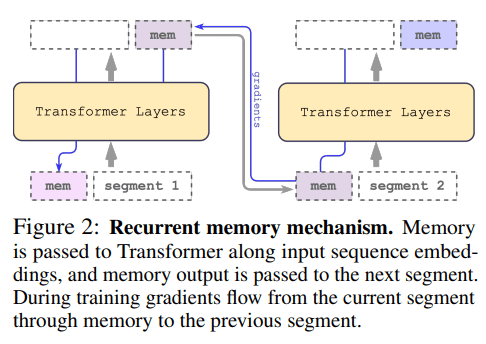
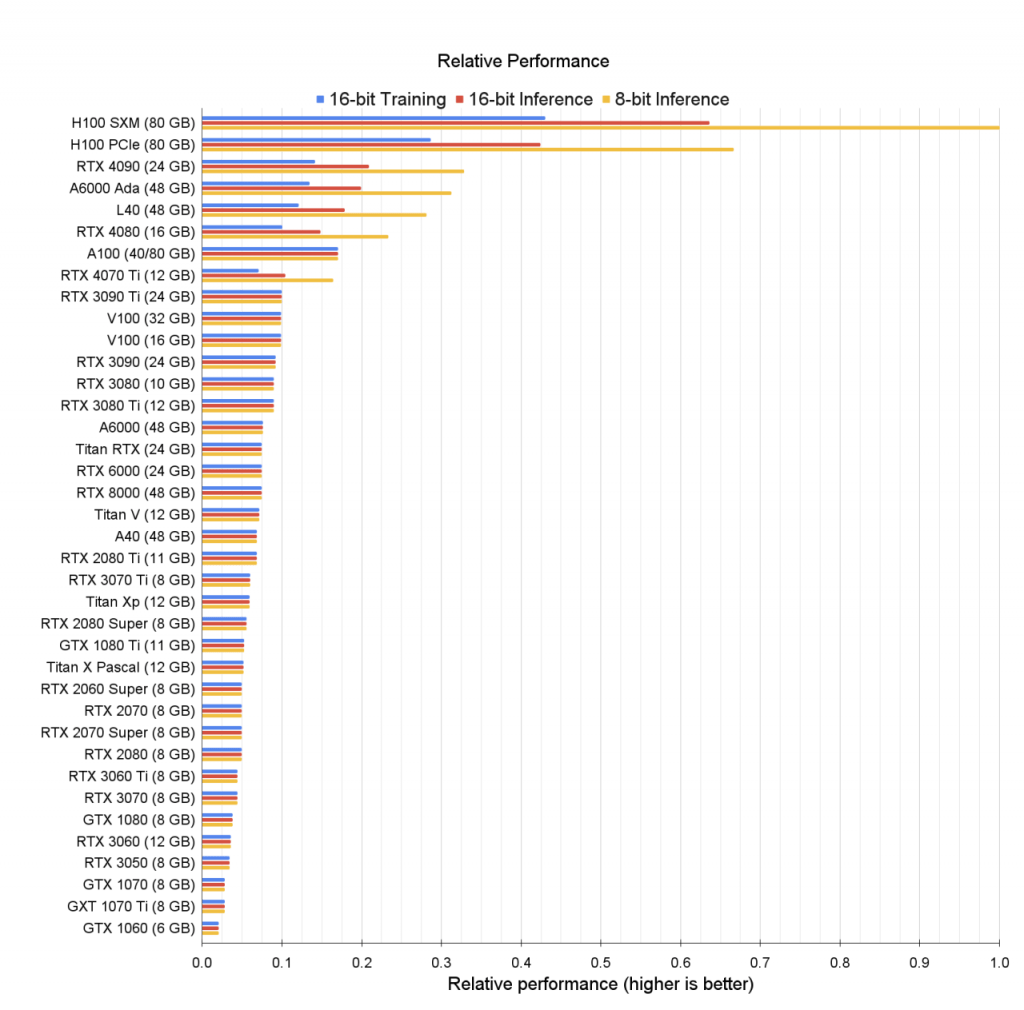
背景:目前开源的大语言模型对多语言支持不够理想,且大多数模型参数量不够大,无法商用。而SambaNova和Together联合开源的BLOOMChat是一个支持46种语言、参数达1760亿的开源可商用微调模型。
- BLOOMChat: BLOOMChat是在SambaNova的AI计算平台上训练的,目的是打造一个开源的、支持多语言、可商用的聊天LLM。实验表明BLOOMChat对多语言的支持明显优于其它开源模型。
- 数据和方法: BLOOMChat使用OpenChatKit、Dolly 2.0和OASST1等英语数据集进行BLOOM(176B)模型的微调。尽管只用英语数据微调,但BLOOMChat在其他语言的对话质量也得到明显提高。
- 实验效果: 让不同语言的native speaker评价BLOOMChat在其语言下的回答质量,BLOOMChat明显优于其他开源模型,但略逊于GPT-4。对BLOOMChat的回答进行评分,70%以上得到正确或可接受的评价。在WMT翻译任务上,BLOOMChat优于其他开源模型,但弱于GPT-4。
- BLOOMChat的局限性: 可能生成错误或无关信息,切换语言,重复内容,对代码或数学问题生成效果一般,可能产生不适当内容等。
BLOOMChat是一个完全开源、超千亿参数、专门针对多语言的聊天LLM。