),
rx.text(
rx.cond(MultiCondState.cond1, "True", "False"),
" | False => ",
rx.cond(
MultiCondState.cond1 | MultiCondState.cond2,
"True",
"False",
),
),
)在这个示例中,我们通过组合多个条件,提供了不同的渲染结果。开发者可以根据不同的条件状态来展示不同的文本,极大地丰富了用户界面的表现力。
Cond组件的使用非常灵活,以下是其主要属性的简要说明:
通过这些属性,开发者可以轻松构建出满足复杂需求的动态界面。
在Reflex框架中,Cond组件为我们提供了强大的条件渲染能力,使得动态内容的展现变得简单而高效。无论是基本的条件判断、否定条件的处理,还是多条件的组合使用,Cond组件都能轻松应对。掌握这些技巧,将为你构建更具吸引力和交互性的Web应用打下坚实的基础。
希望本文能帮助你更好地理解和使用Reflex中的Cond组件,提升你的开发体验与效率!
在现代Web开发中,数据库的管理和操作是构建高效应用的基石。Reflex框架以其优雅的设计,提供了一个强大的数据库接口,让开发者能够轻松地连接、管理和操作数据。本文将深入探讨Reflex的数据库特性,包括连接、表、迁移和查询等核心功能。
Reflex框架内置了SQLite数据库,开发者可以方便地存储和检索数据。如果你希望连接到其他SQL兼容的数据库,只需修改 rxconfig.py 文件,配置你的数据库URL。例如,以下是如何连接到一个SQLite数据库的代码示例:
config = rx.Config(
app_name="my_app",
db_url="sqlite:///reflex.db",
)在使用不同的数据库时,确保安装适当的DBAPI驱动程序,以便Reflex能够与目标数据库顺畅交互。此外,开发者也可以使用NoSQL数据库(如MongoDB),只需安装相应的Python客户端库。需要注意的是,在这种情况下,Reflex将不提供ORM特性。
在Reflex中,创建一个数据表的过程非常简单。只需定义一个继承自 rx.Model 的类,并指定它作为一个表。例如,以下代码定义了一个用户表:
class User(rx.Model, table=True):
username: str
email: str
password: str通过这种方式,开发者可以快速构建出符合需求的数据模型,进一步提高开发效率。
在应用开发过程中,数据库模式的变更是不可避免的。Reflex利用Alembic工具来管理这些变更。在新应用中使用数据库功能之前,必须调用 reflex db init 命令来初始化Alembic,并创建一个迁移脚本以反映当前模式。
当需要对数据库模式进行更改时,开发者可以使用以下命令生成迁移脚本:
reflex db makemigrations --message 'something changed'生成的脚本将存放在 alembic/versions 目录下,建议在应用这些脚本之前先进行检查。应用迁移脚本的命令为 reflex db migrate,这样就能将数据库更新到最新状态。每当应用启动时,Reflex会检测当前数据库模式是否最新,并在控制台中显示警告信息。
查询数据库是Reflex框架中一个重要的功能。开发者可以创建一个 rx.session() 来处理数据库连接的开启和关闭。使用普通的SQLAlchemy查询语法,就能够方便地进行数据操作。例如,以下代码展示了如何向用户表中添加一条新记录:
with rx.session() as session:
session.add(
User(
username="test",
email="admin@reflex.dev",
password="admin",
)
)
session.commit()这种简洁的查询方式让开发者能够高效地操作数据库,极大地提升了开发体验。
通过以上的探讨,我们可以看到Reflex框架为开发者提供了一整套完备的数据库管理解决方案。从简单的连接到复杂的查询,Reflex都能轻松应对。无论是初学者还是经验丰富的开发者,都能在这个框架中找到适合自己需求的工具。
在快速发展的技术环境中,掌握Reflex的数据库功能,将为构建高效、灵活的Web应用打下坚实的基础。未来,随着Reflex的不断进化,我们可以期待更多强大而便捷的数据库特性加入进来,助力开发者在数字世界中畅行无阻。
