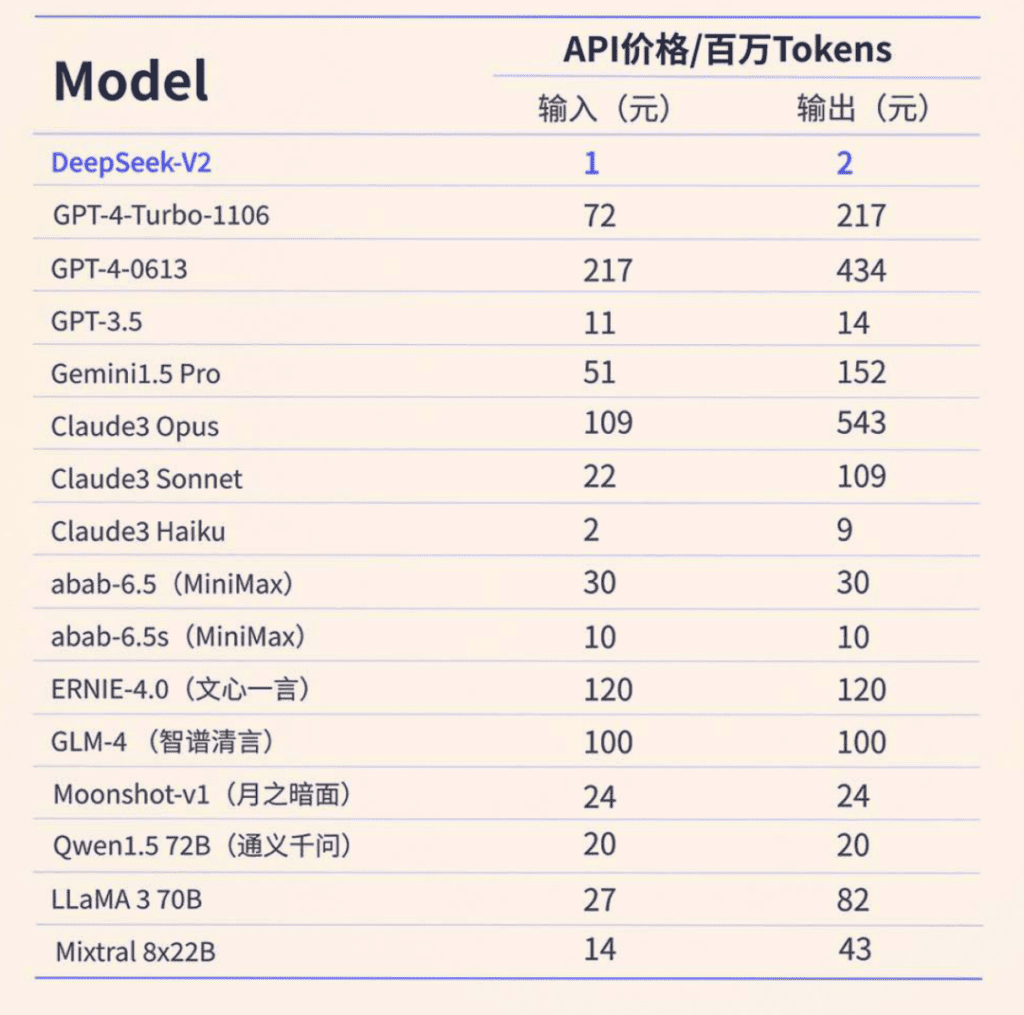
在人工智能领域,技术的迭代更新速度令人眼花缭乱。最近,幻方科技发布的DeepSeek-V2模型因其创新的多头潜在注意力(MLA)技术而引起了广泛关注。这一技术不仅大幅降低了运算成本,还保持了高效的模型性能,其价格之低让人震惊,足以颠覆现有的市场格局。本文将带您了解从多头注意力(MHA)到多头潜在注意力(MLA)的技术演进历程,以及这一变革对未来人工智能应用的深远影响。
多头注意力(MHA):AI领域的革命
多头注意力机制最初由2017年的论文《Attention is all you need》中提出,它是现代大型语言模型的基石。这项技术通过将输入数据分割成多个头部,然后并行处理,能够有效地捕捉数据中的不同方面信息,极大地提升了模型处理复杂数据的能力。
在多头注意力中,每个头部独立地从数据中学习不同的特征,然后将这些特征综合起来,形成对输入数据的全面理解。这种机制不仅增加了模型的表达能力,还提高了处理速度,是许多先进模型能够实现快速、准确预测的关键。
缓存机制和性能的平衡
尽管多头注意力极大地推动了模型性能的提升,但其对计算资源的需求也相应增加。在实际应用中,为了加速预测过程并减少计算资源的消耗,技术人员常常采用键值缓存(KV Cache)技术。这种技术可以存储已经计算过的结果,当需要重复使用时可以直接调用,避免了重复的计算过程。
然而,KV Cache也有其局限性,特别是在处理大型模型和长输入序列时,其所需的内存量会急剧增加,这对于资源有限的设备是一个不小的挑战。
多头潜在注意力(MLA):效率与性能的新高度
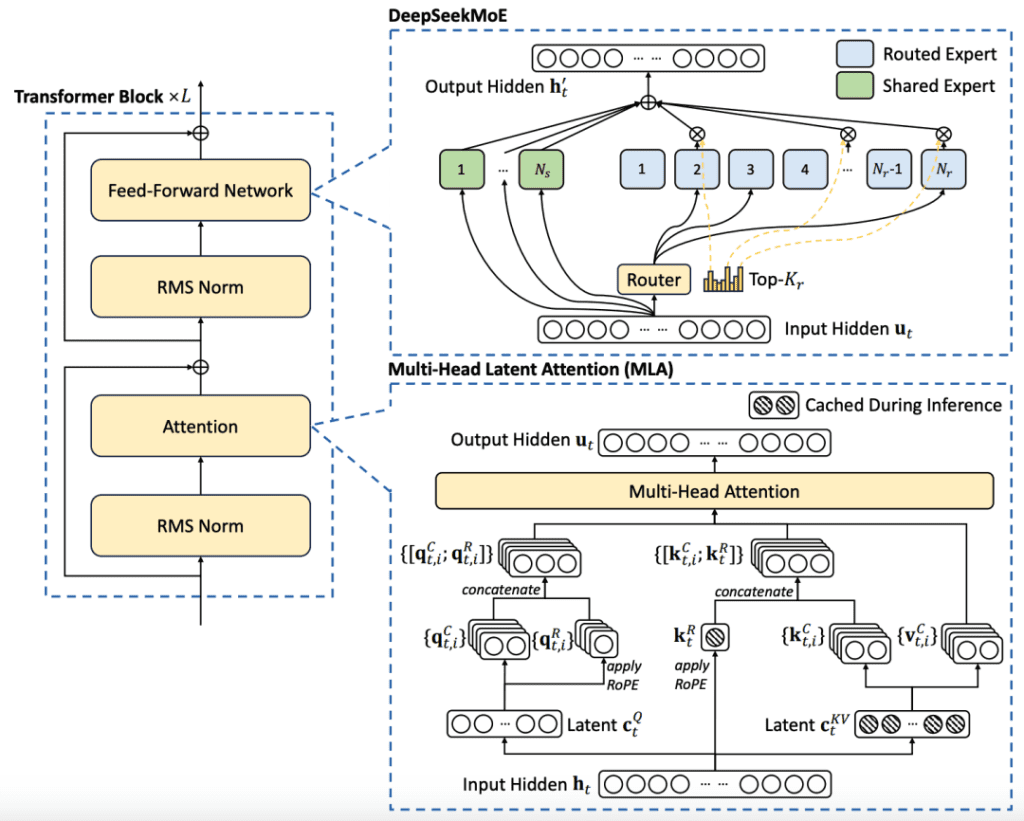
为了解决这一问题,幻方科技的DeepSeek-V2模型采用了创新的多头潜在注意力机制。MLA在设计上对传统多头注意力机制进行了优化,通过更高效的数据处理和缓存管理,显著减少了对计算资源的需求。
