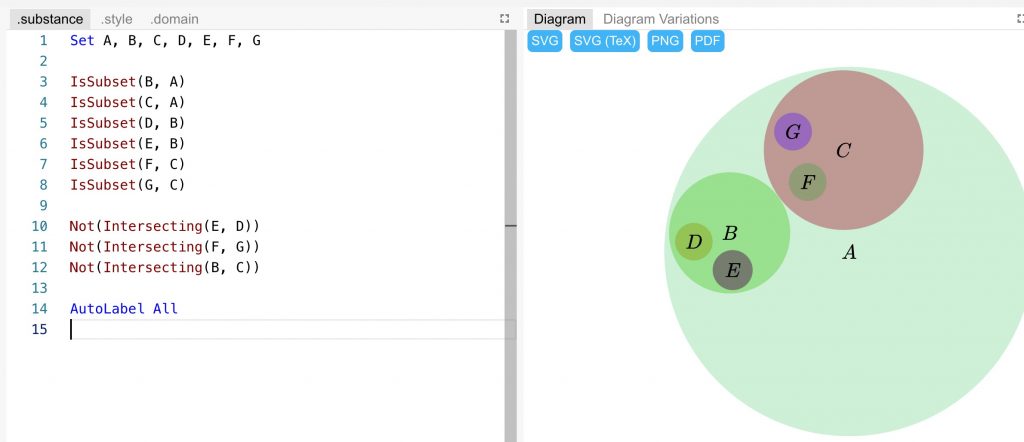
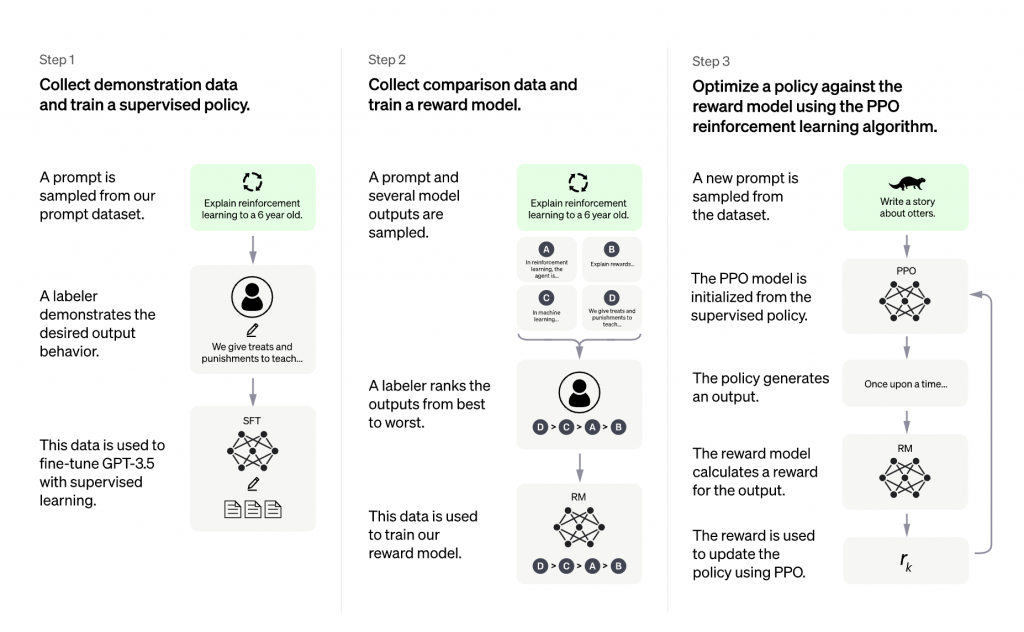
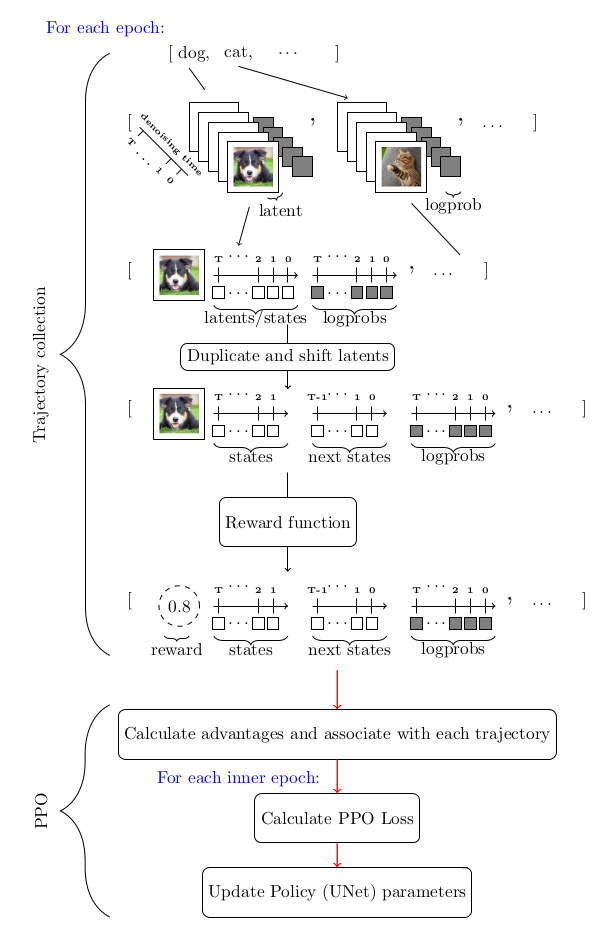
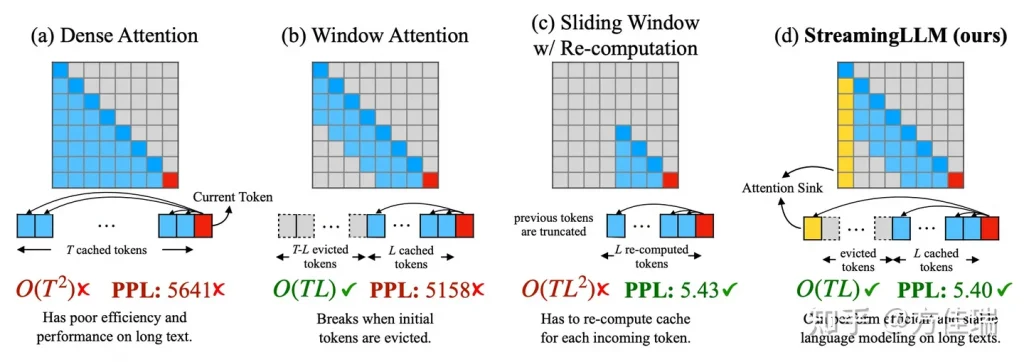
欢迎各位读者,我们今天将要探索的主题是Cython的并行编程功能。如果你是一名Python开发者,对于如何提升代码运行效率感兴趣,那么本文定会让你大开眼界。Cython是一个强大的工具,它能让Python代码运行得更快,而且还支持原生的并行化。今天,我们要深入探索的正是Cython 3版本的并行模块。
Cython并行模块的使用需要明确两种语法:Cython专有的cdef语法和纯Python语法。这两种语法都能让我们在Python代码中使用C数据类型,只需要导入特殊的cython模块即可。值得注意的是,使用纯Python语法时,我们强烈推荐你使用最新的Cython 3版本。
Cython通过cython.parallel模块支持原生并行化。要使用此类并行化,必须释放GIL(Python全局解释器锁)。目前,Cython支持OpenMP,未来可能会支持更多后端。
并行循环:cython.parallel.prange()
Cython提供了一个名为prange的函数,用于并行循环开发。prange函数会自动启动一个线程池,并根据设定的调度策略分配工作。它的使用方式与Python的range函数相似,但是提供了更多功能,包括线程局部变量、变量归约和私有变量。以下是两个简单的例子,一个使用纯Python语法,一个使用Cython语法:
from cython.parallel import prange
i = cython.declare(cython.int)
n = cython.declare(cython.int, 30)
sum = cython.declare(cython.int, 0)
for i in prange(n, nogil=True):
sum += i
from cython.parallel import prange
cdef int i
cdef int n = 30
cdef int sum = 0
for i in prange(n, nogil=True):
sum += i
并行区域:cython.parallel.parallel()
Cython还提供了parallel指令,它可以用在with语句中,以并行方式执行代码序列。这在设置prange中用于线程局部缓冲区的情况下非常有用。下面的例子展示了如何使用线程局部缓冲区:
from cython.parallel import parallel, prange
from cython.cimports.libc.stdlib import abort, malloc, free
@cython.nogil
@cython.cfunc
def func(buf: cython.p_int) -> cython.void:
