Mamman, Hussaini et al., “Unbiasing on the Fly: Explanation-Guided Human Oversight of Machine Learning System Decisions”, 13th Computer Science On-line Conference, Lecture Notes on Networks and Systems, Springer, April 2024.
Udeshi, S., et al., “AEQUITAS: A Fairness Testing Technique for Machine Learning Systems”, 2018.
Galhotra, S., et al., “Themis: Automatically Testing Software for Discrimination”, 2017.
Kusner, M., et al., “Counterfactual Fairness”, 2017.
Yang, S., et al., “BiasRV: Detection of Gender Discrimination in Sentiment Analysis Systems”, 2020.
Adam Dahlgren Lindström, et al. (2024). AI Alignment through Reinforcement Learning from Human Feedback? Contradictions and Limitations. arXiv.
Q: 这篇论文试图解决什么问题?
A: 这篇论文《AI ALIGNMENT THROUGH REINFORCEMENT LEARNING FROM HUMAN FEEDBACK? CONTRADICTIONS AND LIMITATIONS》主要关注和批判性地评估了通过人类反馈的强化学习(Reinforcement Learning from Human Feedback, RLHF)方法来调整人工智能(AI)系统,尤其是大型语言模型(Large Language Models, LLMs),使其与人类价值观和意图一致的尝试。论文指出了这种方法在实现诚实(honesty)、无害(harmlessness)和有帮助(helpfulness)等广泛追求的对齐目标时存在的不足和局限性。
A: 这篇论文《AI ALIGNMENT THROUGH REINFORCEMENT LEARNING FROM HUMAN FEEDBACK? CONTRADICTIONS AND LIMITATIONS》主要探讨了通过人类反馈的强化学习(RLHF)方法在实现人工智能(AI)特别是大型语言模型(LLMs)与人类价值观和意图对齐方面的尝试,并对其存在的矛盾和局限性进行了批判性分析。以下是论文的主要内容总结:
反向传播(Backpropagation,简称 BP)自 1986 年提出以来,一直是深度学习的基本工具。然而,BP 存在两个固有的限制。首先,在正向和反向传播过程中需要权重对称,使得 BP 在生物学上难以实现(Liao et al., 2016)。虽然生物学上的逼真性和学习算法的有效性之间的因果关系尚未明确,但许多深度学习研究都尝试模拟人类的生物和认知过程(Fei et al., 2022;Taniguchi et al., 2022)。其次,正向传播只能在反向传播完全完成后才能启动(反向锁定),反之亦然(正向锁定),这导致计算效率低下,因为并行化受限。此外,由于权重梯度计算需要存储每一层的局部激活,内存使用也不高效。
为了解决这些问题,提出了几种 BP 替代方案。反馈对齐(Feedback Alignment,简称 FA)用固定的随机权重取代对称反馈权重,但仍受到正向/反向锁定的限制。其继任者直接反馈对齐(Direct Feedback Alignment,简称 DFA)直接将误差信号传播到每一层,以缓解反向锁定问题。然而,DFA 并没有解决正向锁定问题。为此,本地监督通过最小化局部损失来利用局部权重更新。具体而言,本地学习(Local Learning,简称 LL)使用模块化辅助网络进行局部 BP,以处理局部输出并与目标对齐进行局部损失计算。尽管辅助网络使现有的 LL 达到了与 BP 相当的性能,但每个模块都使用辅助网络显著增加了模型参数。
本地监督的新方向:前向学习
一种较新的本地监督方法完全消除了 BP 和辅助网络。本文称这种方法为前向学习(Forward Learning,简称 FL)。在 FL 中,每层的权重更新通过层特定的局部损失引导,避免了正向/反向锁定问题,显著提高了计算效率。在没有 BP 和辅助网络的情况下,实施 FL 的关键在于制定局部目标以进行损失计算。例如,前向前向算法(Forward-Forward,简称 FF)通过将独热编码标签叠加到图像上,定义局部目标,将它们视为图像中的单独像素。由于局部输出包含目标信息,基于 FF 的方法通过优化局部输出的自点积来实现对比学习目标。然而,这使得 FL 场景中的对比学习容易受到局部输出中与任务无关的信息的影响,导致性能不如 BP 和 LL。
当前的研究趋势包括 LL 领域的两个重要方向。Nøkland 和 Eidnes(2019)是最早展示非 BP 学习算法能超越 BP 性能的研究之一。他们利用两个不同的局部损失,每个损失都来自一个单独的辅助网络路径。重构损失测量独热编码标签的自相似矩阵与局部特征之间的 L2 距离,而标签预测损失使用交叉熵,这在 BP 和 LL 的局部层中都很常见(Belilovsky et al., 2019;2020;Pathak et al., 2022)。Nøkland 和 Eidnes(2019)还引入了生物学上合理的、无 BP 版本的这些损失,即 LL-bpf。重构损失使用标准差操作代替卷积辅助网络,而标签预测损失使用反馈对齐进行权重更新。
基于 InfoNCE(Oord et al., 2018)的对比目标因负样本数量的大小而敏感(Khosla et al., 2020;Radford et al., 2021;Chen et al., 2020)。这些对比目标,包括 (L_{\text{feat}}),通常使用批内负样本,并且随着批量大小 (N) 增大而表现出更好的性能(Wang et al., 2020;Lee et al., 2018)。相比之下,(L_{\text{dict}}) 中的负样本数量对应于 (Z – 1)。因此,(L_{\text{dict}}) 的有效性取决于类别数量。实验证明,较高的类别数量 (Z) 相对于使用静态标签嵌入向量的情况下,通常表现更好。然而,即使类别较少,竞争力性能仍能达到。
Gu, A., Dao, T. et al. (2024). Transformers are SSMs: Generalized Models and Efficient Algorithms Through Structured State Space Duality. arXiv preprint.
