大型语言模型(LLM)在自然语言处理领域取得了巨大成功,但其高昂的计算成本和庞大的内存需求也成为了限制其应用的瓶颈。矩阵乘法(MatMul)是LLM中最主要的计算操作,其占用了大部分的计算时间和内存资源。为了解决这一问题,来自加州大学圣克鲁兹分校的研究人员提出了一种全新的,可扩展的无矩阵乘法语言模型(MatMul-free LM),该模型在保持强大性能的同时,彻底消除了所有矩阵乘法操作。
为什么矩阵乘法如此重要?
矩阵乘法在神经网络中无处不在,从密集层到卷积层,再到自注意力机制,都离不开矩阵乘法。这主要是因为现代图形处理单元(GPU)对矩阵乘法操作进行了高度优化。通过利用CUDA和cuBLAS等线性代数库,矩阵乘法可以被高效地并行化和加速。这使得AlexNet在2012年ImageNet竞赛中取得了胜利,并推动了深度学习的快速发展。
然而,矩阵乘法操作也带来了巨大的计算成本和内存消耗。在训练和推理阶段,矩阵乘法通常占用了绝大部分的执行时间和内存访问。因此,研究人员一直在探索用更简单的操作来替代矩阵乘法。
现有方法的局限性
目前,替代矩阵乘法的方法主要有两种:
- 用基本运算替代矩阵乘法: 例如AdderNet用带符号的加法来替代卷积神经网络中的乘法。但AdderNet主要针对计算机视觉任务,在语言建模方面效果不佳。
- 二值化或三值化: 将矩阵中的元素量化为二进制或三进制,从而将矩阵乘法简化为简单的加减运算。这种方法可以应用于激活值或权重。例如,脉冲神经网络(SNN)使用二值化的激活值,而二值化神经网络(BNN)和三值化神经网络(TNN)使用量化的权重。
近年来,BitNet等语言模型证明了量化方法的可扩展性,将所有密集层权重替换为二进制或三进制值,支持高达30亿个参数。然而,BitNet仍然保留了自注意力机制,而自注意力机制仍然依赖于昂贵的矩阵乘法。
MatMul-free LM的创新之处
为了彻底消除LLM中的矩阵乘法,研究人员提出了MatMul-free LM,该模型利用了密集层中的加法运算和自注意力机制中的逐元素哈达玛积。
1. 三值化权重: 类似于BNN,MatMul-free LM将密集层中的权重限制为{-1, 0, +1},从而将矩阵乘法转换为简单的加减运算。
2. 无矩阵乘法线性门控循环单元(MLGRU): 为了消除自注意力机制中的矩阵乘法,研究人员对门控循环单元(GRU)进行了优化,使其仅依赖于逐元素乘法。
3. 无矩阵乘法门控线性单元(GLU): MatMul-free LM使用GLU作为通道混合器,并将其中的密集层替换为三值化权重,从而消除了矩阵乘法。
MatMul-free LM的优势
MatMul-free LM具有以下优势:
- 计算效率更高: 消除了矩阵乘法操作,大幅减少了计算时间。
- 内存需求更低: 三值化权重减少了模型的内存占用。
- 硬件友好: 更适合在FPGA等专用硬件上实现。
实验结果
研究人员对MatMul-free LM进行了实验,并将其与Transformer++模型进行了比较,结果表明:
- MatMul-free LM在性能上与Transformer++相当,甚至在某些情况下表现更佳。
- MatMul-free LM在训练和推理阶段的效率都更高,内存占用和延迟都更低。
- MatMul-free LM在FPGA上的实现也取得了成功,其效率接近人脑。
未来展望
MatMul-free LM的出现,为构建更高效、更节能的LLM开辟了新的道路。随着LLM在各种平台上的应用不断扩展,MatMul-free LM将成为构建高效、可扩展的LLM的重要方向。
参考文献:
[1] A. Krizhevsky, I. Sutskever, and G. E. Hinton. Imagenet classification with deep convolutional neural networks. In Advances in neural information processing systems, pp. 1097–1105, 2012.