pass
# ...
idx = cython.declare(cython.Py_ssize_t)
i = cython.declare(cython.Py_ssize_t)
j = cython.declare(cython.Py_ssize_t)
n = cython.declare(cython.Py_ssize_t, 100)
local_buf = cython.declare(p_int)
size = cython.declare(cython.size_t, 10)
with cython.nogil, parallel():
local_buf: cython.p_int = cython.cast(cython.p_int, malloc(cython.sizeof(cython.int) * size))
if local_buf is cython.NULL:
abort()
# populate our local buffer in a sequential loop
for i in range(size):
local_buf[i] = i * 2
# share the work using the thread-local buffer(s)
for j in prange(n, schedule='guided'):
func(local_buf)
free(local_buf)
获取线程ID:cython.parallel.threadid()
Cython并行模块还提供了threadid函数,用于获取当前线程的ID。对于n个线程,ID将从0到n-1。
编译
最后,要实# Cython并行编程:揭秘Cython 3.0.5并行模块
欢迎来到我们今天的故事,我要带你一起探索一个神秘的领域——Cython的并行编程。如果你是Python的忠实粉丝,对如何提升Python代码运行效率的问题抱有热切的兴趣,那么这篇文章一定不会让你失望。接下来,我们要深入探讨的是Cython 3.0.5版本的并行模块。
首先,我们需要了解Cython提供了两种语法:Cython专有的cdef语法和纯Python语法。这两种语法都能让我们在Python代码中使用C数据类型,只需要导入特殊的cython模块即可。如果你选择使用纯Python语法,强烈推荐你使用最近的Cython 3版本,这样你将会体验到更多的改进和优化。
Cython通过cython.parallel模块支持原生的并行化。要使用这种并行化,必须释放GIL(Python全局解释器锁)。目前,Cython支持OpenMP,并且未来可能会支持更多的后端。
轻松实现并行循环:cython.parallel.prange()
Cython提供了一个名为prange的函数,用于并行循环开发。当你使用prange时,OpenMP会自动启动一个线程池,并按照你设定的调度策略分配工作。这个函数的参数与Python的range函数相似,但提供了更多的功能,包括线程局部变量和归约,以及最后的私有变量。你可以把prange看作是一个更强大、更灵活的range。
并行区域:cython.parallel.parallel()
除了prange,Cython还提供了parallel函数,它允许你在一个指定的代码块中并行执行多个任务。这在你需要在prange的循环体中使用线程局部缓冲区的场景中特别有用。
获取线程ID:cython.parallel.threadid()
在一些情况下,你可能需要知道当前执行的是哪一个线程。Cython并行模块提供了threadid函数,你可以通过它获取当前线程的ID。
Cython的并行编程功能为Python开发者提供了一个强大的工具,让Python代码能够更好地利用多核处理器的计算能力。这样不仅能提高代码的执行效率,还能在处理大数据或者复杂计算任务时,带来更好的用户体验。
这就是我们今天要分享的内容,感谢你的阅读,希望这篇文章对你有所帮助。在编程的世界中,我们应该始终保持好奇和热情,不断探索未知,并享受其中的乐趣!