具体来说,MLA通过改进算法减少了对内存的依赖,同时确保模型输出的质量不受影响。这一点在资源受限的设备上尤为重要,因为它允许这些设备运行先进的模型,执行复杂的任务,而不会耗尽所有的计算资源。
MLA技术的核心原理
多头潜在注意力机制在设计上对传统多头注意力机制进行了重要的改进。核心思想是在保持注意力模型效能的同时,优化内存使用和计算效率。
1. 参数共享: MLA通过在多个注意力头之间共享部分参数来减少模型的总参数量。这种参数共享不仅减少了内存占用,还有助于加速模型的训练和推理过程。
2. 动态稀疏性: 与传统的注意力机制每次处理所有数据不同,MLA引入了动态稀疏性。它通过算法智能地选择在每次前向传播中最重要的信息子集,从而减少了不必要的计算负担。
3. 潜在特征空间: MLA引入了一个潜在特征空间,用于更高效地编码和处理信息。在这个空间中,相似的输入特征会被映射到接近的位置,这样模型就可以通过学习这些潜在关系来提高处理速度和效率。
MLA的优势与应用
MLA的设计允许它在多种场景下展现出色的性能和效率,使其成为许多行业的理想选择。
1. 资源限制环境: 在移动设备和嵌入式系统等资源受限的环境中,MLA通过减少计算量和内存需求,使得复杂的模型得以运行。
2. 实时处理需求: 对于需要实时数据处理的应用,如自动驾驶和实时翻译,MLA能够提供必要的速度和响应能力。
3. 大规模模型: 在数据中心和云计算环境中,MLA可以减少大规模模型运行所需的能源和硬件资源,这对于环境的可持续性和运营成本都是重大利好。
展望未来
MLA的出现不仅是技术上的一次突破,更是开辟了人工智能在各行各业应用的新可能。从医疗健康、自动驾驶到智能制造,MLA的高效性和经济性将使更多的企业能够利用AI技术解决实际问题,推动社会生产力的进一步提升。