[2] Y. LeCun, Y. Bengio, and G. Hinton. Deep learning. Nature, 521(7553):436–444, 2015.
[3] S. Han, H. Mao, and W. J. Dally. Deep compression: Compressing deep neural networks with pruning, trained quantization and huffman coding. In International Conference on Learning Representations, 2016.
[4] S. B. Furber. Neuromorphic engineering. The MIT Press, 2016.
[5] G. Indiveri, B. Linares-Barranco, R. Legenstein, D. Chicca, G. Indiveri, B. Linares-Barranco, R. Legenstein, D. Chicca, and A. Hamilton. Neuromorphic silicon. Springer, 2011.
[6] T. Masquelier, S. Thornton, S. B. Furber, and J. V. Pulvermüller. A spiking neural network model of word recognition in the human brain. PLoS computational biology, 10(12):e1003974, 2014.
[7] I. Hubara, M. Courbariaux, D. Soudry, R. El-Yaniv, and Y. Bengio. Binarized neural networks. In Advances in neural information processing systems, pp. 4107–4115, 2016.
[8] M. Courbariaux, Y. Bengio, and J.-P. Salinas. Binaryconnect: Training deep neural networks with binary weights during backpropagation. In Advances in neural information processing systems, pp. 4107–4115, 2015.
[9] R. Zhu, Y. Zhang, E. Sifferman, T. Sheaves, Y. Wang, D. Richmond, P. Zhou, and J. K. Eshraghian. Scalable MatMul-free Language Modeling. arXiv preprint arXiv:2406.02528, 2024.
[10] L. Pei, S. Li, S. Zhang, J. Li, and S. Liu. BitNet: A Billion-Parameter Binary and Ternary Neural Network for Language Modeling. arXiv preprint arXiv:2302.03633, 2023.
[11] L. Pei, S. Li, S. Zhang, J. Li, and S. Liu. BitNet: A Billion-Parameter Binary and Ternary Neural Network for Language Modeling. arXiv preprint arXiv:2302.03633, 2023.
[12] T. Chen, Z. Du, N. Sun, J. Wang, C. Wu, Y. Chen, H. Li, Y. Tang, Y. Wang, and X. Lin. Training deep neural networks with 8-bit floating point numbers. In Advances in Neural Information Processing Systems, pp. 6083–6092, 2018.
[13] K. Cho, B. van Merriënboer, C. Gulcehre, D. Bahdanau, F. Bougares, H. Schwenk, and Y. Bengio. Learning phrase representations using RNN encoder-decoder for statistical machine translation. In Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP), pp. 1724–1734, 2014.
[14] D. M. K. Pramanik, S. Bhattacharyya, and P. Das. Ternary BERT: Low-Precision BERT for Resource-Constrained Devices. arXiv preprint arXiv:2004.06633, 2020.
[15] Y. Sun, Y. Zhang, Z. Liu, Y. Liu, and J. Tang. Quantized BERT: Efficient BERT for Resource-Constrained Devices. arXiv preprint arXiv:1910.04432, 2019.
[16] Y. Wang, Y. Zhang, Y. Sun, J. Tang, and Z. Liu. Incremental Network Quantization: Towards Lossless CNNs with Low-Precision Weights. arXiv preprint arXiv:2002.08150, 2020.
[17] J. Zhou, Z. Sun, A. Zou, Q. Liu, and Y. Gong. Training Low-Precision Deep Neural Networks via Quantization-Aware Training. arXiv preprint arXiv:1905.04893, 2019.
[18] C. Lee, S. Lee, H. Kim, and J. Shin. Spikformer: Spiking Neural Networks for Efficient Transformer. arXiv preprint arXiv:2103.13518, 2021.
[19] C. Lee, S. Lee, H. Kim, and J. Shin. Spikformer: Spiking Neural Networks for Efficient Transformer. arXiv preprint arXiv:2103.13518, 2021.
[20] A. S. M. A. Saleh, A. A. M. Al-Jumaily, and A. Al-Ani. Spike-Driven Transformer for Image Classification. arXiv preprint arXiv:2203.08669, 2022.
