近年来,大型语言模型(LLM)在自然语言处理领域取得了显著进展,尤其是在机器翻译方面展现出巨大潜力。然而,现有的方法往往无法达到监督神经机器翻译(NMT)系统的翻译质量。究其原因,可能是这些方法使用的简单提示无法充分利用 LLM 所具备的指令遵循能力。
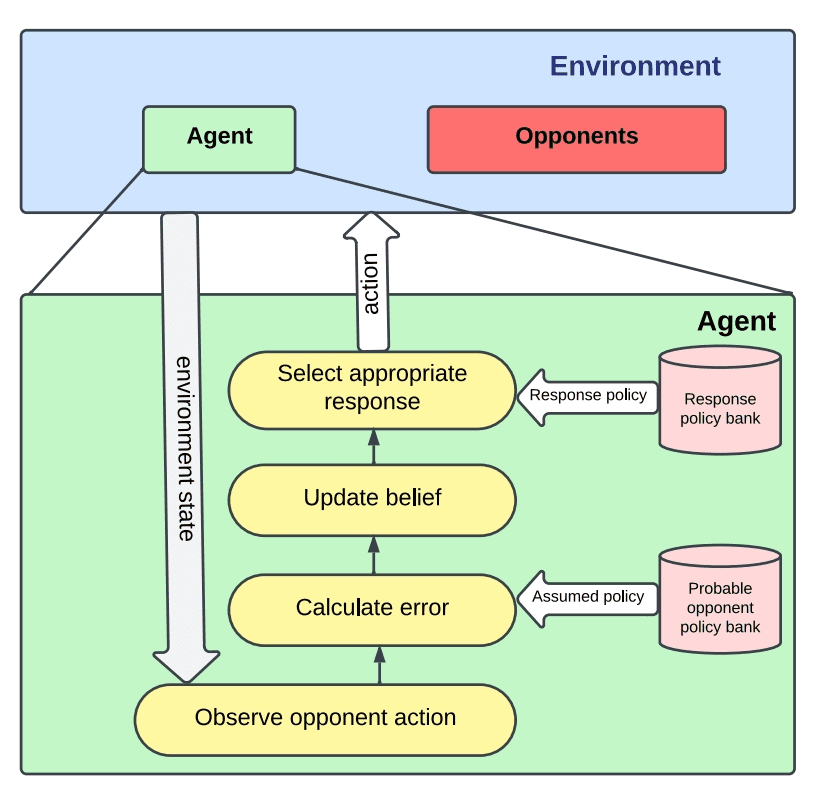
为了解决这一问题,本文介绍了一种名为 TASTE 的框架,其全称为“通过自我反思进行翻译”(Translating through Self-Reflection)。TASTE 框架通过两阶段推理过程,让 LLM 能够反思自己的翻译结果并进行改进。
TASTE 框架:两阶段推理,自我反思
TASTE 框架的核心是让 LLM 能够进行自我反思,这包含两个阶段的推理:
第一阶段:生成初步翻译并进行自我评估。 在这一阶段,LLM 被要求生成初步翻译,同时对这些翻译进行质量预测。这些初步翻译被称为“草稿”,其对应的质量预测可以是近似标签或精确分数。
第二阶段:根据评估结果对初步翻译进行细化。 在这一阶段,LLM 被要求根据预测的质量水平对草稿进行细化,最终生成经过改进的翻译结果。
整个过程类似于人类在执行任务时,会先进行初步尝试,然后根据结果进行反思和调整,最终完成任务。
多任务监督微调:赋能 LLM 自我反思能力
为了让 LLM 能够有效地执行整个反思翻译过程,研究人员对 LLM 进行了多任务监督微调(SFT)。多任务训练数据包含三个部分:
- 质量预测: LLM 被要求对给定的源句子生成翻译,并同时提供自我质量预测。质量预测任务包含两种形式:文本分类(TC)和质量评估(QE)。TC 要求预测“好”、“中等”或“差”等标签,而 QE 则要求预测 0 到 100 之间的整数分数。
- 基础翻译: 研究人员使用平行数据和标准化指令对 LLM 进行微调,用于多语言翻译任务,例如德语⇔英语和中文⇔英语。指令被简单地表述为“将[源语言]翻译成[目标语言]”。
- 草稿细化: LLM 被要求根据质量标签或分数对草稿进行细化,生成最终输出。
实验结果:TASTE 框架显著提升翻译质量
实验结果表明,TASTE 框架显著提升了 LLM 的翻译能力。在 WMT22 基准测试中的四个语言方向上,TASTE 框架的表现均优于现有方法。
- 两种质量预测方法(QE 和 TC)均取得了良好的效果, 表明两种方法都能有效地帮助 LLM 理解不同翻译之间的质量差异。
- 固定嵌入层训练方法(FixEmb)优于全参数训练方法(Full), 这可能是因为固定嵌入层可以有效地保留 LLM 的表达能力,避免训练数据中单词分布偏差带来的负面影响。
分析:TASTE 框架的优势
- LLM 在质量预测方面表现出色。 实验表明,LLM 能够准确地预测其生成的翻译的质量,为草稿细化任务提供可靠的参考。
- 草稿细化过程有效地提升了翻译质量。 通过比较第一阶段和第二阶段的翻译结果,研究人员发现,经过细化后的翻译结果的质量明显提高,并且减少了翻译中的幻觉现象。