Zhou, W. et al. (2024). 再战Transformer!原作者带队的Mamba 2来了,新架构训练效率大幅提升. 腾讯云开发者社区.
Vaswani, A. et al. (2017). Attention Is All You Need. Advances in Neural Information Processing Systems.
Gu, A., Dao, T. et al. (2023). Mamba: Linear-Time Sequence Modeling with Selective State Spaces. arXiv preprint.
(1) Hello GPT-4o. URL https://openai.com/index/hello-gpt-4o/. … Zou et al. (2023b) Zou, A., Phan, L., Chen, S., Campbell, J., Guo, P., Ren, R., Pan, A., Yin, X., Mazeika, M., Dombrowski, A.-K., et al. Representation engineering: A top-down approach to ai transparency. arXiv preprint arXiv:2310.01405, 2023b.
In the rapidly evolving landscape of artificial intelligence, Large Language Models (LLMs) have become indispensable tools, offering unparalleled capabilities in understanding and generating human-like text. Traditionally, these models have been deployed in data centers equipped with powerful GPUs, but there’s a growing trend to bring these capabilities to more ubiquitous devices like smartphones. This shift aims to leverage rich personal data while maintaining privacy by keeping computations local. However, deploying LLMs on smartphones presents significant challenges due to their limited processing power and memory. Enter PowerInfer-2, a groundbreaking framework from the Institute of Parallel and Distributed Systems (IPADS) at Shanghai Jiao Tong University, designed to tackle these challenges head-on.
Introduction to PowerInfer-2
PowerInfer-2 is an innovative framework specifically engineered for high-speed inference of LLMs on smartphones, even for models whose sizes exceed the device’s memory capacity. The key to PowerInfer-2’s success lies in its ability to utilize the heterogeneous computation, memory, and I/O resources available in modern smartphones. By decomposing traditional matrix computations into fine-grained neuron cluster computations, PowerInfer-2 significantly enhances inference speed and efficiency.
Key Features of PowerInfer-2
Polymorphic Neuron Engine: Adapts computational strategies for various stages of LLM inference.
Segmented Neuron Caching: Minimizes and conceals I/O overhead.
Fine-Grained Neuron-Cluster-Level Pipelining: Reduces computational delays caused by I/O operations.
Support for Large Models: Capable of running models with up to 47 billion parameters.
Technical Insights
Heterogeneous Computation Utilization
PowerInfer-2 leverages the heterogeneous hardware present in smartphones, such as asymmetric big.LITTLE CPU cores, GPUs, and NPUs. This approach allows the framework to dynamically adapt to the strengths of each component during the different stages of LLM inference.
Prefill Stage
During the prefill stage, which processes all tokens in the input sequence concurrently, PowerInfer-2 employs the NPU to handle large matrix computations. This stage benefits from the NPU’s efficiency in processing dense computations, significantly speeding up the generation of the first token.
Decoding Stage
In the decoding stage, where tokens are generated sequentially, PowerInfer-2 utilizes small neuron clusters and CPU cores to handle the sparse computations. This method leverages the flexibility of CPU cores, which are well-suited for the lighter computational tasks associated with sparse activations.