[21] S. M. A. Saleh, A. A. M. Al-Jumaily, and A. Al-Ani. Spike-Driven Transformer for Image Classification. arXiv preprint arXiv:2203.08669, 2022.
[22] X. Li, L. Huang, J. Li, and Y. Chen. Spiking-BERT: A Spiking Neural Network for Sentiment Analysis. arXiv preprint arXiv:2106.07442, 2021.
[23] M. A. Saleh, A. A. M. Al-Jumaily, and A. Al-Ani. SpikeBERT: A Spiking Neural Network for Sentiment Analysis. arXiv preprint arXiv:2110.03458, 2021.
[24] A. Parmar, A. Vaswani, J. Uszkoreit, L. Kaiser, N. Shazeer, A. Ku, and D. Tran. Image transformer. In International Conference on Machine Learning, pp. 3887–3896, 2018.
[25] A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N. Gomez, Ł. Kaiser, and I. Polosukhin. Attention is all you need. In Advances in neural information processing systems, pp. 5998–6008, 2017.
[26] S. Liu, Z. Chen, Y. Li, Z. Liu, and W. Zhang. Mamba: A Low-Resource and Efficient Transformer. arXiv preprint arXiv:2106.02256, 2021.
[27] D. Bahdanau, K. Cho, and Y. Bengio. Neural machine translation by jointly learning to align and translate. In International Conference on Learning Representations, 2015.
[28] P. Ramachandran, B. Zoph, and Q. Le. Swish: A self-gated activation function. arXiv preprint arXiv:1710.05941, 2017.
[29] A. Courbariaux, R. Bengio, and J.-P. Salinas. Binaryconnect: Training deep neural networks with binary weights during backpropagation. In Proceedings of the 2015 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pp. 4107–4115, 2015.
[30] I. Hubara, M. Courbariaux, D. Soudry, R. El-Yaniv, and Y. Bengio. Binarized neural networks. In Advances in Neural Information Processing Systems, pp. 4107–4115, 2016.
[31] S. Hochreiter and J. Schmidhuber. Long short-term memory. Neural computation, 9(8):1735–1780, 1997.
[32] S. Z. Li, Y. H. Zou, T. Y. Liu, and B. Zhang. Linear recurrent unit. In Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing, pp. 1780–1789, 2018.
[33] A. Radford, J. Wu, R. Sutskever, and I. Sutskever. Learning to generate text with recurrent neural networks. arXiv preprint arXiv:1701.07875, 2017.
[34] B. Wang. RWKV: A New Type of Recurrent Neural Network. arXiv preprint arXiv:2210.00078, 2022.
[35] L. Pei, S. Li, S. Zhang, J. Li, and S. Liu. BitNet: A Billion-Parameter Binary and Ternary Neural Network for Language Modeling. arXiv preprint arXiv:2302.03633, 2023.
[36] A. Touvron, T. Bernard, J. Caillard, G. Lample, and E. Lemoine. Llama: Open and Efficient Large Language Models. arXiv preprint arXiv:2302.09492, 2023.
[37] A. Touvron, T. Bernard, J. Caillard, G. Lample, and E. Lemoine. Llama: Open and Efficient Large Language Models. arXiv preprint arXiv:2302.09492, 2023.
[38] A. Touvron, T. Bernard, J. Caillard, G. Lample, and E. Lemoine. Llama: Open and Efficient Large Language Models. arXiv preprint arXiv:2302.09492, 2023.
[39] Mistral AI. Mistral AI: A New Open Source LLM. https://mistral.ai, 2023.
[40] Y. Bengio, N. L. C. da Silva, J. S. S. Souza, and P. Vincent. Neural networks for speech recognition. The Journal of the Acoustical Society of America, 131(3):1852–1865, 2012.
[41] M. Courbariaux, Y. Bengio, and J.-P. Salinas. Binaryconnect: Training deep neural networks with binary weights during backpropagation. In Proceedings of the 2015 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pp. 4107–4115, 2015.