- 质量标签在细化过程中起着至关重要的作用。 实验表明,质量标签可以帮助 LLM 根据实际翻译质量水平进行合理的调整,从而生成高质量的最终结果。
TASTE 框架的应用:自动后期编辑工具
TASTE 框架不仅可以作为单个 LLM 的有效推理框架,还可以作为自动后期编辑(APE)工具,用于改进其他翻译系统生成的翻译。实验表明,TASTE 框架能够有效地改进基线翻译系统的翻译质量,甚至超越了 TASTE 框架本身的翻译性能。
结论:TASTE 框架为机器翻译带来新突破
TASTE 框架通过让 LLM 进行自我反思,有效地提升了其翻译能力。该框架为机器翻译领域带来了新的突破,为未来机器翻译的发展提供了新的方向。
参考文献
- Wang, Y., Zeng, J., Liu, X., Meng, F., Zhou, J., & Zhang, M. (2023). TASTE: Teaching Large Language Models to Translate through Self-Reflection. arXiv preprint arXiv:2309.14148.
Q: 这篇论文试图解决什么问题?
A: 这篇论文提出的TASTE框架旨在解决大型语言模型(LLMs)在机器翻译任务中的表现与监督神经机器翻译(NMT)系统相比存在差距的问题。具体来说,现有方法未能产生与监督NMT系统相匹配的令人满意的翻译输出。这可能是因为现有方法中使用的简单提示无法充分利用LLMs获得的指令遵循能力。TASTE框架通过引入自我反思的过程,使得LLMs在翻译过程中能够生成初步翻译并同时进行自我评估,然后根据评估结果对初步翻译进行修正,从而提高翻译质量。
Q: 有哪些相关研究?
A: 相关研究主要分为两个方向:提示工程(Prompt Engineering)和指令调整(Instruction Tuning)。
- 提示工程:旨在设计适当的提示模板,引入先验知识或补充信息以支持推理过程。
- 基于词典的方法在提示中引入来自双语或多语词典的控制提示,以处理源句子中的生僻词。
- 通过自提示提取与翻译相关的知识,如主题等,以指导翻译过程。
- 研究者们通过提供更多相关和高质量的翻译示例来增强LLMs检索双语知识的能力,从而促进生成尽可能高质量的翻译。
- 指令调整:是一种有效的方法,用于增强LLMs遵循自然语言指令的能力,并在下游零样本任务中产生更符合人类偏好的输出。
- 通过使用有限数量的高质量监督指令对LLMs进行指令调整,可以在某些情况下取得显著的结果。
此外,还有一些研究提出了类似的反思过程,使用信心引导方法或多步推理来协助翻译过程,例如:
- 并行训练信心估计网络以预测生成翻译的信心水平。
- 引入第二遍解码器来润色初稿并生成最终输出。
- 将翻译过程分为多个阶段,并独立应用不同的连续提示以更好地将语言转换为翻译任务。
这些研究为TASTE方法提供了理论和实践基础,TASTE方法结合了指令调整和中间推理步骤的引入,以模仿人类自我反思机制,提高LLMs在机器翻译中的表现。
Q: 论文如何解决这个问题?