在当前的人工智能领域中,HyperWrite 公司刚刚推出的 Reflection 70B 模型引发了广泛的关注和争议。这个被宣称为“世界上最强大的开源 LLM”(大型语言模型)的新模型,究竟是技术的突破,还是一场精心策划的骗局?让我们深入探索这一话题。
Reflection 70B 的推出,由 HyperWrite 的联合创始人兼首席执行官 Matt Shumer 宣布。这个模型基于 Meta 的 Llama 3.1-70B Instruct 模型,并引入了一种名为“Reflection-Tuning”的新技术,旨在解决 LLM 的“幻觉”问题,即错误生成信息的现象。Shumer 在社交媒体上的帖子中声称,Reflection 70B 在多个基准测试中表现优异,甚至超越了许多商业模型,如 GPT-4o。
在其发布的图表中,Reflection 70B 在 MMLU 和 HumanEval 等基准测试中表现出色,显示出其在与 Meta Llama 系列模型的竞争中占据了明显优势。这一切似乎预示着开源 AI 模型的新时代即将来临。
然而,随着用户的测试结果逐渐浮出水面,关于 Reflection 70B 的争议也随之而来。一些早期用户发现,模型的实际表现并未达到 Shumer 所描述的高度。用户在测试中表示,Reflection 70B 实际上在许多情况下表现不如 Llama 3.1,甚至被指责为仅仅是对现有模型的简单封装。
特别是在 GSM8K 测试中,用户们对其超过 99% 的得分表示质疑,认为这种表现可能是由于数据集中的错误标签导致的。这引发了对于模型准确性和可靠性的严重关切。
尽管存在不少质疑,Shumer 坚称 Reflection 70B 具备独特的自我反思和错误修正能力。该模型在生成响应时,会对自己的答案进行反思,并仅在确认正确后才输出结果。这种方法的核心是 Reflection-Tuning 技术,它能够识别并修正自身推理中的错误,进而提高模型的准确性。
为了增强用户与模型的交互体验,Reflection 70B 引入了新的特殊标记,使得模型在推理过程中可以实时输出其推理过程,允许用户在错误发生时进行即时纠正。
在面临用户反馈和技术挑战的同时,HyperWrite 计划进一步完善 Reflection 70B,并推出更大规模的 405B 模型。Shumer 表示,他们正在探索将 Reflection 70B 集成到 HyperWrite 的主要 AI 写作助手中,以便更好地服务于用户。
尽管当前的发布引发了争议,Shumer 仍然对未来充满信心,认为 Reflection 系列将超越现有闭源模型,推动开源 AI 的发展。
当前的讨论表明,Reflection 70B 的技术潜力与市场推广之间存在明显的差距。尽管 Shumer 的团队展现了对 AI 发展的热情和创新,但用户的实际体验和反馈却提出了严峻的挑战。
Reflection 70B 是否真如其所宣称的那样是一场技术革命,还是仅仅是 AI 热潮中的又一次炒作?这一切仍有待时间的检验。在持续发展的 AI 生态中,实事求是的态度和对技术的深度反思将是推动行业前进的关键。
位置编码 (Position Encoding, PE) 是一种给 Transformer 模型引入位置信息的机制。因为 Transformer 的注意力机制本质上对输入序列中的位置信息无感知,所以需要通过 PE 来传递序列的位置信息。传统的 PE 方法分为两类:绝对位置编码和相对位置编码。
速记句:位置编码就是帮助 Transformer 知道“谁离谁近”。
现有的 PE 方法主要基于token的数量来计算位置,但当需要在更抽象的层面(如句子级别)进行操作时,这种方法会失效。例如,模型可能需要知道句子间的关系,而不是简单地知道某个 token 在序列中的位置。
速记句:传统位置编码无法处理更高层次的抽象。
研究表明,标准的 PE 方法在一些简单的任务上表现不佳。例如,数数任务中,模型需要准确地定位某个特定的 token,或者需要数数某种特定类型的 token,但标准的 PE 方法无法有效处理这些任务。
速记句:标准位置编码在复杂上下文中的表现不稳定。
CoPE 是一种新型的位置编码方法,能够根据上下文动态调整位置。具体来说,CoPE 不再简单地为每个 token 计算位置,而是根据上下文决定哪些 token 应该被“计数”,从而动态生成位置。