Neuron Caching and Pipelining
PowerInfer-2 introduces a segmented cache that operates at the neuron granularity level. This cache is designed to enhance the cache hit rate and reduce the impact of I/O overhead on inference performance. By overlapping I/O operations with neuron cluster computations, the framework minimizes waiting times and maximizes throughput.
Offline Planner
Before running a new model on a smartphone, PowerInfer-2 executes an offline planning phase. This phase analyzes the model and hardware specifications to generate an execution plan that optimally configures computation, memory, and I/O resources. This plan ensures that inference is performed efficiently, even for models that do not fit entirely in memory.
Implementation and Evaluation
PowerInfer-2 has been implemented with an additional 12,000 lines of code on top of the original PowerInfer framework. The researchers deployed it on two smartphones: OnePlus 12 and Ace 2, equipped with Qualcomm XPUs and 24GB and 16GB of DRAM, respectively.
Supported Models
PowerInfer-2 supports a diverse array of LLMs, including:
Llama-2 (7B, 13B)
TurboSparse-Mistral (7B)
TurboSparse-Mixtral (47B)
Performance
The evaluation of PowerInfer-2 shows impressive results:
Speed: Up to 29.2× speed increase compared to state-of-the-art frameworks.
Memory Efficiency: Approximately 40% reduction in memory usage for smaller models while maintaining comparable inference speeds.
Notably, PowerInfer-2 is the first system to support the TurboSparse-Mixtral-47B model on mobile platforms, achieving a generation speed of 11.68 tokens per second.
Real-World Applications
To demonstrate its practical utility, PowerInfer-2 was tested on various real-world tasks such as multi-turn dialogue, code generation, math problem solving, and role play. The framework consistently delivered high performance across these diverse tasks, showcasing its robustness and versatility.
Conclusion
PowerInfer-2 represents a significant advancement in the deployment of LLMs on smartphones. By harnessing the heterogeneous resources of modern smartphones and optimizing computation, memory, and I/O operations, PowerInfer-2 enables high-speed, efficient inference for even the largest models. This innovation opens up new possibilities for privacy-preserving, intelligent personal assistants and other applications that require powerful language understanding and generation capabilities on mobile devices.
近年来,结构化状态空间序列模型(SSMs)作为一种很有潜力的序列建模架构,逐渐崭露头角。这些模型可以被看作是循环神经网络(RNNs)和卷积神经网络(CNNs)的结合,并受到了经典状态空间模型(Kalman 1960)的启发。SSMs可以高效地以循环或卷积的形式进行计算,其时间复杂度和空间复杂度都与序列长度呈线性或近线性关系。此外,它们还拥有建模某些数据模态中长程依赖关系的机制,并在Long Range Arena(Tay, Dehghani, Abnar, et al. 2021)等基准测试中取得了领先地位。
在语言建模方面,Mamba是第一个真正实现Transformer级性能的线性时间序列模型,无论是在预训练困惑度还是在零样本评估方面。在高达10亿个参数的规模下,Mamba的性能超越了各种基线,包括基于LLaMa(Touvron et al. 2023)的现代Transformer训练方案。Mamba语言模型的生成吞吐量是同等规模Transformer的5倍,Mamba-3B的质量与Transformer的两倍规模(例如,Pythia-7B)相当,甚至在常识推理方面超过了Pythia-7B。
Brown, Tom, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared Kaplan, Prafulla Dhariwal, Arvind Neelakantan, et al. “Language Models Are Few-Shot Learners.” arXiv preprint arXiv:2005.14165, 2020.
Vaswani, Ashish, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Łukasz Kaiser, and Illia Polosukhin. “Attention Is All You Need.” In Advances in Neural Information Processing Systems, 5998–6008, 2017.
Gu, Albert, Karan Goel, and Christopher Ré. “Efficiently Modeling Long Sequences with Structured State Spaces.” In International Conference on Learning Representations, 2022.
Dao, Tri, Daniel Y Fu, Andrew M Saab, et al. “H3: A Unified Architecture for Long Sequence Modeling.” In International Conference on Learning Representations, 2023.
Poli, Luca, Thomas Scialom, Guillaume Lample, et al. “Hyena: A Hybrid Convolutional Architecture for Long Sequence Modeling.” In International Conference on Learning Representations, 2023.
Q: 这篇论文试图解决什么问题?
