在人工智能的世界里,每一天都可能发生惊天动地的变化。就在昨天,我们还在为某个模型的强大性能惊叹不已,今天,一个新的”王者”就已经闪亮登场了。各位看官,请允许我隆重介绍:来自HyperWrite公司的Reflection 70B模型!
🎭 初次亮相:一鸣惊人的新秀
🌟 惊艳登场:从默默无闻到惊艳四座
想象一下,在一个热闹非凡的AI模型选美大赛上,突然有一位神秘选手踏着闪耀的星光登场。这位选手就是HyperWrite公司的联合创始人兼CEO Matt Shumer刚刚推出的Reflection 70B模型。
就像童话故事里的灰姑娘突然变身为迷人的公主,Reflection 70B的出现立刻引起了全场的注目。Matt Shumer在社交网络X(原Twitter)上自豪地宣布:”我很高兴向大家介绍Reflection 70B,这是目前世界上最顶尖的开源AI模型。”
这番豪言壮语可不是空口白话。Reflection 70B在多项第三方基准测试中的表现都相当出色,甚至超越了许多知名的商业模型。这就好比一个默默无闻的小将在奥运会上一举夺魁,让所有人都大吃一惊。
🧠 与众不同:Reflection 70B的独特之处
🔍 自我反思:AI界的”三省吾身”
Reflection 70B最与众不同的地方在于它的”自我反思”能力。想象一下,如果你有一个助手,他不仅能帮你完成各种任务,还能主动发现并纠正自己的错误,那该有多棒?这正是Reflection 70B的独特之处。
Matt Shumer解释道:”我一直在思考这个问题:大语言模型会产生幻觉,但它们无法自我纠正。如果我们教会一个大语言模型如何识别并修复自己的错误会怎样呢?”
这就好比我们在学习过程中,不仅要学会解题,还要学会检查自己的答案,发现并改正错误。Reflection 70B就像一个聪明的学生,在给出答案之前,会先仔细检查自己的推理过程,确保不会出错。
🔬 技术解密:Reflection 70B的秘密武器
🧪 反思调优:AI的”三思而后行”
Reflection 70B的核心秘密就在于一种名为”反思调优”(Reflection-Tuning)的技术。这项技术让模型能够在给出最终答案之前,先检查自己的推理过程,发现并纠正可能存在的错误。
想象一下,如果你在解一道复杂的数学题,你会怎么做?你可能会先列出解题步骤,然后逐步计算,最后再检查一遍确保没有错误。Reflection 70B就是用类似的方法来提高自己的准确性。
Reflection 70B引入了几个新的特殊标记,用于推理和错误纠正。这就像是给模型配备了一个内置的”检查员”,随时监督它的输出,一旦发现问题就立即纠正。这种方法使得Reflection 70B在需要高度准确性的任务中表现特别出色。
🚀 未来展望:更强大的模型即将到来
🔮 Reflection 405B:AI界的”大魔王”?
如果说Reflection 70B是AI界的新王者,那么即将推出的Reflection 405B可能就是真正的”大魔王”了。Matt Shumer透露,这个更大规模的模型将在下周发布,而且有望超越市场上所有的闭源模型。
这就好比在一场激烈的赛车比赛中,Reflection 70B刚刚夺得了冠军,而更强大的Reflection 405B已经在赛道上热身,准备创造新的世界纪录。
💡 幕后英雄:Glaive的快速AI模型训练
🦸♂️ Glaive:AI训练的”神助攻”
在Reflection 70B的成功背后,有一个重要的幕后功臣——Glaive。这家由荷兰工程师Sahil Chaudhary创立的初创公司专注于创建特定用途的数据集。
想象一下,如果你要训练一个AI来识别不同品种的狗,你需要大量的狗狗照片。Glaive就像是一个神奇的照相机,能快速生成你需要的各种狗狗照片,让你的AI训练事半功倍。
Matt Shumer对Glaive赞不绝口:”Glaive是这次成功的关键原因。他们在生成合成数据方面的控制力简直是疯狂的。”有了Glaive的帮助,Reflection团队能够在短短几小时内生成高质量的合成数据,大大加快了模型的训练速度。
🏆 结语:开源AI的新纪元
Reflection 70B的横空出世,无疑为开源AI领域注入了一剂强心针。它向世人展示了开源模型也能够与顶级商业模型一较高下,甚至在某些方面更胜一筹。
就像一个默默无闻的小镇突然培养出了一位世界级的运动员,HyperWrite这家来自纽约长岛的小公司,用Reflection 70B向全世界证明了自己的实力。
随着Reflection 405B的即将到来,我们或许正站在AI技术革命的风口浪尖。谁知道呢,也许在不久的将来,我们每个人的电脑里都会有一个像Reflection这样强大而又谦逊的AI助手,帮助我们更好地工作和生活。
让我们一起期待AI的美好未来吧!