CoPE 的核心机制是通过门控函数 (gating function) 来决定哪些 token 参与位置计算。门控函数的值由当前 token 的查询向量与其他 token 的键向量决定。
速记句:CoPE 会“选择性地”数数。
CoPE 的核心计算过程包括以下步骤:
CoPE 的优势在于它能处理更复杂的抽象任务,如:
实验表明,CoPE 在多个任务上表现优异,包括语言建模任务和代码建模任务。尤其在处理长距离依赖的任务上,CoPE 明显优于传统 PE 方法。另外,CoPE 对上下文长度的泛化能力也表现出色,能够处理比训练时更长的上下文。
速记句:CoPE 在广泛的任务中表现出色,尤其是长距离依赖任务。
CoPE 的计算开销主要集中在门控函数的计算以及位置的累加上,虽然这增加了计算复杂度,但通过优化(如限制最大位置),可以有效减少额外的计算量。
速记句:计算虽有增加,但优化策略能降低负担。
尽管 CoPE 在多个任务上有出色表现,但其局限性在于:目前尚未在更大规模的模型(如数十亿参数)上进行测试,且可能在其他领域(如视频和音频数据)中有待进一步验证。
速记句:CoPE 还需要在更大规模数据和领域上验证。
未来,CoPE 有潜力扩展到其他领域,如视频和语音识别等。此外,进一步研究如何将 CoPE 应用于更大规模的模型,以及在更多下游任务中的表现,将是未来工作的重点。
速记句:CoPE 的未来应用空间广阔,值得进一步探索。
CoPE 是一种新颖的、基于上下文的动态位置编码方法,能够在复杂的数数和抽象任务中表现出色。相比于传统的 PE 方法,CoPE 更加智能化,能够根据上下文动态调整位置计算,并且在处理长距离依赖任务中表现尤为出色。
在人工智能的世界里,每一天都可能发生惊天动地的变化。就在昨天,我们还在为某个模型的强大性能惊叹不已,今天,一个新的”王者”就已经闪亮登场了。各位看官,请允许我隆重介绍:来自HyperWrite公司的Reflection 70B模型!
🌟 惊艳登场:从默默无闻到惊艳四座
想象一下,在一个热闹非凡的AI模型选美大赛上,突然有一位神秘选手踏着闪耀的星光登场。这位选手就是HyperWrite公司的联合创始人兼CEO Matt Shumer刚刚推出的Reflection 70B模型。
就像童话故事里的灰姑娘突然变身为迷人的公主,Reflection 70B的出现立刻引起了全场的注目。Matt Shumer在社交网络X(原Twitter)上自豪地宣布:”我很高兴向大家介绍Reflection 70B,这是目前世界上最顶尖的开源AI模型。”
这番豪言壮语可不是空口白话。Reflection 70B在多项第三方基准测试中的表现都相当出色,甚至超越了许多知名的商业模型。这就好比一个默默无闻的小将在奥运会上一举夺魁,让所有人都大吃一惊。
🔍 自我反思:AI界的”三省吾身”
Reflection 70B最与众不同的地方在于它的”自我反思”能力。想象一下,如果你有一个助手,他不仅能帮你完成各种任务,还能主动发现并纠正自己的错误,那该有多棒?这正是Reflection 70B的独特之处。
Matt Shumer解释道:”我一直在思考这个问题:大语言模型会产生幻觉,但它们无法自我纠正。如果我们教会一个大语言模型如何识别并修复自己的错误会怎样呢?”
这就好比我们在学习过程中,不仅要学会解题,还要学会检查自己的答案,发现并改正错误。Reflection 70B就像一个聪明的学生,在给出答案之前,会先仔细检查自己的推理过程,确保不会出错。
🧪 反思调优:AI的”三思而后行”
Reflection 70B的核心秘密就在于一种名为”反思调优”(Reflection-Tuning)的技术。这项技术让模型能够在给出最终答案之前,先检查自己的推理过程,发现并纠正可能存在的错误。
想象一下,如果你在解一道复杂的数学题,你会怎么做?你可能会先列出解题步骤,然后逐步计算,最后再检查一遍确保没有错误。Reflection 70B就是用类似的方法来提高自己的准确性。
Reflection 70B引入了几个新的特殊标记,用于推理和错误纠正。这就像是给模型配备了一个内置的”检查员”,随时监督它的输出,一旦发现问题就立即纠正。这种方法使得Reflection 70B在需要高度准确性的任务中表现特别出色。
🔮 Reflection 405B:AI界的”大魔王”?