A: 这篇论文试图解决的问题是深度学习中基础模型(Foundation Models, FMs)在处理长序列数据时的计算效率问题。基础模型通常基于Transformer架构,尽管它们在多种领域(如语言、图像、语音、音频、时间序列和基因组学)的应用中表现出色,但它们的计算复杂度随着序列长度的增加而呈二次方增长,这限制了它们在处理长序列数据时的应用。为了克服这一挑战,论文提出了一种新的序列建模方法,称为选择性状态空间模型(Selective State Space Models, SSMs),并将其集成到一个简化的神经网络架构中,称为Mamba。Mamba旨在实现线性时间复杂度的序列建模,同时保持或超越Transformer模型在多种模态(如语言、音频和基因组学)上的性能。
Q: 有哪些相关研究?
A: 这篇论文提到了多个与选择性状态空间模型(Selective State Space Models, SSMs)和Mamba架构相关的研究。以下是一些关键的相关研究:
结构化状态空间序列模型(Structured State Space Models, SSMs):这些模型是RNN和CNN的结合,能够高效地处理序列数据,具有线性或近线性的序列长度缩放特性。Gu, Goel, and Ré (2022) 和 Gu, Johnson, Goel, et al. (2021) 在这方面的工作为Mamba架构提供了理论基础。
RWKV(Reinventing RNNs for the Transformer Era):Peng等人在2023年提出了这种模型,它基于线性注意力近似,旨在为语言建模设计高效的RNN。
S5模型:Smith, Warrington, and Linderman在2023年提出了这种模型,它通过简化SSM架构来提高计算效率。
这些研究为Mamba架构的发展提供了理论基础和实践经验,特别是在处理长序列数据和提高计算效率方面。
Q: 论文如何解决这个问题?
A: 论文通过以下几个关键创新来解决长序列数据处理中的计算效率问题:
选择性状态空间模型(Selective State Space Models, SSMs):论文提出了一种新的SSM,它通过允许模型参数(如状态转移矩阵A、输入门B和输出门C)依赖于输入数据,从而实现对信息的选择性传播或遗忘。这种机制使得模型能够根据当前输入动态地调整其状态,有效地过滤掉不相关的信息。
A: 这篇论文介绍了一种名为Mamba的新型线性时间序列建模架构,旨在提高深度学习中基础模型(Foundation Models, FMs)在处理长序列数据时的计算效率。Mamba的核心是选择性状态空间模型(Selective State Space Models, SSMs),这些模型通过引入选择机制来改进传统的结构化状态空间模型(Structured State Space Models, SSMs),使其能够根据输入内容动态地选择性地处理信息。这种选择性允许模型在保持线性时间复杂度的同时,有效地处理长序列数据。
Chen, Yihan, et al. “Benchmarking Large Language Models on Controllable Generation under Diversified Instructions.” Proceedings of the AAAI Conference on Artificial Intelligence, vol. 38, no. 1, 2024, pp. 17808-17816.
Q: 这篇论文试图解决什么问题?
A: 这篇论文试图解决的问题是:大型语言模型(LLMs)在遵循自然语言指令方面表现出色,但目前尚不清楚它们是否能够以及在多大程度上能够响应指令中可能隐含的明确约束。为了更好地评估LLMs对具有特定约束的指令的响应,论文提出了一个新的基准测试(Benchmark),名为CoDI-Eval(Controllable Generation under Diversified Instructions),用于系统和全面地评估LLMs对具有各种约束的指令的响应。
Bang, Y., Cahyawijaya, S., Lee, N., Dai, W., Su, D., … & Fung, P. (2023). A Multitask, Multilingual, Multi-modal Evaluation of ChatGPT on Reasoning, Hallucination, and Interactivity. arXiv:2302.04023.
BELLEGroup. (2023). BELLE: Be Everyone’s Large Language model Engine. https://github.com/LianjiaTech/BELLE. Accessed: 2024-01-10.
Bian, N., Liu, P., Han, X., Lin, H., Lu, Y., He, B., & Sun, L. (2023). A Drop of Ink Makes a Million Think: The Spread of False Information in Large Language Models. arXiv:2305.04812.
Borgeaud, S., Mensch, A., Hoffmann, J., Cai, T., Rutherford, E., … & Sifre, L. (2022). Improving language models by retrieving from trillions of tokens. arXiv:2112.04426.
Cai, D., Wang, Y., Bi, W., Tu, Z., Liu, X., Lam, W., & Shi, S. (2019a). Skeleton-to-Response: Dialogue Generation Guided by Retrieval Memory. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), 1219–1228. Minneapolis, Minnesota: Association for Computational Linguistics.
Cai, D., Wang, Y., Bi, W., Tu, Z., Liu, X., & Shi, S. (2019b). Retrieval-guided Dialogue Response Generation via a Matching-to-Generation Framework. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), 1866–1875. Hong Kong, China: Association for Computational Linguistics.