参考文献:
- Franzen, C. (2024). Meet the new, most powerful open source AI model in the world: HyperWrite’s Reflection 70B. VentureBeat.
- Shumer, M. (2024). Announcement of Reflection 70B on social network X.
- Forbes. (2023). 30 Under 30 List featuring Matt Shumer and Jason Kuperberg.
- VentureBeat. (2023). HyperWrite’s funding disclosure in March 2023.
- Chaudhary, S. Glaive AI platform information.
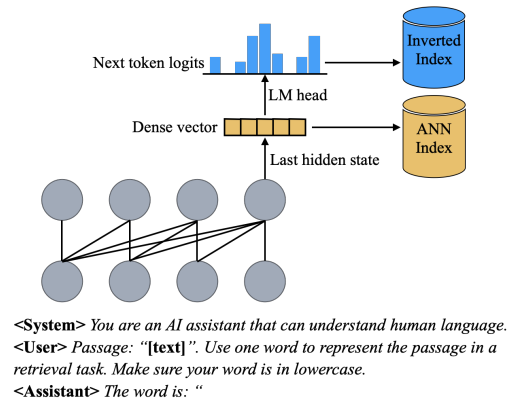

 是第
是第  条推理路径的可信度得分,
条推理路径的可信度得分, 是答案的长度,
是答案的长度, 和
和  分别是每一步解码中概率最高和第二高的词的概率。
分别是每一步解码中概率最高和第二高的词的概率。 repo_path
%cd $repo_path
!pip install -e .
if "pyserini" not in {pkg.key for pkg in pkg_resources.working_set}:
!pip install pyserini
if "torch" not in {pkg.key for pkg in pkg_resources.working_set}:
!pip install torch
if "faiss-cpu" not in {pkg.key for pkg in pkg_resources.working_set}:
!pip install faiss-cpu
except:
repo_path = '.'
if "dspy-ai" not in {pkg.key for pkg in pkg_resources.working_set}:
!pip install -U pip
!pip install dspy-ai
if repo_path not in sys.path:
sys.path.append(repo_path)
import dspy
repo_path
%cd $repo_path
!pip install -e .
if "pyserini" not in {pkg.key for pkg in pkg_resources.working_set}:
!pip install pyserini
if "torch" not in {pkg.key for pkg in pkg_resources.working_set}:
!pip install torch
if "faiss-cpu" not in {pkg.key for pkg in pkg_resources.working_set}:
!pip install faiss-cpu
except:
repo_path = '.'
if "dspy-ai" not in {pkg.key for pkg in pkg_resources.working_set}:
!pip install -U pip
!pip install dspy-ai
if repo_path not in sys.path:
sys.path.append(repo_path)
import dspy
 ,其中
,其中  表示节点集合,
表示节点集合, 表示边集合。为了确保图谱的唯一性和一致性,我们设定了两个约束条件:每个实体和关系都必须描述一个语义上独特的概念,并且集合中的每个元素都不应重复。
表示边集合。为了确保图谱的唯一性和一致性,我们设定了两个约束条件:每个实体和关系都必须描述一个语义上独特的概念,并且集合中的每个元素都不应重复。
![\[Score(query, C_i) = \sum_{q_j \in query} IDF(q_j) \cdot \frac{f(q_j, C_i) \cdot (k_1 + 1)}{f(q_j, C_i) + k_1 \cdot (1 - b + b \cdot \frac{|C_i|}{avg_dl})}\]](https://www.zhichai.top/wp-content/ql-cache/quicklatex.com-0532efc4728bc4eece1b0eb5cc3e1620_l3.png "Rendered by QuickLaTeX.com")
 代表了词项
代表了词项 的逆文档频率,反映了该词的重要性;
的逆文档频率,反映了该词的重要性; 则表示词项
则表示词项 中的出现频率。参数
中的出现频率。参数 和
和 分别用于调整词频的饱和度和文档长度的归一化。这些术语并不是简单的数学符号,而是构建BM25在信息检索中高效性的基石。
分别用于调整词频的饱和度和文档长度的归一化。这些术语并不是简单的数学符号,而是构建BM25在信息检索中高效性的基石。