如果说Reflection 70B是AI界的新王者,那么即将推出的Reflection 405B可能就是真正的”大魔王”了。Matt Shumer透露,这个更大规模的模型将在下周发布,而且有望超越市场上所有的闭源模型。
这就好比在一场激烈的赛车比赛中,Reflection 70B刚刚夺得了冠军,而更强大的Reflection 405B已经在赛道上热身,准备创造新的世界纪录。
🦸♂️ Glaive:AI训练的”神助攻”
在Reflection 70B的成功背后,有一个重要的幕后功臣——Glaive。这家由荷兰工程师Sahil Chaudhary创立的初创公司专注于创建特定用途的数据集。
想象一下,如果你要训练一个AI来识别不同品种的狗,你需要大量的狗狗照片。Glaive就像是一个神奇的照相机,能快速生成你需要的各种狗狗照片,让你的AI训练事半功倍。
Matt Shumer对Glaive赞不绝口:”Glaive是这次成功的关键原因。他们在生成合成数据方面的控制力简直是疯狂的。”有了Glaive的帮助,Reflection团队能够在短短几小时内生成高质量的合成数据,大大加快了模型的训练速度。
Reflection 70B的横空出世,无疑为开源AI领域注入了一剂强心针。它向世人展示了开源模型也能够与顶级商业模型一较高下,甚至在某些方面更胜一筹。
就像一个默默无闻的小镇突然培养出了一位世界级的运动员,HyperWrite这家来自纽约长岛的小公司,用Reflection 70B向全世界证明了自己的实力。
随着Reflection 405B的即将到来,我们或许正站在AI技术革命的风口浪尖。谁知道呢,也许在不久的将来,我们每个人的电脑里都会有一个像Reflection这样强大而又谦逊的AI助手,帮助我们更好地工作和生活。
让我们一起期待AI的美好未来吧!
参考文献:
在信息检索的世界里,如何快速而准确地从海量文档中找到最相关的信息一直是一个重要而富有挑战性的问题。近年来,随着大型语言模型(LLMs)的蓬勃发展,研究人员们开始探索如何利用这些强大的语言理解工具来改进文档检索的效果。然而,直接将LLMs应用于检索任务面临着两个主要挑战:一是计算成本高昂,二是需要大量标注数据进行训练。
今天,我们要介绍一种突破性的方法 – PromptReps,它巧妙地解决了这些难题,为零样本文档检索开辟了一条崭新的道路。
PromptReps的核心思想非常简单而优雅:通过精心设计的提示(prompt),引导大型语言模型为文档和查询生成密集(dense)和稀疏(sparse)表示。这些表示可以直接用于构建高效的检索系统,而无需任何额外的训练过程。
让我们来看看PromptReps是如何实现这一魔法的:
研究者们在多个基准数据集上评估了PromptReps的性能,结果令人振奋:
研究者们还探索了PromptReps的多种变体,以进一步提升其性能:
这些变体的实验结果表明,最简单的”首标记单一表示”方法在大多数情况下就能取得最佳效果,彰显了PromptReps设计的巧妙性。
PromptReps为LLM在信息检索领域的应用开辟了一条崭新的道路。未来的研究方向可能包括:
PromptReps的提出展示了提示工程在释放预训练语言模型潜力方面的强大作用。它不仅为零样本文档检索提供了一种高效、灵活的解决方案,也为我们思考如何更好地利用大型语言模型解决实际问题提供了新的视角。随着这一领域的不断发展,我们有理由期待看到更多激动人心的创新,推动信息检索技术迈向新的高度。
想象一下,你有一个无所不知的AI助手,它不仅能回答各种问题,还能帮你在海量文档中快速找到所需信息。听起来很酷,对吧?但现实中,让AI完成这样的任务并非易事。
目前,利用大语言模型(LLMs)进行”零样本”文档排序主要有两种方式:一是基于提示的重排序方法,无需额外训练但计算成本高,只能对少量候选文档进行重排;二是无监督的对比学习密集检索方法,可以从整个语料库中检索相关文档,但需要大量配对文本数据进行对比训练。
那么,有没有一种方法既不需要训练,又能高效检索整个语料库呢?今天要介绍的PromptReps方法,就像是AI界的”变形金刚”,兼具了上述两种方法的优点 – 无需训练,却能高效检索整个语料库。它是如何做到的呢?让我们一起来揭开这个AI”变形金刚”的神秘面纱吧!