Cao, M., Dong, Y., Wu, J., & Cheung, J. C. K. (2020). Factual Error Correction for Abstractive Summarization Models. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), 6251–6258. Online: Association for Computational Linguistics.
Chang, Y., Wang, X., Wang, J., Wu, Y., Yang, L., … & Xie, X. (2023). A Survey on Evaluation of Large Language Models. arXiv:2307.03109.
Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., … & Xing, E. P. (2023). Vicuna: An Open-Source Chatbot Impressing GPT-4 with 90%* ChatGPT Quality.
Cui, J., Li, Z., Yan, Y., Chen, B., & Yuan, L. (2023). ChatLaw: Open-Source Legal Large Language Model with Integrated External Knowledge Bases. arXiv:2306.16092.
Drozdov, A., Sch¨arli, N., Aky¨urek, E., Scales, N., Song, X., … & Zhou, D. (2023). Compositional Semantic Parsing with Large Language Models. In The Eleventh International Conference on Learning Representations.
Edward Beeching, N. H. S. H. N. L. N. R. O. S. L. T. T. W., Cl´ementine Fourrier. (2023). Open LLM Leaderboard. https://huggingface.co/spaces/HuggingFaceH4/open llm leaderboard. Accessed: 2024-01-10.
Guo, B., Zhang, X., Wang, Z., Jiang, M., Nie, J., … & Wu, Y. (2023). How Close is ChatGPT to Human Experts? Comparison Corpus, Evaluation, and Detection. arXiv:2301.07597.
Guu, K., Lee, K., Tung, Z., Pasupat, P., & Chang, M.-W. (2020). REALM: Retrieval-Augmented Language Model Pre-Training. In Proceedings of the 37th International Conference on Machine Learning, ICML’20. JMLR.org.
He, H., Zhang, H., & Roth, D. (2022). Rethinking with Retrieval: Faithful Large Language Model Inference. arXiv:2301.00303.
Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., … & Steinhardt, J. (2021). Measuring Massive Multitask Language Understanding. In International Conference on Learning Representations.
Huang, Y., Bai, Y., Zhu, Z., Zhang, J., Zhang, J., … & He, J. (2023). C-Eval: A Multi-Level Multi-Discipline Chinese Evaluation Suite for Foundation Models. arXiv preprint arXiv:2305.08322.
Izacard, G., & Grave, E. (2021). Leveraging Passage Retrieval with Generative Models for Open Domain Question Answering. In Proceedings of the 16th Conference of the European Chapter of the Association for Computational Linguistics: Main Volume, 874–880. Online: Association for Computational Linguistics.
Izacard, G., Lewis, P., Lomeli, M., Hosseini, L., Petroni, F., … & Grave, E. (2022). Atlas: Few-shot Learning with Retrieval Augmented Language Models. arXiv:2208.03299.
Ji, Z., Lee, N., Frieske, R., Yu, T., Su, D., … & Fung, P. (2023). Survey of Hallucination in Natural Language Generation. ACM Comput. Surv., 55(12).
Lewis, P., Perez, E., Piktus, A., Petroni, F., Karpukhin, V., … & Kiela, D. (2020). Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks. In Proceedings of the 34th International Conference on Neural Information Processing Systems, NIPS’20. Red Hook, NY, USA: Curran Associates Inc. ISBN 9781713829546.
Li, D., Rawat, A. S., Zaheer, M., Wang, X., Lukasik, M., … & Kumar, S. (2023a). Large Language Models with Controllable Working Memory. In Findings of the Association for Computational Linguistics: ACL 2023, 1774–1793. Toronto, Canada: Association for Computational Linguistics.
Li, X., Zhang, T., Dubois, Y., Taori, R., Gulrajani, I., … & Hashimoto, T. B. (2023b). AlpacaEval: An Automatic Evaluator of Instruction-following Models. https://github.com/tatsu-lab/alpaca eval. Accessed: 2024-01-10.
Li, X., Zhu, X., Ma, Z., Liu, X., & Shah, S. (2023c). Are ChatGPT and GPT-4 General-Purpose Solvers for Financial Text Analytics? An Examination on Several Typical Tasks. arXiv:2305.05862.
Liu, N. F., Zhang, T., & Liang, P. (2023). Evaluating Verifiability in Generative Search Engines. arXiv:2304.09848.
Maynez, J., Narayan, S., Bohnet, B., & McDonald, R. (2020). On Faithfulness and Factuality in Abstractive Summarization. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, 1906–1919. Online: Association for Computational Linguistics.
