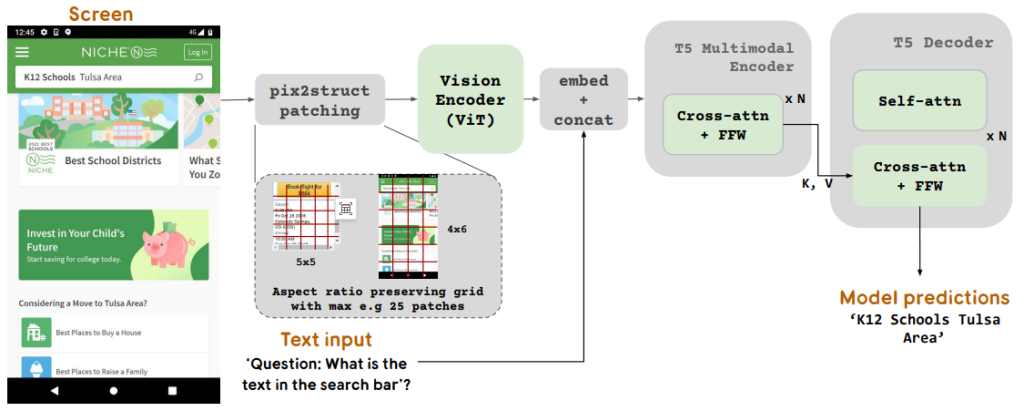
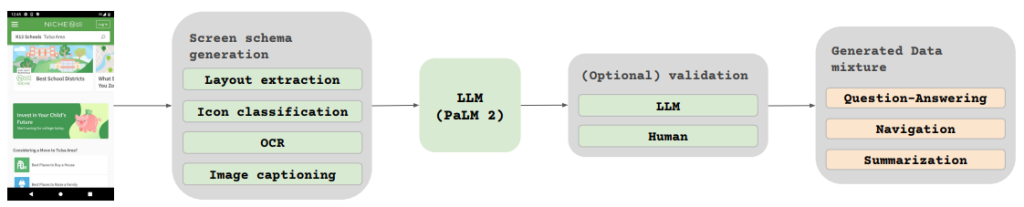
在现代Web开发中,数据库的管理和操作是构建高效应用的基石。Reflex框架以其优雅的设计,提供了一个强大的数据库接口,让开发者能够轻松地连接、管理和操作数据。本文将深入探讨Reflex的数据库特性,包括连接、表、迁移和查询等核心功能。
🌐 连接:轻松接入数据库
Reflex框架内置了SQLite数据库,开发者可以方便地存储和检索数据。如果你希望连接到其他SQL兼容的数据库,只需修改 rxconfig.py 文件,配置你的数据库URL。例如,以下是如何连接到一个SQLite数据库的代码示例:
config = rx.Config(
app_name="my_app",
db_url="sqlite:///reflex.db",
)在使用不同的数据库时,确保安装适当的DBAPI驱动程序,以便Reflex能够与目标数据库顺畅交互。此外,开发者也可以使用NoSQL数据库(如MongoDB),只需安装相应的Python客户端库。需要注意的是,在这种情况下,Reflex将不提供ORM特性。
📚 表:构建数据模型
在Reflex中,创建一个数据表的过程非常简单。只需定义一个继承自 rx.Model 的类,并指定它作为一个表。例如,以下代码定义了一个用户表:
class User(rx.Model, table=True):
username: str
email: str
password: str通过这种方式,开发者可以快速构建出符合需求的数据模型,进一步提高开发效率。
🔄 迁移:轻松管理数据库模式变更
在应用开发过程中,数据库模式的变更是不可避免的。Reflex利用Alembic工具来管理这些变更。在新应用中使用数据库功能之前,必须调用 reflex db init 命令来初始化Alembic,并创建一个迁移脚本以反映当前模式。
当需要对数据库模式进行更改时,开发者可以使用以下命令生成迁移脚本:
reflex db makemigrations --message 'something changed'生成的脚本将存放在 alembic/versions 目录下,建议在应用这些脚本之前先进行检查。应用迁移脚本的命令为 reflex db migrate,这样就能将数据库更新到最新状态。每当应用启动时,Reflex会检测当前数据库模式是否最新,并在控制台中显示警告信息。
🔍 查询:强大的数据检索能力
查询数据库是Reflex框架中一个重要的功能。开发者可以创建一个 rx.session() 来处理数据库连接的开启和关闭。使用普通的SQLAlchemy查询语法,就能够方便地进行数据操作。例如,以下代码展示了如何向用户表中添加一条新记录:
with rx.session() as session:
session.add(
User(
username="test",
email="admin@reflex.dev",
password="admin",
)
)
session.commit()这种简洁的查询方式让开发者能够高效地操作数据库,极大地提升了开发体验。
📦 结论:Reflex数据库的优势
通过以上的探讨,我们可以看到Reflex框架为开发者提供了一整套完备的数据库管理解决方案。从简单的连接到复杂的查询,Reflex都能轻松应对。无论是初学者还是经验丰富的开发者,都能在这个框架中找到适合自己需求的工具。
在快速发展的技术环境中,掌握Reflex的数据库功能,将为构建高效、灵活的Web应用打下坚实的基础。未来,随着Reflex的不断进化,我们可以期待更多强大而便捷的数据库特性加入进来,助力开发者在数字世界中畅行无阻。
📝 参考文献