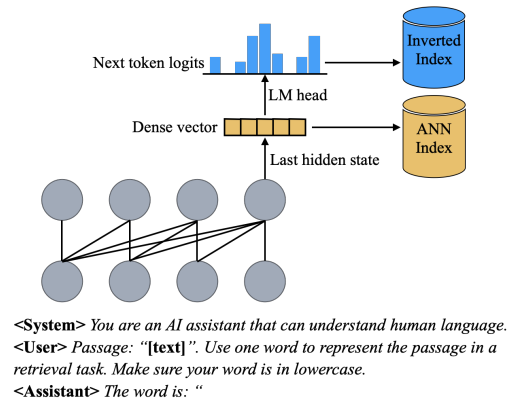
PromptReps的核心思想非常巧妙:通过精心设计的提示,引导大语言模型同时生成密集和稀疏的文本表示,然后用这些表示构建搜索索引。这就像是教会了AI一种新的”语言”,让它能够用简洁而富有信息量的方式描述文档内容。
具体来说,PromptReps的工作流程如下:
这种方法就像是教会了AI用两种不同的”语言”来描述文档:一种是”密语”(密集表示),捕捉文档的整体语义;另一种是”关键词”(稀疏表示),突出文档的重点内容。这样,无论用户以何种方式描述需求,AI都能快速找到相关文档。
为了验证PromptReps的效果,研究人员在多个数据集上进行了实验,包括MSMARCO、TREC深度学习和BEIR零样本文档检索数据集。结果表明,这种简单的基于提示的LLM检索方法能够达到甚至超过当前最先进的、经过大规模无监督数据训练的LLM嵌入方法的检索效果,尤其是在使用更大规模LLM时。
让我们来看一些具体数据:
| 数据集 | BM25 | E5-PTlarge | LLM2Vec | PromptReps (Llama3-70B-I) |
|---|---|---|---|---|
| BEIR平均 | 43.70 | 44.61 | 41.38 | 45.88 |
| TREC-COVID | 59.47 | 61.8 | 63.34 | 76.85 |
| NQ | 30.55 | 41.7 | 37.65 | 46.97 |
从这些数据可以看出,PromptReps在多个数据集上都表现出色,尤其是在TREC-COVID和NQ数据集上,大幅超越了其他方法。这说明PromptReps不仅能够有效捕捉文档的语义信息,还能很好地适应不同类型的检索任务。
PromptReps的成功为AI文档检索领域开辟了新的方向。未来,我们可以期待以下发展:
PromptReps的出现,标志着AI文档检索技术进入了一个新的阶段。它不仅展示了大语言模型的强大潜力,也为解决实际应用中的检索问题提供了一种高效、灵活的解决方案。随着这项技术的不断发展和完善,我们可以期待看到更多创新应用,让AI真正成为我们获取信息的得力助手。
未来,当你面对海量信息时,也许只需轻声对AI说:”帮我找找相关资料”,它就能像变形金刚一样,瞬间变身为你的专属搜索引擎,为你展现信息的海洋。让我们一起期待AI检索技术的美好未来吧!