OpenAI. (2022). Chatgpt: Optimizing language models for dialogue. https://openai.com/blog/chatgpt. Accessed: 2024-01-10.
Peng, B., Galley, M., He, P., Cheng, H., Xie, Y., … & Gao, J. (2023). Check Your Facts and Try Again: Improving Large Language Models with External Knowledge and Automated Feedback. arXiv:2302.12813.
Qin, Y., Liang, S., Ye, Y., Zhu, K., Yan, L., … & Sun, M. (2023). ToolLLM: Facilitating Large Language Models to Master 16000+ Real-world APIs. arXiv:2307.16789.
Raunak, V., Menezes, A., & Junczys-Dowmunt, M. (2021). The Curious Case of Hallucinations in Neural Machine Translation. In Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, 1172–1183. Online: Association for Computational Linguistics.
Ren, R., Wang, Y., Qu, Y., Zhao, W. X., Liu, J., … & Wang, H. (2023). Investigating the Factual Knowledge Boundary of Large Language Models with Retrieval Augmentation. arXiv:2307.11019.
Q: 这篇论文试图解决什么问题?
A: 这篇论文探讨了如何通过检索增强生成(Retrieval-Augmented Generation, RAG)来减轻大型语言模型(Large Language Models, LLMs)的幻觉问题。幻觉问题指的是语言模型可能会生成与给定上下文无关或事实错误的信息。尽管RAG被认为是解决这一挑战的有前途的方法,但现有研究缺乏对RAG对不同LLMs影响的严格评估,这使得难以确定RAG在不同LLMs中的潜在瓶颈。
检索增强模型(Retrieval-Augmented Models):这类研究探讨了如何通过检索外部知识来提高语言模型的生成准确性和可靠性。相关研究包括Guu et al. (2020), Lewis et al. (2020), Borgeaud et al. (2022), Izacard et al. (2022) 等。
大型语言模型(Large Language Models, LLMs)的评估:这些研究关注于如何全面评估LLMs的能力,包括GLUE (Wang et al. 2019b), SuperCLUE (Wang et al. 2019a), MMLU (Hendrycks et al. 2021), AGIEval (Zhong et al. 2023), C-Eval (Huang et al. 2023), AlpacaEval (Li et al. 2023b), OpenLLM Leaderboard (Edward Beeching 2023) 等。
处理噪声和错误信息:研究了LLMs在面对噪声信息和错误信息时的鲁棒性,例如Cao et al. (2020), Raunak, Menezes, and Junczys-Dowmunt (2021), Ji et al. (2023) 等。
知识更新和领域特定专业知识:探讨了LLMs在知识更新和缺乏领域特定专业知识方面的挑战,如He, Zhang, and Roth (2022), Li et al. (2023c), Shen et al. (2023) 等。
检索增强生成的评估:研究了如何在现有的问答数据集上评估LLMs的RAG能力,例如Adlakha et al. (2023)。
安全性和责任:评估了LLMs在安全性和责任方面的表现,如CValues (Xu et al. 2023a)。
人类考试和工具使用:研究了LLMs在模拟人类考试和工具使用方面的能力,如M3Exam (Zhang et al. 2023), ToolBench (Qin et al. 2023)。
[1] Huang, Chieh-Yang, Jing Wei, and Ting-Hao Kenneth Huang. “Generating Educational Materials with Different Levels of Readability using LLMs.” In2Writing 2024, May 11, 2024, Honolulu, Hawii.