- Reflex Documentation – Database Overview. Retrieved from Reflex.dev
- SQLAlchemy Documentation. Retrieved from SQLAlchemy
- Alembic Documentation. Retrieved from Alembic
- Reflex API Reference. Retrieved from Reflex.dev
- Reflex Components Overview. Retrieved from Reflex.dev
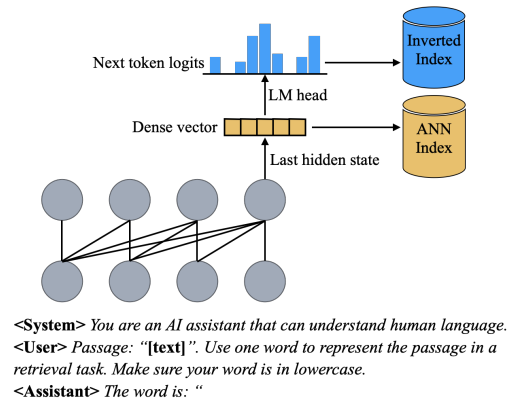

 是第
是第  条推理路径的可信度得分,
条推理路径的可信度得分, 是答案的长度,
是答案的长度, 和
和  分别是每一步解码中概率最高和第二高的词的概率。
分别是每一步解码中概率最高和第二高的词的概率。 repo_path
%cd $repo_path
!pip install -e .
if "pyserini" not in {pkg.key for pkg in pkg_resources.working_set}:
!pip install pyserini
if "torch" not in {pkg.key for pkg in pkg_resources.working_set}:
!pip install torch
if "faiss-cpu" not in {pkg.key for pkg in pkg_resources.working_set}:
!pip install faiss-cpu
except:
repo_path = '.'
if "dspy-ai" not in {pkg.key for pkg in pkg_resources.working_set}:
!pip install -U pip
!pip install dspy-ai
if repo_path not in sys.path:
sys.path.append(repo_path)
import dspy
repo_path
%cd $repo_path
!pip install -e .
if "pyserini" not in {pkg.key for pkg in pkg_resources.working_set}:
!pip install pyserini
if "torch" not in {pkg.key for pkg in pkg_resources.working_set}:
!pip install torch
if "faiss-cpu" not in {pkg.key for pkg in pkg_resources.working_set}:
!pip install faiss-cpu
except:
repo_path = '.'
if "dspy-ai" not in {pkg.key for pkg in pkg_resources.working_set}:
!pip install -U pip
!pip install dspy-ai
if repo_path not in sys.path:
sys.path.append(repo_path)
import dspy
 ,其中
,其中  表示节点集合,
表示节点集合, 表示边集合。为了确保图谱的唯一性和一致性,我们设定了两个约束条件:每个实体和关系都必须描述一个语义上独特的概念,并且集合中的每个元素都不应重复。
表示边集合。为了确保图谱的唯一性和一致性,我们设定了两个约束条件:每个实体和关系都必须描述一个语义上独特的概念,并且集合中的每个元素都不应重复。