在人工智能的发展历程中,我们总是在寻找让机器更像人类思考的方法。最近,谷歌DeepMind的研究人员在这条道路上又迈出了一大步。他们发现,即使不给予明确的提示,预训练的大型语言模型也能展现出令人惊叹的推理能力。这项突破性的研究成果被命名为”无提示链式思维推理”(Chain-of-Thought Reasoning Without Prompting)。今天,让我们一起深入探讨这项创新技术,看看它如何为AI的未来铺平道路。
🧠 思维链解码:揭秘AI的内在推理过程
想象一下,你正在解决一道数学题。你不会直接得出答案,而是会经历一系列的思考步骤。这就是所谓的”思维链”。传统上,我们需要通过精心设计的提示来引导AI模型生成这样的思维链。但是,谷歌DeepMind的研究人员发现,这种能力其实已经潜藏在预训练模型的内部。
他们开发了一种名为”CoT-decoding”的方法,可以从模型生成的多个可能路径中筛选出最可靠的推理链。这就像是在AI的大脑中安装了一个”思维显微镜”,让我们能够观察到它内部的推理过程。
🔍 深入CoT-decoding:AI推理的新视角
CoT-decoding的核心思想是利用模型在生成过程中的不确定性。当模型生成下一个词时,它实际上是在考虑多个可能的选择。传统方法通常只选择概率最高的词,但CoT-decoding则保留了多个可能性,形成了一个”思维树”。
这个过程可以用一个形象的比喻来解释:想象AI在解决问题时,不是走在一条直线上,而是在一个迷宫中探索。CoT-decoding就像是给AI配备了一个智能导航系统,能够同时探索多条路径,最终找到最合理的解决方案。
📊 实验结果:令人惊叹的推理能力
为了验证这种方法的有效性,研究人员使用了Mistral-7B-Instruct模型进行实验。让我们来看一个具体的例子:
问题:尼古拉斯·凯奇出生在奇数年还是偶数年?
模型生成了10个不同的回答路径,每个路径都有一个可信度分数。最高分的回答是:
尼古拉斯·凯奇出生于1964年1月7日。1964年是偶数,因为它是2的倍数。因此,尼古拉斯·凯奇出生在偶数年。这个回答不仅给出了正确的结论,还展示了清晰的推理过程。更令人惊讶的是,模型能够自主地生成这样的思维链,而不需要任何特殊的提示。
🧪 深入实验:解开复杂问题的AI思维
研究人员还尝试了更复杂的问题。例如:
珍妮特的鸭子每天下16个蛋。她每天早上吃三个,用四个给朋友做松饼。剩下的她每天在农贸市场以每个新鲜鸭蛋2美元的价格出售。她每天在农贸市场能赚多少美元?对于这个问题,模型生成了多个推理路径。最高分的回答是:
让我们先计算珍妮特在食用早餐和烘烤松饼后剩下多少个鸭蛋。
1. 珍妮特吃掉3个鸭蛋做早餐,所以她还剩:
剩余鸭蛋 = 鸭子每天下蛋数 - 早餐用蛋数
= 16个蛋/天 - 3个蛋/天
= 13个蛋/天
2. 她用4个鸭蛋烘烤松饼,所以她还剩:
剩余鸭蛋 = 早餐后剩余蛋数 - 烘烤松饼用蛋数
= 13个蛋/天 - 4个蛋/天
= 9个蛋/天
现在,让我们计算她在农贸市场出售这些鸭蛋能赚多少钱。
3. 她每个鸭蛋卖2美元,所以她的日收入是:
日收入 = 剩余鸭蛋数 * 每个鸭蛋售价
= 9个蛋/天 * 2美元/个
= 18美元/天
所以,珍妮特每天在农贸市场能赚18美元。这个回答不仅正确,还展示了详细的计算过程和清晰的推理链。它证明了模型能够处理多步骤的数学问题,并以人类可理解的方式呈现解题思路。
🚀 CoT-decoding的影响:AI的未来
CoT-decoding的出现为AI研究开辟了新的方向。它不仅提高了模型的推理能力,还为我们理解AI的”思维过程”提供了宝贵的洞察。这项技术的潜在应用十分广泛,从教育到科研,再到复杂决策支持,都可能因此受益。
想象一下,未来的AI助手不仅能给出答案,还能详细解释推理过程。这将大大提高AI系统的可解释性和可信度,让人类用户更容易理解和接受AI的决策。
🔮 展望未来:AI推理的新篇章
CoT-decoding的出现,标志着我们正在进入AI推理能力的新纪元。它揭示了预训练语言模型中潜藏的推理能力,为未来的AI系统开发提供了新的思路。
随着这项技术的进一步发展,我们可能会看到更加智能、更具解释力的AI系统。它们不仅能够解决复杂问题,还能像人类专家一样清晰地阐述推理过程。这将为人机协作开辟新的可能性,让AI真正成为人类智慧的得力助手。
CoT-decoding的研究才刚刚开始,但它已经展现出改变AI领域的潜力。让我们期待这项技术在未来会带来更多令人兴奋的突破!