[2] MetaMetrics. 2022. Lexile Framework for Reading Development and Validity Evidence. https://hubsupport.lexile.com/Images/Lexile%20Framework%20for%2020Reading%20Validity%20Evidence_2022.pdf
 在决策时使用了包含敏感属性
在决策时使用了包含敏感属性 和其他属性
和其他属性 的数据集进行训练。公平性可表示为:
的数据集进行训练。公平性可表示为:![\[F(X, Y, h, S, Z) = h(X, S, Z) ≈ h(X, S', Z)\]](https://www.zhichai.top/wp-content/ql-cache/quicklatex.com-26af0be02e72b8407ef5d74c84d19537_l3.png "Rendered by QuickLaTeX.com")
 代表一组属性(或特征),
代表一组属性(或特征), 代表一组受保护的属性。个体公平性定义为:
代表一组受保护的属性。个体公平性定义为:![\[f(x_i) = f(x_{i'})\]](https://www.zhichai.top/wp-content/ql-cache/quicklatex.com-58d5e5af727a0dbddbba1748163db95d_l3.png "Rendered by QuickLaTeX.com")
 为ML分类器,
为ML分类器, 和
和 代表具有相似非保护属性但可能具有不同保护属性的两个个体。
代表具有相似非保护属性但可能具有不同保护属性的两个个体。![\[c = \arg\min \text{loss}(f(c), y) + |x - c|\]](https://www.zhichai.top/wp-content/ql-cache/quicklatex.com-d1bfbe6496d82827606a07e7a80e824e_l3.png "Rendered by QuickLaTeX.com")
 为输入特征,
为输入特征, 为模型的输出,
为模型的输出, 为导致不同输出的反事实实例。
为导致不同输出的反事实实例。 ,这些实例具有不同的保护属性组合。
,这些实例具有不同的保护属性组合。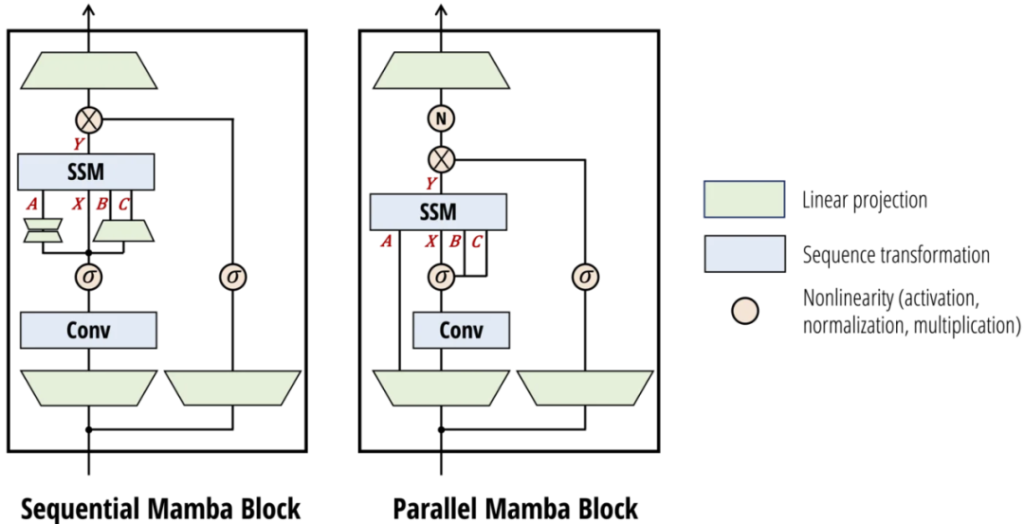
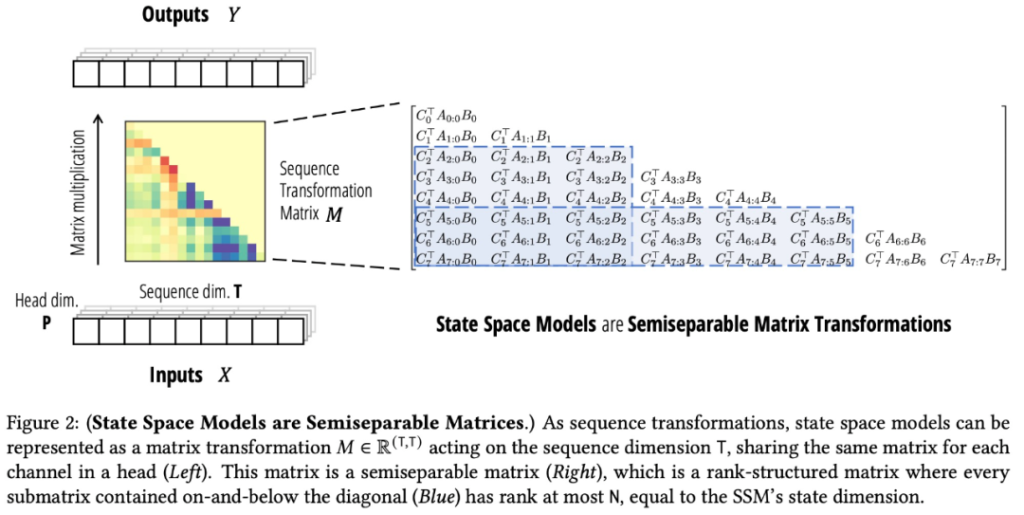
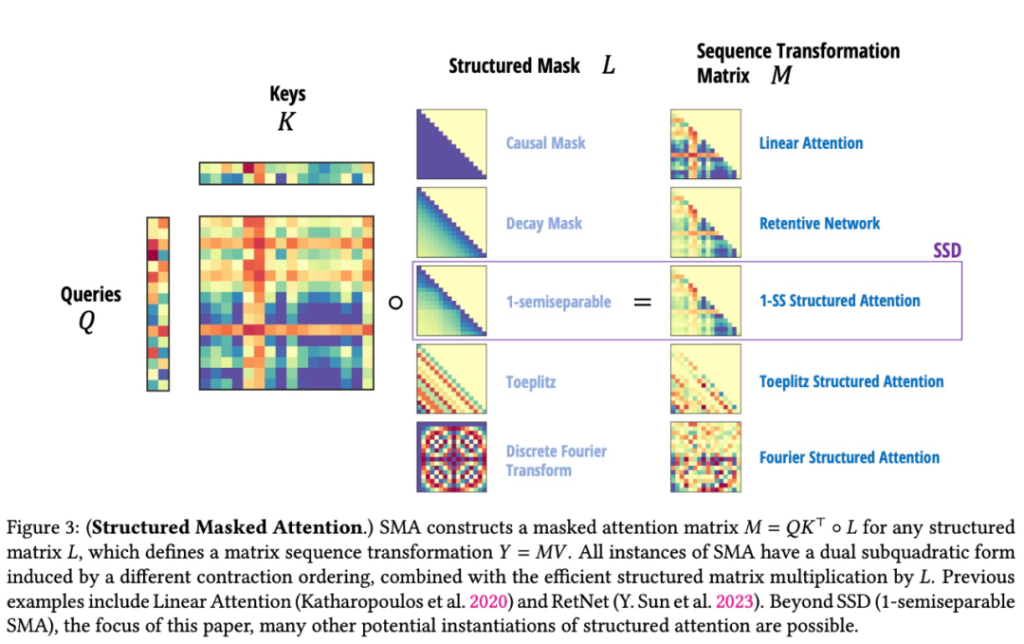

![\[\frac{dh}{dt} = Ah + Bu\]](https://www.zhichai.top/wp-content/ql-cache/quicklatex.com-806b12590257b8e7ac0ca48d4b99b5bd_l3.png "Rendered by QuickLaTeX.com")
 代表输入,
代表输入, 和
和  是模型参数。