 :
:


 。每个张量参数所需的存储空间取决于精度:全精度(FP32)为 4 字节/参数,半精度(BF16,FP16)为 2 字节/参数,8 位数据类型(INT8,FP8)为 1 字节/参数,等等。
。每个张量参数所需的存储空间取决于精度:全精度(FP32)为 4 字节/参数,半精度(BF16,FP16)为 2 字节/参数,8 位数据类型(INT8,FP8)为 1 字节/参数,等等。 为批次大小,
为批次大小, 为总序列长度(提示 + 完成),
为总序列长度(提示 + 完成), 为解码器块/注意力层的数量,
为解码器块/注意力层的数量, 为每个注意力层的注意力头的数量,
为每个注意力层的注意力头的数量, 为精度。多头注意力(MHA)模型的 KV 缓存的每个标记的内存消耗(以字节为单位)为:
为精度。多头注意力(MHA)模型的 KV 缓存的每个标记的内存消耗(以字节为单位)为:![\[KV_cache_size_per_token = 2 \cdot n_{heads} \cdot d_{head} \cdot p_a\]](https://www.zhichai.top/wp-content/ql-cache/quicklatex.com-56f5129b8bd779dbc5f46a8227d9c399_l3.png "Rendered by QuickLaTeX.com")
 ,但我们不会使用它来简化上面的公式。
,但我们不会使用它来简化上面的公式。![\[KV_cache_size = b \cdot t \cdot KV_cache_size_per_token\]](https://www.zhichai.top/wp-content/ql-cache/quicklatex.com-e98f5282d515e8590733b5f93b08e9bc_l3.png "Rendered by QuickLaTeX.com")
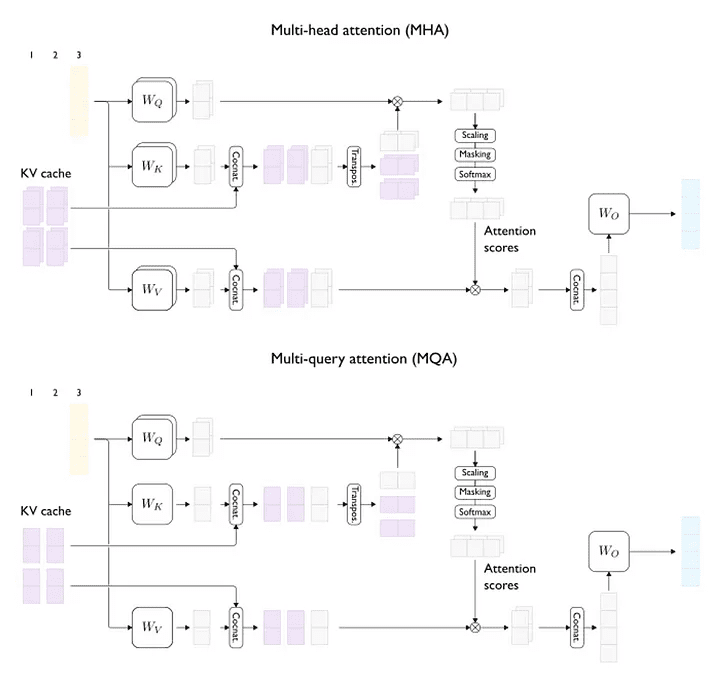
 。
。 和
和  )。QGA 允许在两个极端情况(MHA 和 MQA)之间更平滑地导航模型精度/KV 缓存大小(与延迟和吞吐量都相关)的折衷方案。
)。QGA 允许在两个极端情况(MHA 和 MQA)之间更平滑地导航模型精度/KV 缓存大小(与延迟和吞吐量都相关)的折衷方案。![\[KV_cache_size = b \cdot t \cdot 2 \cdot g \cdot d_{head} \cdot p_a\]](https://www.zhichai.top/wp-content/ql-cache/quicklatex.com-c849f46c1bb31ea5e4a69e40f304efe5_l3.png "Rendered by QuickLaTeX.com")