参考文献:
在人工智能的浩瀚宇宙中,我们正在见证一场思维的革命。想象一下,如果我们能让AI像人类一样,在解决问题时展现出清晰的思路和逻辑链条,而不是仅仅给出一个简单的答案。这就是本文要探讨的主角——思维链解码(Chain-of-Thought Decoding,简称CoT-Decoding)。它就像是给AI装上了一个”透明脑袋”,让我们能够一窥其推理过程的奥秘。
🧠 解码的艺术:从贪婪到思维链
传统的解码方法,就像是一个贪吃的小孩,总是急着抓住眼前最大的糖果。这种方法我们称之为贪婪解码(Greedy Decoding)。它的工作原理非常直观:
这种方法虽然简单快速,但往往会错过更好的选择。就像贪吃的小孩可能会错过后面更大更甜的糖果一样。
而CoT-Decoding则像是一个有耐心的侦探,不急于下结论,而是仔细考虑多种可能性。它的工作流程是这样的:
这个过程可以用一个数学公式来描述:
$S_i = \frac{1}{|a|} \sum_{t=1}^{|a|} (p(x_t^{(1)}) – p(x_t^{(2)}))$
其中,$S_i$ 是第 $i$ 条推理路径的可信度得分,$|a|$ 是答案的长度,$p(x_t^{(1)})$ 和 $p(x_t^{(2)})$ 分别是每一步解码中概率最高和第二高的词的概率。
这个公式看起来可能有点复杂,但其实它在做一件很简单的事:计算每一步解码中最可能的词和次可能的词之间的概率差,然后把这些差值加起来,再除以答案的长度。这样,我们就得到了一个衡量整个推理路径可靠性的分数。
🎭 CoT-Decoding:模型的多重人格
CoT-Decoding就像是给模型注入了多重人格。每个”人格”都从一个不同的起点出发,独立思考,最后我们选择最有说服力的那个”人格”的答案。这种方法有几个显著的优点:
🔬 实验结果:CoT-Decoding的惊人表现
研究者们进行了一系列实验,结果令人振奋。以下是一些关键发现:
🎨 CoT-Decoding:AI的思维调色盘
CoT-Decoding就像是给AI配备了一个思维调色盘。传统的解码方法只能画出黑白的推理过程,而CoT-Decoding则能绘制出丰富多彩的思维图景。它不仅让我们看到了AI是如何一步步得出结论的,还让我们能够比较不同推理路径的优劣。
这种方法的意义远不止于提高准确率。它为我们打开了一扇窗,让我们能够更深入地理解AI的思维过程。通过观察不同的推理路径,我们可以发现模型的优势和局限性,从而有针对性地改进模型。
📚 结语:迈向更智能的AI未来
CoT-Decoding的出现,标志着我们在追求”可解释AI”的道路上迈出了重要一步。它不仅提高了模型的性能,还增强了模型的可信度和透明度。在未来,我们可以期待看到更多基于CoT-Decoding的应用,从更复杂的问题求解到更自然的人机交互。
正如爱因斯坦曾说:”如果你不能向一个六岁的孩子解释清楚,那你自己可能也不够了解。”CoT-Decoding就像是让AI学会了向我们解释它的思考过程。它不仅让AI变得更聪明,还让AI变得更容易理解和信任。
在这个AI快速发展的时代,CoT-Decoding无疑是一个激动人心的突破。它为我们展示了一幅美好的图景:在不久的将来,AI不仅能给出答案,还能清晰地解释它是如何得出这个答案的。这不仅是技术的进步,更是人类与AI之间沟通的一次飞跃。
让我们共同期待,在CoT-Decoding的引领下,AI世界会绽放出更多精彩纷呈的智慧之花。
参考文献:
在数据驱动的时代,如何有效地检索和处理信息变得愈发重要。Pyserini 是由滑铁卢大学数据系统组维护的工具,可以帮助用户将自己的数据整合到 dspy.Retrieve 中。本文将介绍 Pyserini 的基本使用方法,重点是如何将其与 DSPy 框架结合使用,以实现高效的检索和信息处理。
在开始使用 dspy.Pyserini 之前,我们需要安装 Pyserini、Pytorch 和 Faiss。可以通过以下命令安装 Pyserini:
pip install pyserini如果您在自己的设备上运行,请根据需要选择合适版本的 Pytorch 和 Faiss。在 Colab 上,请确保选择 GPU 作为硬件加速器。可以在 “编辑 > 笔记本设置 > 硬件加速器” 中进行选择。
以下是完整的安装和设置代码:
%load_ext autoreload
%autoreload 2
import sys
import pkg_resources
try:
repo_path = 'dspy'
!git -C $repo_path pull origin || git clone https://github.com/stanfordnlp/dspy $repo_path
%cd $repo_path
!pip install -e .
