1. 引言
在现代人工智能领域,多头自注意力机制(Multi-Headed Self Attention, MHSA)可以说是最重要的架构范式之一。它是Transformer模型的核心组件,而Transformer又是当前最先进的大型语言模型的基础架构。本文将深入浅出地解析多头自注意力机制的工作原理,通过手动计算的方式,让读者对其内部运作有一个直观而全面的理解。
2. 多头自注意力机制的背景
在深入MHSA之前,我们先简要回顾一下自然语言处理(NLP)领域的相关发展历程。早期的NLP模型主要依赖于循环神经网络(RNN)和长短期记忆网络(LSTM)等序列模型。这些模型虽然能够处理序列数据,但在处理长序列时存在长期依赖问题。
2017年,Google提出了Transformer模型,其核心就是多头自注意力机制。MHSA能够并行处理输入序列,捕捉序列中的长距离依赖关系,大大提高了模型的性能和效率。自此,MHSA成为了NLP领域的主流技术,被广泛应用于各种大型语言模型中。
3. 多头自注意力机制的工作原理
让我们通过一个具体的例子,step by step地计算多头自注意力机制的输出。我们将遵循以下步骤:
- 定义输入
- 定义可学习参数
- 计算查询(Query)、键(Key)和值(Value)
- 划分多个注意力头
- 计算Z矩阵
- 掩码操作
- 计算注意力矩阵
- 计算注意力头的输出
- 拼接多个注意力头的输出
3.1 定义输入
MHSA可以应用于各种类型的数据,但通常情况下,输入是一个向量序列。在自然语言处理中,这通常是词嵌入(word embedding)与位置编码(positional encoding)的组合。
假设我们有一个简单的输入序列,包含3个词,每个词用4维向量表示:
Input = [
[1, 2, 3, 4],
[5, 6, 7, 8],
[9, 10, 11, 12]
]
这个4×3的矩阵代表了我们的输入序列。
3.2 定义可学习参数
MHSA主要学习三个权重矩阵,用于构造”查询”(Query)、”键”(Key)和”值”(Value)。在本例中,我们假设模型已经学习到了以下权重矩阵:
W_Q = [
[0.1, 0.2],
[0.3, 0.4],
[0.5, 0.6],
[0.7, 0.8]
]
W_K = [
[0.1, 0.2],
[0.3, 0.4],
[0.5, 0.6],
[0.7, 0.8]
]
W_V = [
[0.1, 0.2],
[0.3, 0.4],
[0.5, 0.6],
[0.7, 0.8]
]
这些4×2的矩阵代表了模型的可学习参数。
3.3 计算查询、键和值
接下来,我们将输入与权重矩阵相乘,得到查询、键和值:
Query = Input * W_Q
Key = Input * W_K
Value = Input * W_V
让我们计算Query:
Query = [
[1*0.1 + 2*0.3 + 3*0.5 + 4*0.7, 1*0.2 + 2*0.4 + 3*0.6 + 4*0.8],
[5*0.1 + 6*0.3 + 7*0.5 + 8*0.7, 5*0.2 + 6*0.4 + 7*0.6 + 8*0.8],
[9*0.1 + 10*0.3 + 11*0.5 + 12*0.7, 9*0.2 + 10*0.4 + 11*0.6 + 12*0.8]
]
Query = [
[5.0, 6.0],
[13.0, 15.0],
[21.0, 24.0]
]
同理可得Key和Value:
Key = [
[5.0, 6.0],
[13.0, 15.0],
[21.0, 24.0]
]
Value = [
[5.0, 6.0],
[13.0, 15.0],
[21.0, 24.0]
]
3.4 划分多个注意力头
多头自注意力机制的”多头”体现在这一步。我们将Query、Key和Value划分为多个子矩阵,每个子矩阵对应一个注意力头。在本例中,我们使用两个注意力头:
Query_1 = [
[5.0],
[13.0],
[21.0]
]
Query_2 = [
[6.0],
[15.0],
[24.0]
]
Key_1 = [
[5.0],
[13.0],
[21.0]
]
Key_2 = [
[6.0],
[15.0],
[24.0]
]
Value_1 = [
[5.0],
[13.0],
[21.0]
]
Value_2 = [
[6.0],
[15.0],
[24.0]
]
这样,我们就得到了两组Query、Key和Value,分别用于两个注意力头的计算。
3.5 计算Z矩阵
接下来,我们需要计算Z矩阵,这是构造注意力矩阵的中间步骤。Z矩阵由Query和Key的矩阵乘法得到。我们以第一个注意力头为例:
Z_1 = Query_1 * Key_1^T
Z_1 = [
[5.0], [5.0, 13.0, 21.0]
[13.0], *
[21.0]
]
Z_1 = [
[5.0*5.0, 5.0*13.0, 5.0*21.0],
[13.0*5.0, 13.0*13.0, 13.0*21.0],
[21.0*5.0, 21.0*13.0, 21.0*21.0]
]
Z_1 = [
[25, 65, 105],
[65, 169, 273],
[105, 273, 441]
]