A: 论文通过提出TASTE(翻译通过自我反思)框架来解决这个问题。TASTE框架主要包含以下几个关键步骤:
- 两阶段推理过程:将LLMs的翻译过程分为两个阶段。在第一阶段,LLMs生成初步翻译并同时对这些翻译进行自我评估。在第二阶段,根据评估结果,LLMs对初步翻译进行修正。
- 自我评估:在第一阶段,LLMs在生成初步翻译的同时,需要对翻译的质量进行预测,可以是质量标签或具体分数。
- 修正初步翻译:在第二阶段,LLMs根据第一阶段的质量预测结果,对初步翻译进行适当的调整,以产生最终的翻译候选。
- 多任务训练集:为了使LLMs具备执行整个反思翻译过程的能力,作者使用多任务训练数据集对LLMs进行监督式微调(SFT),这包括基础翻译、质量预测和草稿润色任务。
- 质量预测的两种形式:在质量预测子任务中,LLMs可以采用文本分类(TC)形式,预测“好”、“中”或“差”的标签;或者采用质量估计(QE)形式,预测0到100之间的整数值。
- 草稿润色:在草稿润化子任务中,给定一个源句子和多个不同质量的候选翻译,LLMs根据质量标签或分数对草稿进行润色,以产生最终输出。
通过这种方法,TASTE框架能够有效地提高LLMs在机器翻译任务中的表现,使其翻译质量接近或达到监督神经机器翻译系统的水平。
Q: 论文做了哪些实验?
A: 论文中进行了一系列实验来验证TASTE方法的有效性,包括以下几个方面:
- 主实验:使用WMT验证集构建基础翻译任务的训练数据,并使用MTME多候选数据集构建质量预测和草稿润化任务的训练数据。在WMT22测试集上评估翻译性能,覆盖了新闻、社交、电子商务和对话等多个领域。
- 模型训练:使用了两种不同的训练策略,包括全参数调整(Full-Parameter Tuning)和固定嵌入层调整(Tuning with Fixed Embedding Layer),以比较它们在不同设置下的表现。
- 基线比较:与仅使用基础翻译数据集训练的LLMs(MT-(·)基线模型)以及WMT22的获胜者、NLLB-3.3B等其他模型进行了比较。
- 质量预测任务评估:评估了LLMs在质量预测任务上的表现,包括文本分类(TC)和质量估计(QE)两种形式,并与候选翻译的困惑度(PPL)与COMET分数的相关性进行了比较。
- 草稿润化过程分析:比较了初步翻译和润化后的翻译在COMET分数上的差异,并分析了不同质量标签的草稿在润化过程中的平均COMET分数提升。
- 未对齐翻译词(UTW)的测量:测量了在源句子和翻译之间的词对词对齐中未对齐的单词百分比,以评估草稿润化过程对减少幻觉(hallucinations)的影响。
- 质量标签的作用:通过修改质量标签的配置,分析了预测质量标签对润化过程的影响。
- 消融研究:进行了消融研究,以强调多任务训练集和提示设计的必要性。
- 与相关方法的比较:将TASTE方法与CoT(Chain-of-Thought)和ICL(In-Context Learning)方法进行了比较。
- TASTE作为自动后期编辑(APE)工具:探讨了TASTE是否可以作为自动后期编辑工具来评估和润化其他系统生成的翻译。
- 模型大小的影响:报告了不同大小的BLOOMZ模型在COMET和BLEU分数上的表现,以评估模型大小对TASTE方法的影响。
- 案例研究:展示了TASTE在中文到英文翻译方向的几个案例,包括初步翻译和润化翻译的对比。
这些实验结果表明,TASTE方法能够显著提高LLMs在机器翻译任务中的性能,并且具有在不同翻译方向上生成高质量翻译候选的能力。
Q: 有什么可以进一步探索的点?