if "pyserini" not in {pkg.key for pkg in pkg_resources.working_set}:
!pip install pyserini
if "torch" not in {pkg.key for pkg in pkg_resources.working_set}:
!pip install torch
if "faiss-cpu" not in {pkg.key for pkg in pkg_resources.working_set}:
!pip install faiss-cpu
except:
repo_path = '.'
if "dspy-ai" not in {pkg.key for pkg in pkg_resources.working_set}:
!pip install -U pip
!pip install dspy-ai
if repo_path not in sys.path:
sys.path.append(repo_path)
import dspyPyserini 提供了一些预构建的索引,可以直接使用。以下是一个示例,展示如何初始化和使用 Pyserini 的预构建索引:
pys_ret_prebuilt = dspy.Pyserini(index='beir-v1.0.0-nfcorpus.contriever-msmarco', query_encoder='facebook/contriever-msmarco', id_field='_id', text_fields=['title', 'text'])
dspy.settings.configure(rm=pys_ret_prebuilt)
example_question = "How Curry Can Kill Cancer Cells"
retrieve = dspy.Retrieve(k=3)
topK_passages = retrieve(example_question).passages
print(f"Top {retrieve.k} passages for question: {example_question} \\n", '-' * 30, '\\n')
for idx, passage in enumerate(topK_passages):
print(f'{idx+1}]', passage, '\\n')运行以上代码后,您将获得与输入问题相关的前 3 个段落的检索结果。这些段落来自于预构建的 Wikipedia 索引,内容涉及如何利用咖喱成分(如姜黄素)治疗癌细胞等信息。
接下来,我们将使用 NFCorpus,这是一个用于医学信息检索的全文本学习排名数据集。首先,下载数据集并解压:
!wget https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/nfcorpus.zip -P collections
!unzip collections/nfcorpus.zip -d collections接下来,使用 Pyserini 对数据进行编码并打包到 Faiss 索引中:
!python -m pyserini.encode \
--corpus collections/nfcorpus/corpus.jsonl \
--fields title text \
--embeddings indexes/faiss.nfcorpus.contriever-msmarco \
--to-faiss \
--encoder facebook/contriever-msmarco \
--device cuda:0 \
--pooling mean完成数据编码后,您可以使用 dspy.Pyserini 读取本地 Faiss 索引并进行检索。需要注意的是,使用本地索引时,需要传入 Huggingface 的 Dataset 以便进行文档查找。
from datasets import load_dataset
dataset = load_dataset(path='json', data_files='collections/nfcorpus/corpus.jsonl', split='train')
pys_ret_local = dspy.Pyserini(index='indexes/faiss.nfcorpus.contriever-msmarco', query_encoder='facebook/contriever-msmarco', dataset=dataset, id_field='_id', text_fields=['title', 'text'])
dspy.settings.configure(rm=pys_ret_local)
dev_example = "How Curry Can Kill Cancer Cells"
retrieve = dspy.Retrieve(k=3)
topK_passages = retrieve(dev_example).passages
print(f"Top {retrieve.k} passages for question: {dev_example} \\n", '-' * 30, '\\n')
for idx, passage in enumerate(topK_passages):
print(f'{idx+1}]', passage, '\\n')运行以上代码,您将获得与输入问题相关的段落,这些段落来自于您自己的数据集。
通过本文,您了解了如何使用 Pyserini 和 DSPy 进行数据检索与处理。无论是使用预构建索引还是您自己的数据集,DSPy 都提供了一种灵活的方式来实现高效的信息检索。未来,您可以进一步探索 DSPy 的更多功能,通过优化检索和回答生成流程,提升您的应用性能。