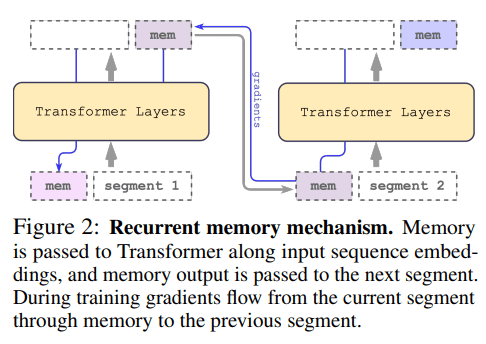
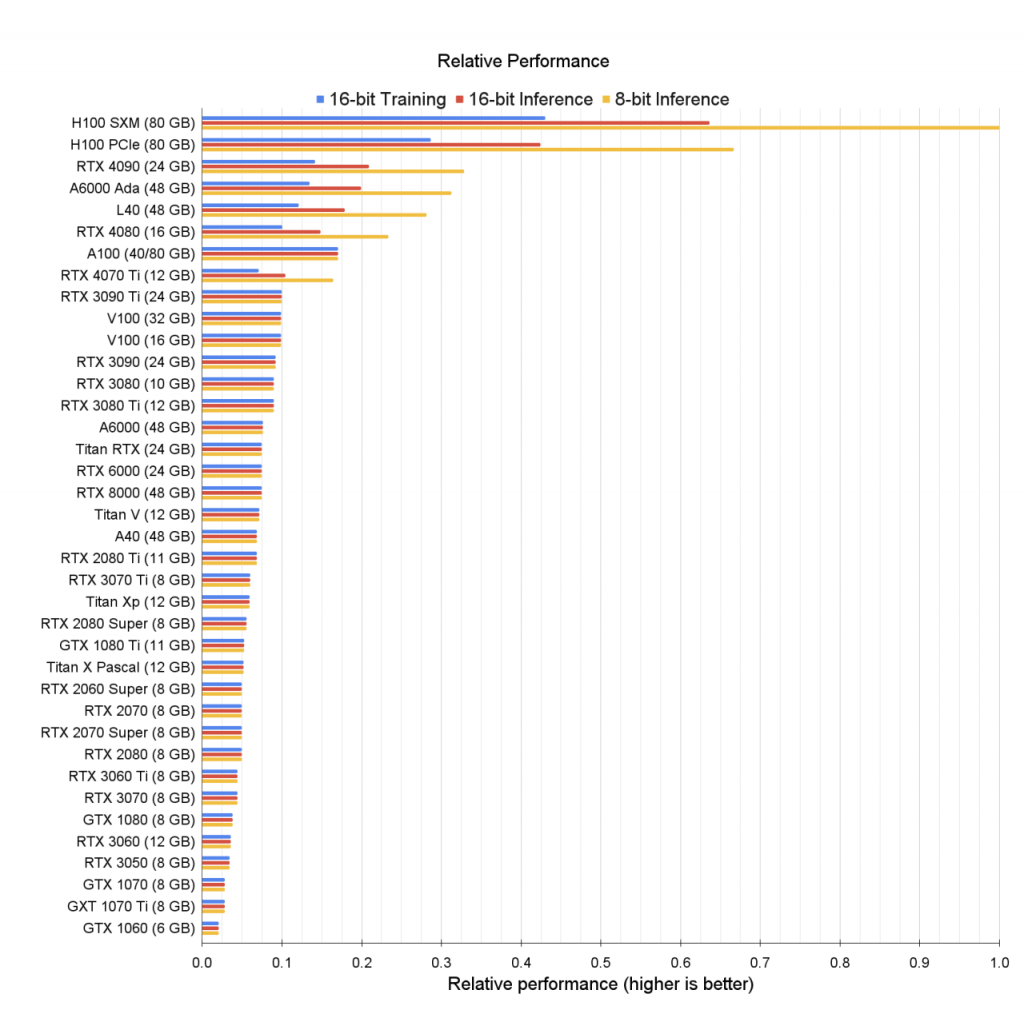
大型语言模型的涌现能力是一个黑箱,难以解释。尽管目前的研究已经开始揭示其中的一些机制,但我们仍然需要更深入的研究来更好地理解这些现象。
谷歌的这篇论文提供了有关语言模型的ICL行为如何随着模型参数而改变的重要见解,以及更大的语言模型具有将输入映射到许多类型的标签的涌现能力。这些发现表明,不同规模的语言模型在上下文学习能力方面存在着明显的差异。特别是,大型语言模型可以通过覆盖预先训练的语义知识和学习输入-标签映射来执行任务,而小型模型则更依赖于先验知识。
此外,研究者还发现,指令调优加强了语义先验知识的使用,而不是增加了学习输入-标签映射的能力。这些发现有助于我们更好地理解语言模型的涌现行为,同时也为未来的研究提供了方向,包括为什么这些现象会与模型参数规模相关等问题。
未来的研究可以探索不同类型的语言模型之间的差异,以及它们的涌现能力如何随着训练数据集的规模变化而改变。
此外,可以研究如何利用语义先验知识和输入-标签映射来设计更好的训练策略,以提高语言模型的性能。
最终,我们希望通过深入研究语言模型的涌现能力,能够更好地理解它们如何执行复杂的自然语言处理任务,并为未来的人工智能发展提供更好的基础。