是模型参数。![\[\frac{dh}{dt} = h\]](https://www.zhichai.top/wp-content/ql-cache/quicklatex.com-19a67664e6920477c1c58edad3e25782_l3.png "Rendered by QuickLaTeX.com")
 。这意味着,只要时间足够长,该线性系统就可以通过指数函数来拟合足够复杂的函数。
。这意味着,只要时间足够长,该线性系统就可以通过指数函数来拟合足够复杂的函数。 的信息。如果我们假设
的信息。如果我们假设  阶可导,那么它对应的
阶可导,那么它对应的 ![\[c_k = \int_{-\infty}^{\infty} x(t)e^{-2\pi ikt} dt\]](https://www.zhichai.top/wp-content/ql-cache/quicklatex.com-c020321cccab79b8359b1bf5255d7e69_l3.png "Rendered by QuickLaTeX.com")
![[0, T]](https://www.zhichai.top/wp-content/ql-cache/quicklatex.com-fc9721e54b00c25e101ee259b292023d_l3.png "Rendered by QuickLaTeX.com") ,然后计算其在该区间上的傅里叶系数。
,然后计算其在该区间上的傅里叶系数。![\[c_k(T) = \int_{0}^{T} x(t)e^{-2\pi ikt} dt\]](https://www.zhichai.top/wp-content/ql-cache/quicklatex.com-cb52cd04d7e68d476f31440b90631ea1_l3.png "Rendered by QuickLaTeX.com")
 是关于
是关于  次函数,定义域为
次函数,定义域为 ![[-1, 1]](https://www.zhichai.top/wp-content/ql-cache/quicklatex.com-61888feeeeb8e122a17b229740cd3b65_l3.png "Rendered by QuickLaTeX.com") ,满足:
,满足:![\[\int_{-1}^{1} P_m(x)P_n(x) dx = \frac{2}{2n + 1}\delta_{mn}\]](https://www.zhichai.top/wp-content/ql-cache/quicklatex.com-b89ce36a9422a8b4f91a4d2bde4fa7ee_l3.png "Rendered by QuickLaTeX.com")
![\[\frac{d}{dT}P_n(2T/T - 1) = \frac{2n}{T}P_{n-1}(2T/T - 1)\]](https://www.zhichai.top/wp-content/ql-cache/quicklatex.com-cecb7eb2921c7fa1d269028e288e5362_l3.png "Rendered by QuickLaTeX.com")