为了防止Z矩阵的值随着序列长度的增加而过大,我们通常会将Z矩阵除以序列长度的平方根。在本例中,序列长度为3,所以我们将Z_1除以 :
:
Z_1 = [
[14.43, 37.53, 60.62],
[37.53, 97.58, 157.62],
[60.62, 157.62, 254.62]
]
同理可得Z_2。
3.6 掩码操作
在某些应用场景中,如语言模型预测下一个词时,我们需要进行掩码操作,以确保模型在预测时不会”看到”未来的信息。这通常通过将Z矩阵中的某些位置设置为负无穷来实现。在本例中,我们假设不需要掩码操作。
3.7 计算注意力矩阵
注意力矩阵是通过对Z矩阵的每一行进行softmax运算得到的。softmax函数的定义如下:

让我们以Z_1的第一行为例计算softmax:
row = [14.43, 37.53, 60.62]
e_row = [1,850,752, 20,215,372,293, 1,800,537,936,918]
sum_e_row = 1,822,604,060,963
softmax(row) = [
1,850,752 / 1,822,604,060,963,
20,215,372,293 / 1,822,604,060,963,
1,800,537,936,918 / 1,822,604,060,963
]
softmax(row) ≈ [0.001, 0.011, 0.988]
对Z_1的每一行都进行这样的计算,我们就得到了注意力矩阵Attention_1:
Attention_1 ≈ [
[0.001, 0.011, 0.988],
[0.000, 0.000, 1.000],
[0.000, 0.000, 1.000]
]
同理可得Attention_2。
3.8 计算注意力头的输出
得到注意力矩阵后,我们将其与Value相乘,得到每个注意力头的输出:
Output_1 = Attention_1 * Value_1
Output_1 ≈ [
[0.001*5.0 + 0.011*13.0 + 0.988*21.0],
[0.000*5.0 + 0.000*13.0 + 1.000*21.0],
[0.000*5.0 + 0.000*13.0 + 1.000*21.0]
]
Output_1 ≈ [
[20.86],
[21.00],
[21.00]
]
同理可得Output_2。
3.9 拼接多个注意力头的输出
最后,我们将所有注意力头的输出拼接起来,得到多头自注意力机制的最终输出:
Final_Output = [Output_1 | Output_2]
Final_Output ≈ [
[20.86, 24.00],
[21.00, 24.00],
[21.00, 24.00]
]
这个3×2的矩阵就是多头自注意力机制的输出结果。
4. 多头自注意力机制的优势
通过上述计算过程,我们可以看出多头自注意力机制具有以下优势:
- 并行计算: MHSA可以并行处理输入序列中的所有元素,大大提高了计算效率。
- 捕捉多种关系: 通过使用多个注意力头,模型可以同时关注输入序列中的不同特征和关系。
- 长距离依赖: MHSA可以有效捕捉序列中的长距离依赖关系,克服了RNN等传统模型的局限性。
- 灵活性: MHSA可以应用于各种类型的序列数据,不仅限于自然语言处理。
- 可解释性: 注意力权重可以提供模型决策过程的一定解释性,有助于理解模型的工作原理。
5. 多头自注意力机制的应用
MHSA在自然语言处理领域有广泛的应用,包括但不限于:
- 机器翻译: Transformer模型在机器翻译任务中取得了突破性的成果。
- 文本生成: GPT系列模型使用了基于MHSA的架构,能够生成高质量的文本。
- 问答系统: BERT等模型在问答任务中表现出色,为智能问答系统提供了强大的支持。
- 文本分类: MHSA可以有效捕捉文本的语义特征,提高分类准确率。
- 语音识别: 在语音识别任务中,MHSA也展现出了优秀的性能。
- 图像处理: 虽然最初设计用于NLP任务,但MHSA也被成功应用于计算机视觉领域。
6. 结论
多头自注意力机制是现代人工智能,特别是自然语言处理领域的核心技术之一。通过本文的详细计算过程,我们深入了解了MHSA的工作原理。尽管实际应用中的计算规模要大得多,但基本原理是相同的。
理解MHSA的工作原理对于深入学习和应用先进的AI技术至关重要。随着技术的不断发展,我们可以期待MHSA在更多领域发挥重要作用,推动人工智能技术的进步。
参考文献
- Warfield, D. (2024). Multi-Headed Self Attention — By Hand. Intuitively and Exhaustively Explained. https://iaee.substack.com/p/multi-headed-self-attention-by-hand
- Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones, L., Gomez, A. N., … & Polosukhin, I. (2017). Attention is all you need. Advances in neural information processing systems, 30.