A: 尽管TASTE框架在提升大型语言模型(LLMs)的翻译性能方面取得了显著成果,但仍有一些潜在的研究方向和探索点:
- 多语言能力深入研究:进一步探索和改进LLMs在不同语言对之间的翻译能力,特别是那些在训练数据中较少出现的语种。
- 计算成本优化:TASTE方法需要两个推理阶段,导致计算成本较高。研究如何通过加速方法(如量化和推测解码)来降低计算成本。
- 模型泛化能力:研究如何提高模型在未见数据和跨领域的泛化能力,减少对特定训练数据的依赖。
- 质量预测的准确性:尽管LLMs在质量预测上表现出色,但仍有提升空间。研究如何进一步提高质量预测的准确性和可靠性。
- 多任务学习策略:探索不同的多任务学习策略,以更有效地训练LLMs执行TASTE过程中涉及的多个子任务。
- 模型解释性:提高模型的解释性,以便更好地理解LLMs在自我反思过程中的决策和修正逻辑。
- 鲁棒性测试:对模型进行更严格的鲁棒性测试,包括对抗性攻击和异常输入的处理。
- 用户研究和反馈:进行用户研究,收集专业翻译人员对TASTE生成的翻译输出的反馈,以指导模型的进一步改进。
- 实时应用:研究如何将TASTE框架集成到实时翻译系统中,以及如何优化模型以满足实时翻译的需求。
- 跨领域适应性:研究模型在不同领域(如医疗、法律等专业领域)的适应性和定制化需求。
- 模型压缩和加速:探索模型压缩技术和加速策略,以便在资源受限的环境中部署TASTE框架。
- 伦理和偏见:研究LLMs在翻译过程中可能引入的伦理问题和偏见,并探索减少这些问题的方法。
这些探索点可以帮助研究者和开发者进一步提升TASTE框架的性能,同时也为LLMs在机器翻译任务中的应用提供了更广泛的视角。
Q: 总结一下论文的主要内容
A: 这篇论文提出了一个名为TASTE(通过自我反思进行翻译)的框架,旨在提高大型语言模型(LLMs)在机器翻译任务中的表现。以下是论文的主要内容总结:
- 问题识别:指出现有方法未能使LLMs在机器翻译任务中达到与监督神经机器翻译(NMT)系统相媲美的质量。
- TASTE框架:提出了一个包含两个推理阶段的自我反思过程,以增强LLMs的翻译能力。
- 第一阶段:LLMs生成初步翻译并同时进行自我评估。
- 第二阶段:根据自我评估结果,LLMs对初步翻译进行修正。
- 多任务训练:为了使LLMs具备执行整个反思翻译过程的能力,作者采用了多任务训练方法,包括基础翻译、质量预测和草稿润化任务。
- 实验设置:使用WMT验证集和MTME多候选数据集构建训练数据,并在WMT22测试集上评估翻译性能。
- 模型训练策略:对比了全参数调整和固定嵌入层调整两种训练策略。
- 实验结果:TASTE方法在多个语言对上均优于基线模型,显示出在提升翻译质量方面的有效性。
- 质量预测任务:评估了LLMs在质量预测任务上的表现,并证明了它们能够为自身生成的翻译做出准确的质量预测。
- 草稿润化分析:通过比较初步翻译和润化翻译的COMET分数,展示了草稿润化过程在提升翻译质量方面的重要作用。
- 消融研究:强调了多任务训练集和提示设计在TASTE方法中的重要性。
- 与相关方法比较:将TASTE与CoT和ICL方法进行了比较,证明了TASTE在翻译性能上的优越性。
- TASTE作为APE工具:探讨了TASTE作为自动后期编辑工具的潜力,用于改进其他翻译系统生成的翻译。
- 模型大小的影响:研究了模型大小对TASTE方法的影响,发现更大的模型在翻译性能上更为稳定和高效。
- 案例研究:提供了TASTE在实际翻译任务中的案例分析,展示了其在修正翻译错误和提升翻译质量方面的能力。
- 结论与局限性:总结了TASTE方法的有效性,并指出了其在不同翻译方向上性能不一致和计算成本较高等局限性。
- 未来工作:提出了未来可能的研究方向,包括提高模型泛化能力、优化计算成本、提高模型解释性等。
论文的代码和数据集已经开源,为进一步的研究和应用提供了便利。