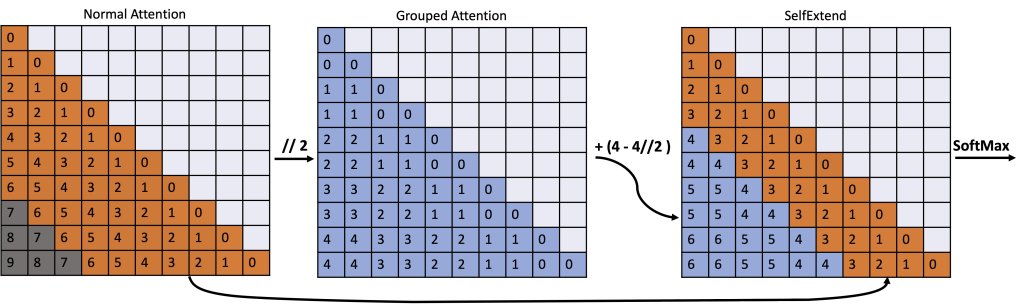
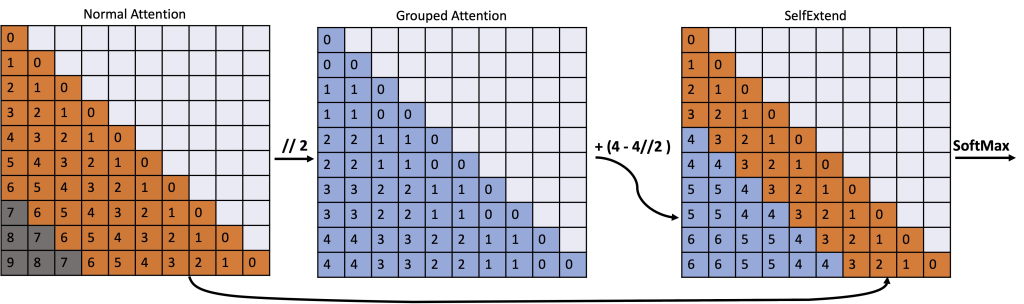
 ,目标扩展长度表示为
,目标扩展长度表示为  ,邻居窗口表示为
,邻居窗口表示为  ,组大小表示为
,组大小表示为  ,选择超参数的经验法则是确保以下不等式成立:
,选择超参数的经验法则是确保以下不等式成立:  这是经验性的,作者认为这是因为:较大的相对位置没有得到很好的训练。根据经验,只有一部分(
这是经验性的,作者认为这是因为:较大的相对位置没有得到很好的训练。根据经验,只有一部分( )的位置得到了很好的训练,Self-Extend 应该只利用这些训练有素的相对位置进行扩展。这一发现解释了:
)的位置得到了很好的训练,Self-Extend 应该只利用这些训练有素的相对位置进行扩展。这一发现解释了: ,其中
,其中  是状态空间,
是状态空间, 是动作空间,
是动作空间, 是初始状态分布,
是初始状态分布, 是转移概率,
是转移概率, 是奖励函数,
是奖励函数, 是时间跨度。
是时间跨度。 ,变分推理问题可以表示为:
,变分推理问题可以表示为:![\[\max_{q({\bm{x}},{\bm{a}})}\langle\log f({\bm{x}},{\bm{a}})\rangle_{q({\bm{x}},{\bm{a}})} + H^{\text{type}}_{q}({\bm{x}},{\bm{a}})\]](https://www.zhichai.top/wp-content/ql-cache/quicklatex.com-8b7970678c73f7b8143001ab88846f2a_l3.png "Rendered by QuickLaTeX.com")
 是关于变量的任意变分分布,
是关于变量的任意变分分布, 是特定类型的熵。
是特定类型的熵。![\[F_{\lambda}^{\text{planning}} = \frac{1}{\lambda}\log\max_{\bm{\pi}}\mathbb{E}_{\bm{\pi}}\left[\exp(\lambda R({\bm{x}},{\bm{a}}))\right]\]](https://www.zhichai.top/wp-content/ql-cache/quicklatex.com-b10ac998bae1eb0428be785feec1bb75_l3.png "Rendered by QuickLaTeX.com")
 是风险参数。
是风险参数。 ,它们的质量排序如下:
,它们的质量排序如下:![\[F_{\lambda}^{\text{marginal}^{\text{U}}} \leq F_{\lambda}^{\text{MAP}} \leq F_{\lambda}^{\text{MMAP}} \leq F_{\lambda}^{\textbf{planning}} \leq F_{\lambda}^{\text{marginal}}\]](https://www.zhichai.top/wp-content/ql-cache/quicklatex.com-1dff26aada0b00736ee15474ba30df04_l3.png "Rendered by QuickLaTeX.com")